作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
前言:在猫眼电影上看到《何以为家》电影的评分比较高,于是爬取用户的部分评论进行分析。
一、获取数据的url接口
1、在电脑网页版上可以看到只有看到10条的热门评论,数据过于少无法进行分析。

2、使用手机网页版进行获取url接口,但是发现只能加载到1000条评论。1000条后
的评论无法加载,也返回不了数据,于是只能爬取1000条数据进行分析。
根据url的规律,和返回的json数据,可知每个url返回15条评论的数据,
offset的值是指从第几条评论开始返回。

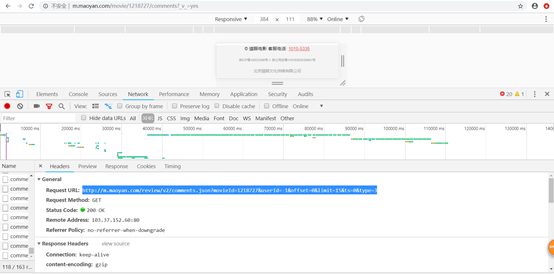
3、在网上找到了一个旧的url接口,上面的返回的json数据还有城市,而新的url没有,
于是就使用旧的url。
http://m.maoyan.com/mmdb/comments/movie/1218727.json?_v_=yes&offset=?&startTime=0
二、设置合理的user-agent,模拟成真实的浏览器去提取内容。
#设置合理的user-agent,爬取数据函数
def getData(url): headers =[ {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36','Cookie': '_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'}, { 'User-Agent': 'Mozilla / 5.0(Linux;Android 6.0; Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 73.0 .3683.103Mobile Safari / 537.36','Cookie':'_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'}, {'User-Agent': 'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10','Cookie':'_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'} ] # proxies = [{'https': 'https://120.83.111.194:9999','http':'http://14.20.235.120:808'},{"http": "http://119.131.90.115:9797", # "https": "https://14.20.235.96:9797"}] get=requests.get(url, headers=headers[random.randint(0,2)]); get.encoding = 'utf-8' return get
三、对爬取的数据进行处理,生成。
#数据处理函数
def dataProcess(data):
data = json.loads(data.text)['cmts']
allData = []
for i in data:
dataList = {}
dataList['id'] = i['id']
dataList['nickName'] = i['nickName']
dataList['cityName'] = i['cityName'] if 'cityName' in i else '' # 处理cityName不存在的情况
dataList['content'] = i['content'].replace('
', ' ', 10) # 处理评论内容换行的情况
dataList['score'] = i['score']
dataList['startTime'] = i['startTime']
if "gender" in i:
dataList['gendar'] = i["gender"]
else:
dataList['gendar'] = i["gender"] = 0
allData.append(dataList)
return allData
四、把爬取的数据生成csv文件和保存到数据库。
代码:
#处理后的数据保存为csv文件
pd.Series(allData)
newsdf=pd.DataFrame(allData)
newsdf.to_csv('news.csv',encoding='utf-8')
#把csv文件保存到sqlite
newsdf = pd.read_csv('news.csv')
with sqlite3.connect('sqlitetest.sqlite') as db:
newsdf.to_sql('data',con = db)
截图:
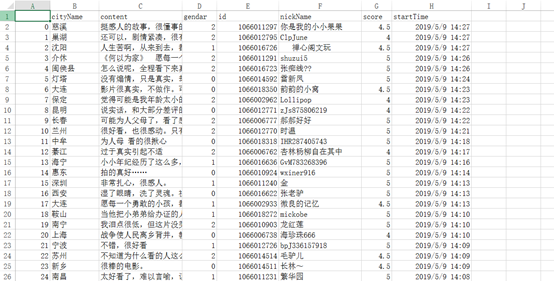
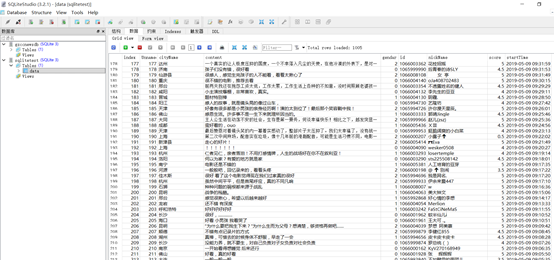
最后只爬取到了1004条的数据,不知道是不是猫眼电影对评论数据的获取进行了限制,加载
到一定数据量就无法加载了。
四、数据可视化分析。
4.1、评论者性别分析
代码:
# 评论者性别分布可视化
def sex(gender):
from pyecharts import Pie
list_num = []
print(gendar)
list_num.append(gender.count(0)) # 未知
print(gender.count(0))
list_num.append(gender.count(1)) # 男
list_num.append(gender.count(2)) # 女
attr = ["未知","男","女"]
pie = Pie("性别饼图")
pie.add("", attr, list_num,is_label_show=True)
pie.render("sex_pie.html")
截图:

这部电影除去未知性别的,在已知性别的评论者女性的比例比较多,说明这部电影女性的
爱好者比较多。
4.2、评论者评分等级分析
代码:
# 评论者评分等级环状饼图
def scoreProcess(score):
from pyecharts import Pie
list_num = []
list_num.append(scores.count(0))
list_num.append(scores.count(0.5))
list_num.append(scores.count(1))
list_num.append(scores.count(1.5))
list_num.append(scores.count(2))
list_num.append(scores.count(2.5))
list_num.append(scores.count(3))
list_num.append(scores.count(3.5))
list_num.append(scores.count(4))
list_num.append(scores.count(4.5))
list_num.append(scores.count(5))
attr = ["0", "0.5", "1","1.5","2","2.5", "3", "3.5","4","4.5","5"]
pie = Pie("评分等级环状饼图",title_pos="center")
pie.add("", attr, list_num, is_label_show=True,
label_text_color=None,
radius=[40, 75],
legend_orient="vertical",
legend_pos="left",
legend_top="100px",
center=[50,60]
)
pie.render("score_pie.html")
截图。
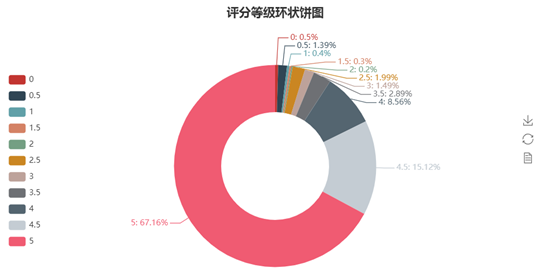
根据上面分饼图可得满分的占了67%左右,4.5分以上占了82%左右,可知这部电影的
评价十分高,应该是非常好看的,值得去观看。
4.2、观众分布地图分析
根据网上资料自从 v0.3.2 开始,pyecharts 将不再自带地图 js 文件。根据需要可以安装对应的地图包。
全球国家地图: echarts-countries-pypkg : 世界地图和 213 个国家,包括中国地图
中国省级地图: echarts-china-provinces-pypkg:23 个省,5 个自治区
中国市级地图: echarts-china-cities-pypkg :370 个中国城市
中国县区级地图: echarts-china-counties-pypkg :2882 个中国县·区
中国区域地图: echarts-china-misc-pypkg:11 个中国区域地图,比如华南、华北
代码:
# 观众分布图
def cityProcess(citysTotal):
from pyecharts import Geo
geo =Geo("《何以为家》观众分布", title_color='#fff', title_pos='center',
width=1200,height = 600, background_color = '#404a95')
attr, value = geo.cast(citysTotal)
geo.add("", attr, value, is_visualmap=True, visual_range=[0, 100], visual_text_color='#fff',
legend_pos = 'right', is_geo_effect_show = True, maptype='china',
symbol_size=10)
geo.render("city_geo.html")
截图:

可以看出观众都是集中在沿海附近的城市,这也说这些城市相对于中国西北地区更为发达
一些。尤其是北京、上海、广州、深圳的观众是最多的。这些地区的消费水平上也相对更
高一些。人口也会计较的聚集。
四、完整代码。
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
import sqlite3
import pandas as pd
import time
import pandas
import random
import json
#设置合理的user-agent,爬取数据函数
def getData(url):
headers =[
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36','Cookie': '_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'},
{ 'User-Agent': 'Mozilla / 5.0(Linux;Android 6.0; Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 73.0 .3683.103Mobile Safari / 537.36','Cookie':'_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'},
{'User-Agent': 'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10','Cookie':'_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'}
]
# proxies = [{'https': 'https://120.83.111.194:9999','http':'http://14.20.235.120:808'},{"http": "http://119.131.90.115:9797",
# "https": "https://14.20.235.96:9797"}]
get=requests.get(url, headers=headers[random.randint(0,2)]);
get.encoding = 'utf-8'
return get
#数据处理函数
def dataProcess(data):
data = json.loads(data.text)['cmts']
allData = []
for i in data:
dataList = {}
dataList['id'] = i['id']
dataList['nickName'] = i['nickName']
dataList['cityName'] = i['cityName'] if 'cityName' in i else '' # 处理cityName不存在的情况
dataList['content'] = i['content'].replace('
', ' ', 10) # 处理评论内容换行的情况
dataList['score'] = i['score']
dataList['startTime'] = i['startTime']
if "gender" in i:
dataList['gendar'] = i["gender"]
else:
dataList['gendar'] = i["gender"] = 0
allData.append(dataList)
return allData
allData=[]
for i in range(67):
get=getData('http://m.maoyan.com/mmdb/comments/movie/1218727.json?_v_=yes&offset={}&startTime=0'.format(i*15))
allData.extend(dataProcess(get))
#处理后的数据保存为csv文件
pd.Series(allData)
newsdf=pd.DataFrame(allData)
newsdf.to_csv('news.csv',encoding='utf-8')
# #把csv文件保存到sqlite
# newsdf = pd.read_csv('news.csv')
# with sqlite3.connect('sqlitetest.sqlite') as db:
# newsdf.to_sql('data',con = db)
# 评论者性别分布可视化
def sexProcess(gender):
from pyecharts import Pie
list_num = []
list_num.append(gender.count(0)) # 未知
list_num.append(gender.count(1)) # 男
list_num.append(gender.count(2)) # 女
attr = ["未知","男","女"]
pie = Pie("性别饼图",title_pos="center")
pie.add("", attr, list_num,is_label_show=True)
pie.render("sex_pie.html")
gendar=[]
for i in allData:
gendar.append(i['gendar'])
sexProcess(gendar)
# 评论者评分等级环状饼图
def scoreProcess(scores):
from pyecharts import Pie
list_num = []
list_num.append(scores.count(0))
list_num.append(scores.count(0.5))
list_num.append(scores.count(1))
list_num.append(scores.count(1.5))
list_num.append(scores.count(2))
list_num.append(scores.count(2.5))
list_num.append(scores.count(3))
list_num.append(scores.count(3.5))
list_num.append(scores.count(4))
list_num.append(scores.count(4.5))
list_num.append(scores.count(5))
attr = ["0", "0.5", "1","1.5","2","2.5", "3", "3.5","4","4.5","5"]
pie = Pie("评分等级环状饼图",title_pos="center")
pie.add("", attr, list_num, is_label_show=True,
label_text_color=None,
radius=[40, 75],
legend_orient="vertical",
legend_pos="left",
legend_top="100px",
center=[50,60]
)
pie.render("score_pie.html")
scores=[]
for i in allData:
scores.append(i['score'])
scoreProcess(scores)
# 观众分布图
def cityProcess(citysTotal):
from pyecharts import Geo
geo =Geo("《何以为家》观众分布", title_color='#fff', title_pos='center',
width=1200,height = 600, background_color = '#404a95')
attr, value = geo.cast(citysTotal)
geo.add("", attr, value, is_visualmap=True, visual_range=[0, 100], visual_text_color='#fff',
legend_pos = 'right', is_geo_effect_show = True, maptype='china',
symbol_size=10)
geo.render("city_geo.html")
# 城市名称的处理
citysTotal={}
coordinatesJson = pd.read_json('city_coordinates.json',encoding='utf-8')
for i in allData:
for j in coordinatesJson:
if str(i['cityName']) in str(j) :
if str(j) not in citysTotal:
citysTotal[str(j)]=1
else:
citysTotal[str(j)]=citysTotal[str(j)]+1
break
cityProcess(citysTotal)