PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation
个人总结
建议切入点
- 点云和体素的区别
- 点云为什么Unordered,怎样解决问题?
- 稀疏关键点,总结点云骨架,得到高度的缺失鲁棒性。
- 为什么可以作为统一的框架。
改进点
- 这里的特征要么是点的特征,要么是全局特征。缺少局部特征,肯定会导致局部的不精细,可以加入局部特征试试。
- 直接消费点云是一个好办法,可以减少认为设计的干扰,并且这里点特征比重很大,对于输入数据的异变(例如飞机上面再加一个推进器,会有比较好的分割性能),这个可不可以推广到其他地方?
- 这种统一框架的方法,可不可在其他方面以推广一下?
学习点
-
其中精简点云部分的代码和思路值得学习,这样可以提取到输入的骨架,有很好的鲁棒性和较低时间复杂度。
-
对于较大的仿射变换矩阵将其正交化降低变形能力,加入损失函数对其做正则提高收敛速度。
-
这个作者推广的思想就是 简单的方法就是最好的方法,我们可以在文章中的方法设计以及选择上面看到他的倾向。
Abstract
传统的点云因为其irregular format,研究人员为了方便的处理这种数据会将其转换为regular 3D voxel grids。然而这种方法会产生大量的无用数据和问题。在这篇文章我们设计了一种新颖的直接使用点云数据的神经网络他很好的考虑了输入点的排列不变性。PointNet是一个统一的网络结构,可以进行部件分割、语义分割、对象分类。PointNet简单还好用,这里我们会分析一下这个神经网络学到了什么?为什么对数据的扰动和丢失这么的鲁棒?
Introduction
在这个文章里面主要探索了3D几何深度学习能力的原因(点云和mesh),典型的卷积架构需要高度规则的数据输入格式,例如图像网格或者体素,以便执行权重共享和其他内核优化。由于点云或者mesh不是规则的数据格式,多数研究者经常将其转换为规则的3D体素网格或者多角度视图,再把他们feeding到网络里面。然而只要改变数据的格式就一定会产生损失并引入非自然的元素,对后面的程序造成不利的影响。出于这个原因我们决定直接使用点云作为输入,避免了以往网格结构的缺点。
然而,PointNet也需要尊重这样一个事实:点云只是点的集合,因此将其排列不变化,在计算过程中加入对称性是有必要的。还需要考虑刚体运动的进一步不变性。
PointNet是一个统一的架构,它直接使用点云作为输入and输出either类标签。该网络的基本架构十分简单,在最初的处理阶段,每个点的处理都是相同且独立的。在基本的setting中每个point被三个坐标表示((x,y,z)),额外的维度可以通过计算法线和其他局部或者全局特征来添加。
我们的方法是使用一个对称函数即最大池化函数。这个网络有效的选择了一些感兴趣的或者富有信息量的点在点狱中学习了一系列的优化函数。网络中最后部分的全连接层将这些学习到的最优值聚合成为如上所述的整个形状的全局描述或或用于预测每个点的标签。
我们的输入很容易应用到刚性或者仿射变换当中,因为每个点的变换都是独立的。因此我们可以添加一个空间转换网络,他尝试在点云处理数据之前规范数据,从而进一步改善结果。
我们对我们的方法提供了理论分析和实验评估。我们展示了我们的网络可以逼近任意连续的集合函数。更有趣的是我们的网络通过稀疏的关键点集来总结输入点云,根据可视化可以发现 这些点云粗略的对应了物体的骨架。这就说明了为什么我们的网络对于输入点的微小扰动以及通过点插入或者删除造成的破坏是高度鲁棒的。
在形状分类、部件分割、场景语义分割的一系列基准测试数据集上,我们通过实验将我们的PointNet与目前顶尖的基于多视图的体素表达的方法进行对比。本网络不仅速度更快,而且性能更好。我们的贡献主要如下:
- 我们设计了一种深度网络架构,适合用于消费无需的3D点云集合;
- 我们展示了如何训练这样的网络来执行3D形状分类、形状分割、和场景语义分割。
- 我们对该方法提供了彻底的实证和理论分析在他的稳定性和有效性上面。
- 我们说明了由网络中选定的神经元计算出的三位特征、并且对其表现做出了直观解释。
通过神经网络处理无序集合的问题是一个非常普遍和基本的问题,我们希望我们的想法也可以转移到其他领域
Related Work
点云的特征:点云大多数存在的特征都是人们为了某个任务而手工制作的。点特征经常被编码为某些统计特性并设计为针对某些变换不变的点。这些变换通常被分为固有的或外在的。他们也可以被分为局部特征和全局特征。对于一个特定的任务,找到最优的特征组合并非易事。
在3D数据上的深度学习
3D数据有很多种流行的表示方法,也导致产生了多种的学习方法。Volumetric CNNs:将3D卷积神经网络应用于体素化形状的先驱。然而,稀疏矩阵和3D卷积的高额计算成本限制很大。FPNN and Vote3D提出了处理稀疏问题的特殊方法,然而他们的操作依然建立在稀疏体积上,这种方法面临着处理非常大的点云的挑战。CNNs:它尝试将3D点云或者形状渲染为2D图像,然后应用2D卷积网络对他们进行分类。由于设计良好的CNNs,该方法在形状和分类检索任务中取得了卓越的性能。然而这个网络属于针对性质的,将其扩展到场景理解或者其他3D任务就不太合适了。Spectral CNNs:一些最新的工作在mesh上使用谱域CNNs,然而这些方法目前仅限于流形网格,它扩展到非流形网络的的办法不明确。Feature-based DNNs:首先将3D数据转换为矢量,通过提取传统的形状特征然后利用全连接层去分类这个形状。但是我们认为该模型收到特征提取能力的限制。
无序集的深度学习
从数据结构的角度去看,点云是一个无序的向量集合。深度学习的大部分工作都集中在规则的数据表示上像是序列(用于语音和语言)、图像和体积(视频等3D数据),但点云在深度学习方面的工作并不是很多。
最近这些人Oriol Vinyals et al也注意到了这个问题,他们使用富有注意力机制的read-process-write网络去消费无序输入数据集,并且表明他们的网络具有对数字进行排序的能力。然而,由于他们的网络聚焦于NLP和泛型集合上,因此他缺乏在集合上的几何应用。
Problem Statement
我们设计的深度学习框架可以直接消费无序的点集作为输入。点云表示为一系列3D的点({P_i|i=1,dots,n})其中每个点是其((x,y,z))坐标的向量加上额外的特征通过,如颜色、法线等。为了简单明了,除非另有说明,否则我们限制只是用((x,y,z))坐标作为点的通过。
在目标分类的任务当中,输入点云要么直接从形状中采样,要么预先从点云中分割。我们提出的深度网络输出所有这k个候选类的k个分数。对于语义分割,可以输入一个三维场景的字体及逆行目标区域分割。我们的模型将会输出一个(n*m)的分数,对于n个point和m个语义分类。
PointNet架构,上面的图片描述的就是PointNet的架构。分类网络使用(n)个点作为输入,进行输入变换和特征变换,通过最大池化层聚合特征。输出是对(k)个类的分类。分割网络是对分类网络的一个扩展,他链接全局和局部特征和每个点的分数。
4 Deep Learning on Point Sets
我们网络的结构是被点集的特性所激发出来的。
4.1 点集的特性
我们的输入是来自与欧几里得空间的子集,他有三个特性:
- 无序:这个东西也不像图像,体素啥的。点云是没有特定顺序的点的集合。简单点说就是,我们设计的网络如果输入是(n)个点的话,那么这(n)个点在进行(N!)次排列组合之后,每次输入网络得到的输入都是一致的。
- 点之间的相互关系:点与点来自一个有距离的空间。这意味着这些点不是孤立的,彼此之间是由一定关系的,相邻的点一般情况下构成一个有意义的子集。所以,模型需要能够从附近的点捕捉局部结构,以及局部结构之间组合的关系。
- 变形不变性:作为一个几何物体,在点集变形的情况下学习到的表征应该是不变的。例如一起旋转和平移点集,不应该改变该点集的类别,也不应该改变点集的分割。
4.2 PointNet架构
我们完整的架构可以在上图看到,其中分割和分类网络共享了很大一部分的结构。
我们的网络有三个关键的模块:1. 最大池化层作为一个对称函数去聚合所有点的信息。2.局部和全局信息的组合结构。3. 对输入点和点特征进行对其的两个联合对齐网络。
我们将会在下面讨论这些选择的原因。
解决无序输入的对称函数:为了让模型对输入排列不敏感,可以得到一致的输出我们有三个办法去解决这个问题:
- 将输入按照某个顺序进行排序,从而让每次的输入顺序保持一致。
- 把输入数据放到RNN里面锻炼一下,通过各种排列来增加训练数据。
- 用一个简单的对称函数来聚合每个点的信息。在这里对称函数接收(n)个向量作为输入,然后输出一个船新的向量,该输出对于输入的顺序是不敏感的。例如(+)和( imes)操作就是对称的函数。
第一个解决方法,虽然听着好像是特别简单的解决方案但是在高维空间里面(三维以上的空间),是没有符合这个需求的排序方法的。它可以很容易的用矛盾法求出。下面开始证明:假设符合上述需求的排序方法是存在的话,他定义了高维空间和一维实线之间的双射映射。不难看出,要求排序次序稳定,相当于要求该图在维度减少的时候保持空间的一致性,这在一般情况下是无法实现的任务。因此我们无法使用排序来解决这个问题,并且因为无序问题的持续存在,网络很难学习到从输入到输出的一致映射。
第二个结局方案,将点集视为一个序列信号,希望通过使用随机排列的序列来训练(RNN),使(RNN)对输入顺序保持不变。但是RNN对小长度序列的输入排序具有较好的鲁棒性,但很难扩展到数千个输入元素,而这是点集的常见大小,在后面可以看到(fig.5)中(LSTM)的效果挺不错的, 我感觉用Transformer替代一下,可以得到更快的更好的训练效果。
第三个解决方法:(f({x_1,dots,x_n})approx g(h(x_1),dots,h(x_n)))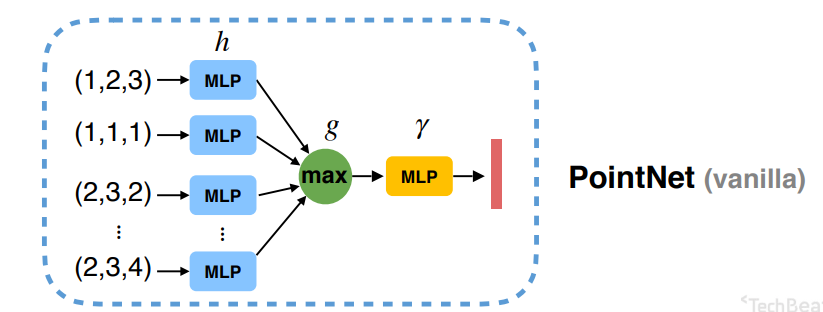
如上图所示,我们使用最大池化层(g)去做对称函数,通过这种办法使输入对顺序不敏感。
但是因为Max Pooling这种方法会造成信息丢失,所以前面我们使用参数共享的MLP将输入数据的维度扩大,得到数据冗余,降低损失率。在理论上通过多层感知机+最大池化函数去拟合任意的几何都是可以无限逼近的。
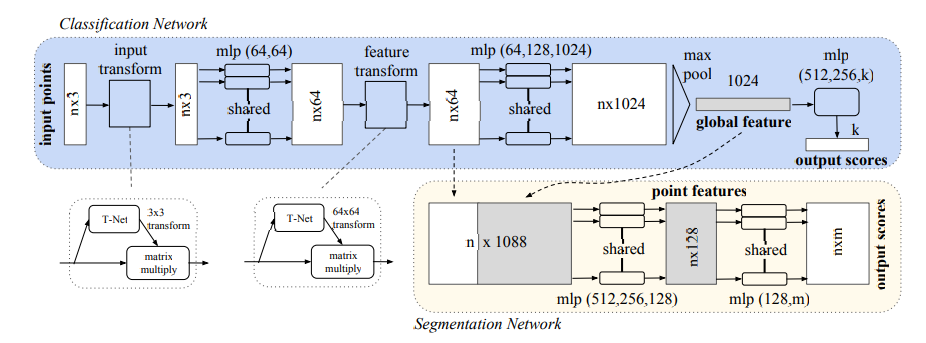
在上面我们在Max Pooling之后得到的结果很容易可以对目标进行分类。但是对于分割而言这些数据是不够的,对于分割而言,我们需要对每个点进行分类,所以我们需要每个点的信息,需要结合局部和全局的知识,才可以做到比较好的分割效果。我们可以通过一种简单而高效的方法去解决这个问题。
我们的方法可以在图二看到,在计算出全局点云特征向量(n imes 1024),之后我们将其和每个点的特征拼接在一起,让每一个点知道他们的局部特征和整个点云的全局特征。使特征点可以同时感受全局和局部的特征信息。
联合对齐网络:如果点云经过一定的刚性几何变化,则点云的语义分割也应该是不变的。
一个普遍的解决方案使在提取特征之前将所有输入集对齐到一个规范空间,就像Jaderberg这些人做的空间变换网络,通过仿射变换和双线性插值和神经网络的方法去做2D图像的矫正,推广到3D上面一样。
与上面的方法相比,因为我们直接使用点云作为输入带来的优势,我们可以使用更简单的方法去解决这个问题.我们使用T-Net网络去预测一个仿射变换矩阵,然后将该矩阵应用到输入点的坐标上得到矫正之后的矩阵。(color{red}{实际上就是Jaderberg这个人发明的二维的空间变换网络,作者将其扩展到三维.})
由于点云的性质,是一群离散的点的集合,实现空间网络变换可以更加的简单,只需要训练出来变换矩阵,然后和原参数做矩阵乘法就可以了,相当于实现了原论文中的第一步,就可以达到相同的效果。
性质区别:
- 二维图像中,我们求出变换矩阵之后,在原图上面做乘法的时候,得到像素的映射变换位置可能是带小数点数据,我们需要对其进行插值,找到合适的整数位置和该点的像素值, 但是在点云之中由于像素点的位置原本就是小数的(一般情况下将位置归一化到
-1~1之间,所以我们只需要进行第一步即可)。
具体的代码如下, 其中的inut transform和feature transform长得和pointNet的代码差不多。
Tensorflow版本,T-Net
import tensorflow as tf
import numpy as np
import sys
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, '../utils'))
import tf_util
def input_transform_net(point_cloud, is_training, bn_decay=None, K=3):
""" Input (XYZ) Transform Net, input is BxNx3 gray image
Return:
Transformation matrix of size 3xK """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value
input_image = tf.expand_dims(point_cloud, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv2', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv3', bn_decay=bn_decay)
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='tmaxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='tfc1', bn_decay=bn_decay)
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='tfc2', bn_decay=bn_decay)
with tf.variable_scope('transform_XYZ') as sc:
assert(K==3)
weights = tf.get_variable('weights', [256, 3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases = tf.get_variable('biases', [3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases += tf.constant([1,0,0,0,1,0,0,0,1], dtype=tf.float32)
transform = tf.matmul(net, weights)
transform = tf.nn.bias_add(transform, biases)
transform = tf.reshape(transform, [batch_size, 3, K])
return transform
def feature_transform_net(inputs, is_training, bn_decay=None, K=64):
""" Feature Transform Net, input is BxNx1xK
Return:
Transformation matrix of size KxK """
batch_size = inputs.get_shape()[0].value
num_point = inputs.get_shape()[1].value
net = tf_util.conv2d(inputs, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv2', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv3', bn_decay=bn_decay)
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='tmaxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='tfc1', bn_decay=bn_decay)
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='tfc2', bn_decay=bn_decay)
with tf.variable_scope('transform_feat') as sc:
weights = tf.get_variable('weights', [256, K*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases = tf.get_variable('biases', [K*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases += tf.constant(np.eye(K).flatten(), dtype=tf.float32)
transform = tf.matmul(net, weights)
transform = tf.nn.bias_add(transform, biases)
transform = tf.reshape(transform, [batch_size, K, K])
return transform
Pytorch版本,T-Net
class STN3d(nn.Module):
def __init__(self):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.array([1,0,0,0,1,0,0,0,1]).astype(np.float32))).view(1,9).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
class STNkd(nn.Module):
def __init__(self, k=64):
super(STNkd, self).__init__()
self.conv1 = torch.nn.Conv1d(k, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k*k)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.k = k
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.eye(self.k).flatten().astype(np.float32))).view(1,self.k*self.k).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.k, self.k)
return x
代码解析
模型数据加载部分
farthest_point_sample:是否将数据进行函数最远点采样,因为我们点云中的点的数量是很大的,我们可以使用最远点采样的方法去实现保留点云骨架,减少计算量,并且对于最后的效果也不会有影响。例如第一个点云文件有10000个点,我们将其降低到1024,可将降低时间复杂度。
farthest_point_sample
def farthest_point_sample(point, npoint):
N, D = point.shape
xyz = point[:, :3]
centroids = np.zeros((npoint,))
distance = np.ones((N,)) * 1e10
farthest = np.random.randint(0, N)
for i in range(npoint):
centroids[i] = farthest
centroid = xyz[farthest, :]
dist = np.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = np.argmax(distance, -1)
point = point[centroids.astype(np.int32)]
return point
pc_normalize:将经过上面采样之后,得到的点计算它们的平均值,得到中心点,并且将其最大半径归一化到1.
ModelNetDataLoader.py
import numpy as np
import warnings
import os
from torch.utils.data import Dataset
warnings.filterwarnings('ignore')
# ModelNet40:用来训练物体形状分类(40个)。训练集有9843个点云、测试集有2468个点云。
# 点云归一化,以centroid为中心,半径为1
def pc_normalize(pc):
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc**2, axis=1)))
pc = pc / m
return pc
# farthest_point_sample函数完成最远点采样:
# 从一个输入点云中按照所需要的点的个数npoint采样出足够多的点,
# 并且点与点之间的距离要足够远。
# 返回结果是npoint个采样点在原始点云中的索引。
def farthest_point_sample(point, npoint):
"""
Input:
xyz: pointcloud data, [N, D]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [npoint, D]
"""
N, D = point.shape
xyz = point[:,:3]
centroids = np.zeros((npoint,))
distance = np.ones((N,)) * 1e10
farthest = np.random.randint(0, N)
for i in range(npoint):
centroids[i] = farthest
centroid = xyz[farthest, :]
dist = np.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = np.argmax(distance, -1)
point = point[centroids.astype(np.int32)]
return point
class ModelNetDataLoader(Dataset):
def __init__(self, root, npoint=1024, split='train', uniform=False, normal_channel=True, cache_size=15000):
self.root = root
self.npoints = npoint
self.uniform = uniform
self.catfile = os.path.join(self.root, 'modelnet40_shape_names.txt')
self.cat = [line.rstrip() for line in open(self.catfile)]
self.classes = dict(zip(self.cat, range(len(self.cat))))
self.normal_channel = normal_channel
shape_ids = {}
# rstrip() 删除 string 字符串末尾的指定字符(默认为空格)
shape_ids['train'] = [line.rstrip() for line in open(os.path.join(self.root, 'modelnet40_train.txt'))]
shape_ids['test'] = [line.rstrip() for line in open(os.path.join(self.root, 'modelnet40_test.txt'))]
assert (split == 'train' or split == 'test')
shape_names = ['_'.join(x.split('_')[0:-1]) for x in shape_ids[split]]
# list of (shape_name, shape_txt_file_path) tuple
self.datapath = [(shape_names[i], os.path.join(self.root, shape_names[i], shape_ids[split][i]) + '.txt') for i
in range(len(shape_ids[split]))]
print('The size of %s data is %d'%(split,len(self.datapath)))
self.cache_size = cache_size # how many data points to cache in memory
self.cache = {} # from index to (point_set, cls) tuple
def __len__(self):
return len(self.datapath)
def _get_item(self, index):
if index in self.cache:
point_set, cls = self.cache[index]
else:
fn = self.datapath[index]
cls = self.classes[self.datapath[index][0]]
cls = np.array([cls]).astype(np.int32)
point_set = np.loadtxt(fn[1], delimiter=',').astype(np.float32)
# 数据集采样npoints个点送入网络
if self.uniform:
point_set = farthest_point_sample(point_set, self.npoints)
else:
point_set = point_set[0:self.npoints,:]
point_set[:, 0:3] = pc_normalize(point_set[:, 0:3])
if not self.normal_channel:
point_set = point_set[:, 0:3]
if len(self.cache) < self.cache_size:
self.cache[index] = (point_set, cls)
return point_set, cls
def __getitem__(self, index):
return self._get_item(index)
if __name__ == '__main__':
import torch
data = ModelNetDataLoader('/data/modelnet40_normal_resampled/',split='train', uniform=False, normal_channel=True,)
DataLoader = torch.utils.data.DataLoader(data, batch_size=12, shuffle=True)
for point,label in DataLoader:
print(point.shape)
print(label.shape)
模型文件
,得到的点计算它们的平均值,得到中心点,并且将其最大半径归
需要注意的是,total_loss = loss + mat_diff_loss * self.mat_diff_loss_scale这里的损失函数加入了特征映射矩阵,(color{red}{我的猜测是为了抑制**映射矩阵的大小**,防止梯度爆炸。})
point_cls.py
import torch.nn as nn
import torch.utils.data
import torch.nn.functional as F
from pointnet import PointNetEncoder, feature_transform_reguliarzer
class get_model(nn.Module):
def __init__(self, k=40, normal_channel=True):
super(get_model, self).__init__()
print("*"*30)
if normal_channel:
channel = 6
else:
channel = 3
self.feat = PointNetEncoder(global_feat=True, feature_transform=True, channel=channel)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k)
self.dropout = nn.Dropout(p=0.4)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
def forward(self, x):
print("-"*100)
x, trans, trans_feat = self.feat(x)
x = F.relu(self.bn1(self.fc1(x)))
x = F.relu(self.bn2(self.dropout(self.fc2(x))))
x = self.fc3(x)
x = F.log_softmax(x, dim=1) # 计算对数概率
return x, trans_feat
class get_loss(torch.nn.Module):
def __init__(self, mat_diff_loss_scale=0.001):
super(get_loss, self).__init__()
self.mat_diff_loss_scale = mat_diff_loss_scale
def forward(self, pred, target, trans_feat):
# NLLLoss的输入是一个对数概率向量和一个目标标签. 它不会计算对数概率.
# 适合网络的最后一层是log_softmax.
# 损失函数 nn.CrossEntropyLoss()与NLLLoss()相同, 唯一的不同是它去做softmax.
loss = F.nll_loss(pred, target) # 分类损失
mat_diff_loss = feature_transform_reguliarzer(trans_feat) #特征变换正则化损失
# 总的损失函数
total_loss = loss + mat_diff_loss * self.mat_diff_loss_scale
return total_loss
模型训练
在这里我们选用pointnet_cls模型,对点云进行分类,点云的点采样数量是1024,优化器使用Adam.
在epoch开始,第一个batch进入之后,我们首要做的是做点云的再次增强(之前读入数据的时候我们已经做了两次数据优化。),
-
provider.random_point_dropout: 进一步减少点云数量它使用的算法是:将在数据载入部分已经用最大距离算法精简到的1024 个数据,再次随机精简,将那些倒霉的需要被精简掉的数据的值覆盖为该batch的首个值。每个点云还是有1024个值,只不过我们将其重复了一部分. -
random_scale_point_cloud: 将点云的所有点,随机缩放,范围在[0.85,1.25)。也就是整个物体的放大和缩小。 -
shift_point_cloud: Batch_size内的每一行元素x,y,z都加上一行随机值范围在[-0.1,0.1]内的[offset_x, offset_y, offset_z]。
train_cls.py
from data_utils.ModelNetDataLoader import ModelNetDataLoader
import argparse # python的命令行解析的模块,内置于python,不需要安装
import numpy as np
import os
import torch
import datetime
import logging # 处理日志的模块
from pathlib import Path
from tqdm import tqdm
import sys
import provider
import importlib
import shutil
BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # '/home/bai/Pointnet_Pointnet2_pytorch'
ROOT_DIR = BASE_DIR # '/home/bai/Pointnet_Pointnet2_pytorch'
sys.path.append(os.path.join(ROOT_DIR, 'models'))
def parse_args(): # 解析命令行参数
'''PARAMETERS'''
# 建立参数解析对象
parser = argparse.ArgumentParser('PointNet')
# 添加属性:给xx实例增加一个aa属性,如 xx.add_argument("aa")
parser.add_argument('--batch_size', type=int, default=24, help='batch size in training [default: 24]')
parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')
parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training [default: 200]')
parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training [default: 0.001]')
parser.add_argument('--gpu', type=str, default='0', help='specify gpu device [default: 0]')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number [default: 1024]')
parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training [default: Adam]')
parser.add_argument('--log_dir', type=str, default=None, help='experiment root')
parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate [default: 1e-4]')
parser.add_argument('--normal', action='store_true', default=False, help='Whether to use normal information [default: False]')
# 采用parser对象的parse_args函数获取解析的参数
return parser.parse_args()
def test(model, loader, num_class=40):
mean_correct = []
class_acc = np.zeros((num_class,3))
for j, data in tqdm(enumerate(loader), total=len(loader)):
points, target = data
target = target[:, 0]
points = points.transpose(2, 1)
points, target = points.cuda(), target.cuda()
classifier = model.eval()
pred, _ = classifier(points)
pred_choice = pred.data.max(1)[1]
for cat in np.unique(target.cpu()):
classacc = pred_choice[target==cat].eq(target[target==cat].long().data).cpu().sum()
class_acc[cat,0]+= classacc.item()/float(points[target==cat].size()[0])
class_acc[cat,1]+=1
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item()/float(points.size()[0]))
class_acc[:,2] = class_acc[:,0]/ class_acc[:,1]
class_acc = np.mean(class_acc[:,2])
instance_acc = np.mean(mean_correct)
return instance_acc, class_acc
def main(args):
def log_string(str):
logger.info(str)
print(str)
'''HYPER PARAMETER'''
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
'''CREATE DIR'''
timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
experiment_dir = Path('./log/')
experiment_dir.mkdir(exist_ok=True)
experiment_dir = experiment_dir.joinpath('classification')
experiment_dir.mkdir(exist_ok=True)
if args.log_dir is None:
experiment_dir = experiment_dir.joinpath(timestr)
else:
experiment_dir = experiment_dir.joinpath(args.log_dir)
# 'log/classification/pointnet2_cls_msg'
experiment_dir.mkdir(exist_ok=True)
checkpoints_dir = experiment_dir.joinpath('checkpoints/')
# 'log/classification/pointnet2_cls_msg/checkpoints'
checkpoints_dir.mkdir(exist_ok=True)
log_dir = experiment_dir.joinpath('logs/')
# 'log/classification/pointnet2_cls_msg/logs'
log_dir.mkdir(exist_ok=True)
'''LOG'''
args = parse_args()
logger = logging.getLogger("Model")
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
log_string('PARAMETER ...')
log_string(args)
'''DATA LOADING'''
log_string('Load dataset ...')
DATA_PATH = 'data/modelnet40_normal_resampled/'
TRAIN_DATASET = ModelNetDataLoader(root=DATA_PATH, npoint=args.num_point, split='train',
normal_channel=args.normal)
# 训练集:9843个样本
TEST_DATASET = ModelNetDataLoader(root=DATA_PATH, npoint=args.num_point, split='test',
normal_channel=args.normal)
# 测试集:2468个样本
trainDataLoader = torch.utils.data.DataLoader(TRAIN_DATASET, batch_size=args.batch_size, shuffle=True, num_workers=4)
testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=args.batch_size, shuffle=False, num_workers=4)
'''MODEL LOADING'''
# 分类类别数目
num_class = 40
# import network module
MODEL = importlib.import_module(args.model)
shutil.copy('./models/%s.py' % args.model, str(experiment_dir))
shutil.copy('./models/pointnet_util.py', str(experiment_dir))
classifier = MODEL.get_model(num_class,normal_channel=args.normal).cuda()
criterion = MODEL.get_loss().cuda()
try:
checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')
start_epoch = checkpoint['epoch']
classifier.load_state_dict(checkpoint['model_state_dict'])
log_string('Use pretrain model')
except:
log_string('No existing model, starting training from scratch...')
start_epoch = 0
if args.optimizer == 'Adam':
optimizer = torch.optim.Adam(
classifier.parameters(),
lr=args.learning_rate,
betas=(0.9, 0.999),
eps=1e-08,
weight_decay=args.decay_rate
)
else:
optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)
global_epoch = 0
global_step = 0
best_instance_acc = 0.0
best_class_acc = 0.0
mean_correct = []
'''TRANING'''
logger.info('Start training...')
for epoch in range(start_epoch,args.epoch):
log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
# optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,
# 但也不是绝对的,可以根据具体的需求来做。
# 只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr进行调整。
scheduler.step()
for batch_id, data in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader), smoothing=0.9):
points, target = data # data: (B,1024,6)
points = points.data.numpy()
# 点云预处理;数据增强
points = provider.random_point_dropout(points)
points[:,:, 0:3] = provider.random_scale_point_cloud(points[:,:, 0:3]) # (B,1024,6)
points[:,:, 0:3] = provider.shift_point_cloud(points[:,:, 0:3])
points = torch.Tensor(points)
target = target[:, 0] # B
points = points.transpose(2, 1) # (B,6,1024)
points, target = points.cuda(), target.cuda() # target shape: B
optimizer.zero_grad()
# 训练分类器
classifier = classifier.train()
pred, trans_feat = classifier(points) # pred:(B,40); trans_feat: (B, 1024,1)
loss = criterion(pred, target.long(), trans_feat)
pred_choice = pred.data.max(1)[1] # pre_choice shape: B
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item() / float(points.size()[0])) # 分母为B
loss.backward() # 反向传播(梯度计算)
optimizer.step() # 更新权重
global_step += 1
train_instance_acc = np.mean(mean_correct)
log_string('Train Instance Accuracy: %f' % train_instance_acc)
# 性能评估
with torch.no_grad():
instance_acc, class_acc = test(classifier.eval(), testDataLoader)
if (instance_acc >= best_instance_acc):
best_instance_acc = instance_acc
best_epoch = epoch + 1
if (class_acc >= best_class_acc):
best_class_acc = class_acc
log_string('Test Instance Accuracy: %f, Class Accuracy: %f'% (instance_acc, class_acc))
log_string('Best Instance Accuracy: %f, Class Accuracy: %f'% (best_instance_acc, best_class_acc))
if (instance_acc >= best_instance_acc):
logger.info('Save model...')
savepath = str(checkpoints_dir) + '/best_model.pth'
log_string('Saving at %s'% savepath)
state = {
'epoch': best_epoch,
'instance_acc': instance_acc,
'class_acc': class_acc,
'model_state_dict': classifier.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
# 保存网络模型
torch.save(state, savepath)
global_epoch += 1
logger.info('End of training...')
if __name__ == '__main__':
args = parse_args()
main(args)
T-Net:继续解析,我们通过T-Net预测一个仿射变换矩阵,并将该矩阵直接bmm在输入点的坐标上,相当于x,y,z直接乘一个(3 imes 3)的矩阵,相当于对每个点进行仿射变换,具体可以参考二维的STN。那边是(2 imes 3)d额矩阵,这边是三维的所以使用(3 imes 3)。在对特征进行(3 imes 3)的仿射变换参数训练之后我们的到一个(3 imes 3)的矩阵。
后面我们进行(64 imes 64)的特征对齐训练,因为其中参数较多,训练优化比较困难,我们在训练损失里面加入了一个正则化项total_loss = loss + 0.0001 * self.mat_diff_loss_scale,其中的mat_diff_loss_scale是图2中特征变换得到的那个(64 imes 64)的矩阵放到下面这个函数中计算之后得到的值。文中公式为:
(L_{reg}=||I-AA^T||^2_F)
- 提要:在训练出来变换矩阵之后,我们都将其加上一个(E)矩阵,然后得到的才是变换矩阵。将其加一个单位矩阵的目的(color{red}{猜测其目的可能是为了抑制仿射变换矩阵对于实际坐标的影响不要过大。}) 在损失函数中加入仿射变换矩阵的效果文中讲是让优化变得更加的稳定。我的意思是会不会类似(weight_decay)这种东西,降低仿射变换矩阵的值,让原本的点云变形不要太剧烈???? 应该是这样的。
def feature_transform_reguliarzer(trans):
d = trans.size()[1]
I = torch.eye(d)[None, :, :] # torch.eye(n, m=None, out=None) 返回一个2维张量,对角线位置全1,其它位置全0
if trans.is_cuda:
I = I.cuda()
# 正则化损失函数
loss = torch.mean(torch.norm(torch.bmm(trans, trans.transpose(2, 1) - I), dim=(1, 2)))
return loss
定理证明
- 定理证明这种东西好像有点太难了,而且这个文章的定理证明也比较多,所以这里就只尝试证明神经网络对集合函数的无限逼近。
在该种方法下,输入集合的一个很小的扰动基本上对输出是不会有影响的,例如在一个飞机点云文件中
出现了一个小鸟的点云,该网络有能力将小鸟的点云数据很好的屏蔽掉。(color{red}{这里也说明了PointNet存在的一个缺点,就是没有考虑到局部特征}),在这里我们先不讨论他的缺点,想直接看缺点以及改进方法的可以点缺点传送门。
哈哈, 我直接他妈证明失败!屌不屌。。。。
文中的证明之后的结论是,在我们的最大池化层如果有足够的神经元,我们的神经网络就可以无限逼近输入的数据。
,
实验部分
- 实现分为四个部分,首先我们证明了
PointNet可以用于多个3D识别任务。其次,我们提供了详尽的实验来验证我们的网络设计细节。然后我们提供了可视化网络学习的内容,分析了时间和空间复杂度。
多任务框架
- 在这一节,我们开始展示我们的网络如何做
3D物体的分类、物体部分分割和场景语义分割,(color{green}{尽管文章用的是一种全新的数据表示输入,但是它可以在几个任务的基准测试当中可以实现相当甚至更好的性能。})
3D物体分类
在上面文章的讲解中,我们都是以分类作为基础进行讲解的,所以这里就简简单单的讲一下。
我们的网络学习了全局特征,我们可以使用该特征进行分类。在这里我们选择ModelNet40作为benchmark数据集,使用15年Zhirong Wu等人的论文3D ShapeNets: A deep representation for volumetric shapes作为基准程序开始对比。
其中有个操作需要再提一下, 例如数据集中的第一个飞机类的第一个文件来讲,其中有10000万个点,在直接消费点云的模型里面,我们可以使用最大距离采样法去将其减少到1024,下面可以展示一下,那个程序的效果。


可以发现,在进行点的精简之后,其主要骨架没有缺失,这样对精度没有影响。
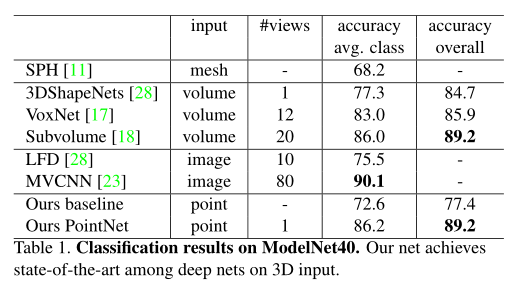
- 可以看到
pointnet的结果是明显优于之前的经典方案的。 - 但是在每个类的准确率的平均值上低于
多视角CNN,其原因应该是缺少局部特征。
物体部件分割
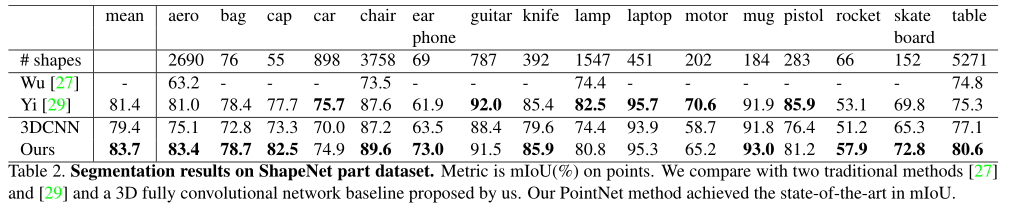
其中的评价指标(mIoU=frac{1}{k+1}sum^k_{i=0}frac{p_{ii}}{sum^k_{j=0}p_{ij}+sum^k_{j=0}p_{ji}-p_{ii}}),一般是对每一类的(IOU)计算之后累加,再进行平均,得到的就是基于全局的评价。
- true positive( 真正 (p_{ii}) )
- false positive( 假正 (p_{ij}) )
- true negative ( 真负 (p_{jj}) )
- false negative ( 假负 (p_{ji}) )

这里需要注意的一点是模型对于部分输入如上图左边的点云分割的效果也非常好,在使用Blensor Kinect Simulator在6个视角生成不完全点云的情况下,精度只下降了(5.3\%)
场景语义分割
该网络模型可以很容易的扩展到场景语义分割上面,直接让点标签成为语义对象类就行(直接点的标签是部件类标签)。
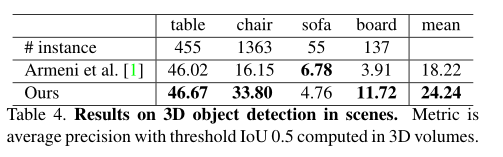
需要注意的是这里使用了K-折交叉验证,感觉精度会因为这个有所提高。
补充
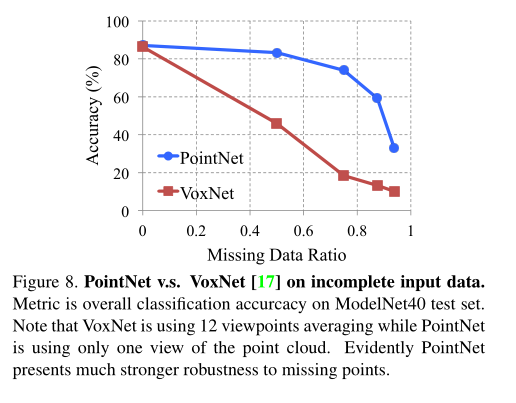
看了一下,VoxNet它是将一个点云文件,通过不同的方式生成12个体素文件,然后作为输入开始卷积。上图可以看出,PointNet对于点云缺失具有很好的鲁棒性。具体原因应该是精简点云的功劳,通过学习骨架去总结形状的原因。