| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/SE2020-4 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/SE2020-4/homework/11808 |
| 这个作业的目标 | 了解在哪种情况下可以使用构造数据类型—数组进行数据的处理,掌握用一维数组进行编程,掌握选择排序法和二分查找法 |
| 我的学号 | 20209194 |
2.1PTA作业
2.1.1 题目:
某医院想统计一下某项疾病的获得与否与年龄是否有关,需要对以前的诊断记录进行整理,按照0-18、19-35、36-60、61以上(含61)四个年龄段统计的患病人数占总患病人数的比例。
输入格式:
共2行,第一行为过往病人的数目n(0 < n <= 100),第二行为每个病人患病时的年龄。
输出格式:
按照0-18、19-35、36-60、61以上(含61)四个年龄段输出该段患病人数占总患病人数的比例,以百分比的形式输出,精确到小数点后两位。每个年龄段占一行,共四行。
2.1.2代码图片:

2.2.1题目:
在主函数中首先输入一个整数N(1<N<=100),然后再输入N个整数存入数组中,然后用选择排序法对数组中的N个元素从小到大排序,最后输出数组所有元素。
2.2.2代码图片:

2.2 题目:快速寻找满足条件的两个数
能否快速找出一个数组中的两个数字,让这两个数字之和等于一个给定的值,为了简化起见,我们假设这个数组中肯定存在至少一组符合要求的解。
解法一:采用穷举法,从数组中任意取出两个数字,计算两者之和是否为给定的数字。
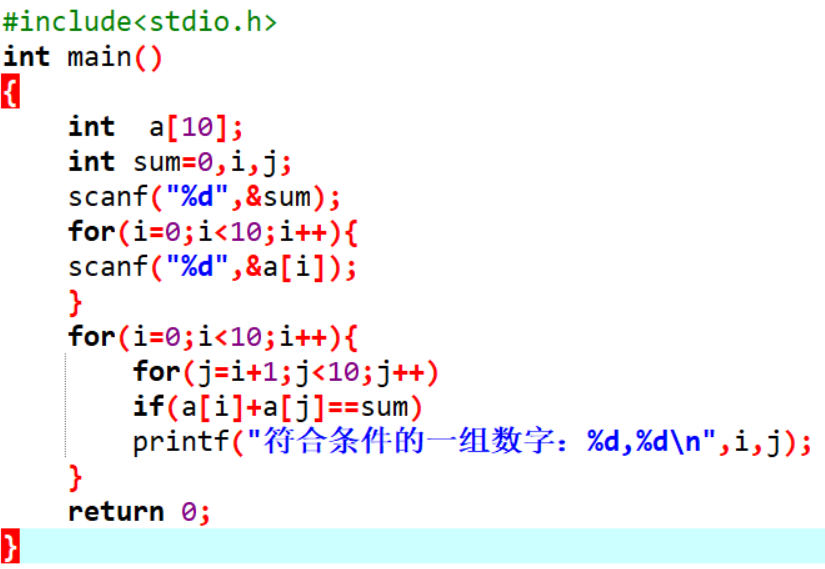
| 输入“和” | 输入“数组” | 输出结果 |
|---|---|---|
| 1 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:0,1 |
| 3 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:0,3 符合条件的一组数字:1,2 |
| 5 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:0,5 符合条件的一组数字:0,1符合条件的一组数字:1,4 符合条件的一组数字:2,3 |
解法二:对数组中的每个数字arr[i]都判别Sum-arr[i]是否在数组中。
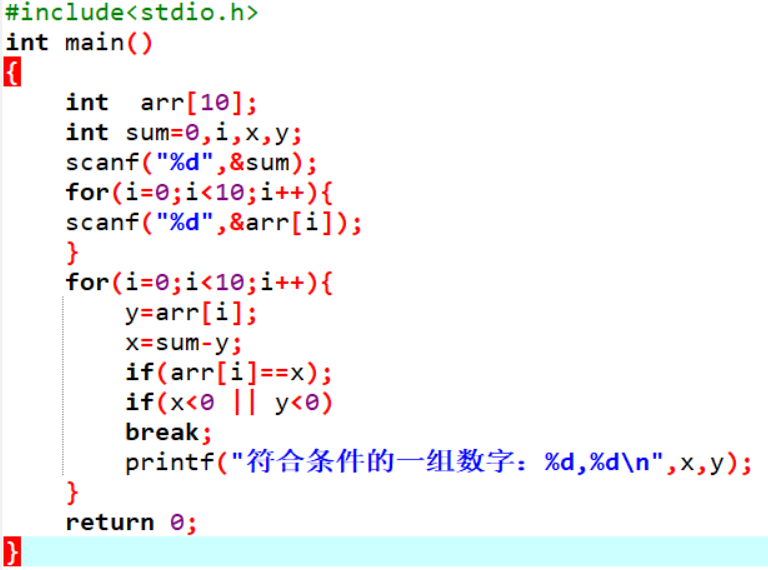
| 输入“和” | 输入“数组” | 输出结果 |
|---|---|---|
| 1 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:0,1 |
| 3 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:3,0 符合条件的一组数字:2,1 符合条件的一组数字:1,2 符合条件的一组数字:0,3 |
| 5 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:5,0 符合条件的一组数字:4,1 符合条件的一组数字:3,2 符合条件的一组数字:2,3 符合条件的一组数字:1,4 符合条件的一组数字:0,5 |
解法三:对数组进行排序,然后使用二分查找法针对arr[i]查找Sum-arr[i]。
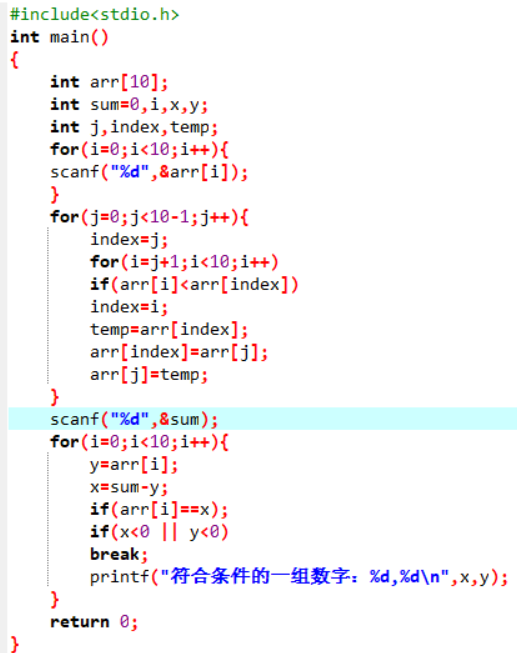
| 输入“和” | 输入“数组” | 输出结果 |
|---|---|---|
| 1 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:0,1 |
| 3 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:0,3 符合条件的一组数字:1,2 |
| 5 | 0 1 2 3 4 5 6 7 8 9 | 符合条件的一组数字:0,5 符合条件的一组数字:0,1符合条件的一组数字:1,4 符合条件的一组数字:2,3 |
请说明三种算法的区别是什么?你还可以给出更好的算法吗?
1.不断地添加代码进去,越来越长。第三个二分查找法只能针对有有序列表,且插入删除困难。第一种地穷举法是最简单最直接的算法。
2.不可以,我想不到!
2.3 请搜索有哪些排序算法,并用自己的理解对集中排序算法分别进行描述。
1 快速排序(QuickSort)
快速排序是一个就地排序,分而治之,大规模递归的算法。从本质上来说,它是归并排序的就地版本。快速排序比大部分排序算法都要快。尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。
2 归并排序(MergeSort)
归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。
3 堆排序(HeapSort)
堆排序适合于数据量非常大的场合(百万数据)。
堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。
4 冒泡排序(BubbleSort)
冒泡排序是最慢的排序算法。在实际运用中它是效率最低的算法。它通过一趟又一趟地比较数组中的每一个元素,使较大的数据下沉,较小的数据上升。
5 插入排序(InsertSort)
插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。
6 Shell排序(ShellSort)
Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。其中分组的合理性会对算法产生重要的影响。
Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。
7 交换排序(ExchangeSort)和选择排序(SelectSort)
都是交换方法的排序算法,只是排序算法发展的初级阶段,在实际中使用较少。
8 基数排序(RadixSort)
只能用于整数的排序,需要较多的存储空间。
2.4 请给出本周学习总结
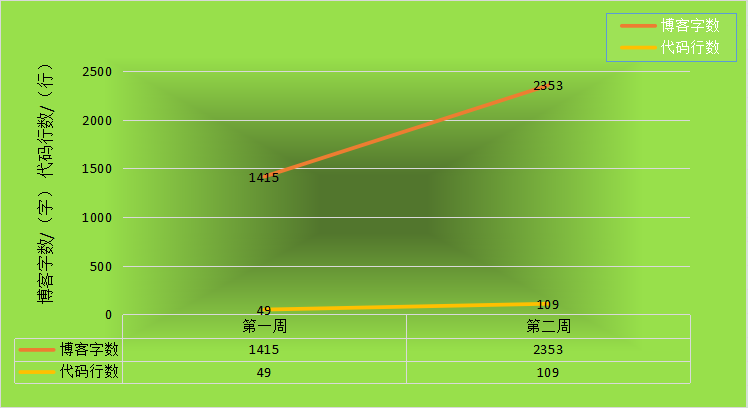
1.学习进度条
| 周/日期 | 这周所花的时间 | 代码行 | 学到的知识点简介 | 目前比较迷惑的问题 |
|---|---|---|---|---|
| 第一周 | 五天 | 49 | 文件的运用,回顾知识点 | 文件不会灵活运用 |
| 第二周 | 六天 | 109 | 使用构造数据类型—数组进行数据的处理,掌握用一维数组进行编程,掌握选择排序法和二分查找法 | 选择排序法和二分查找法不会用 |
2.累积代码行和博客字数
3.学习内容总结和感悟