“云时代架构”经典文章阅读感想八
(支持百万连接的系统应该如何设计其高并发架构)
连接共分为四个步骤:1建立连接、2.发送请求、3.返回响应、4.断开连接。系统通信就是通过建立连接进行系统之间的通信。随着系统的越来越多的信息需求、用户越来越多、数据越来越大,所需要的连接也就越来越大。这篇主要讲解的便是通过Kafka应对大量客户端的连接。即支持百万连接的解决方法。
连接分为短连接和长连接两种:
短连接就是每次发送请求时都需要建立连接,每次发送结束之后都需要断开连接,在不断地连接、断开的操作中一定会产生大量的资源消耗,因此长连接便未了解决这一问题,长连接就是在返回响应之后并不断开连接,在之后的发送请求以及返回响应时并不会再次需要建立连接。
短连接
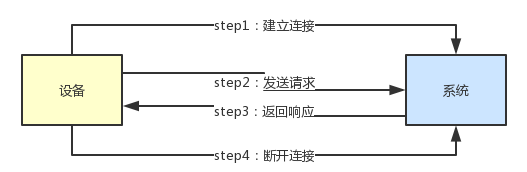
长连接

但是长连接会带来因为需要维持与设备之间的连接所需要的线程,随着需要连接的设备越来越多所带来的消耗也是巨大的。
实际上,对于大名鼎鼎的消息系统Kafka来说,Kafka [1] 是一种高吞吐量 [2] 的分布式发布订阅消息系统,有如下特性:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能;高吞吐量即使是非常普通的硬件Kafka也可以支持每秒数百万的消息;支持通过Kafka服务器和消费机集群来分区消息。他也是会面对同样的问题,因为他需要应对大量的客户端连接。
有很多生产者和消费者都要跟Kafka建立类似上面的长连接,然后基于一个连接,一直不停的通信,生产者需要连接,向Kafka发送一个链接,然后通过kafka也要通过这个链接不停的返回给生产者,消费者也需要通过一个连接不停的从Kafka获取数据,Kafka需要通过这个连接不停的返回数据给消费者.
即kafka扮演一个中间节点,负责生产者与消费者之间的连接。
然而kafka并非是万能的,生产者、消费者少点还好,如果生产者、消费者有很多,kafka也不可能去维护如此多的线程。这是不现实的,因为线程是昂贵的资源,不可能在集群里使用那么多的线程。
针对这一问题,Kafka提出了Reactor多路复用这一解决方案,Kafka采用是Reactor多路复用模型这一架构策略.简单来说,就是提供一个acceptor线程,基于底层操作系统的支持,实现连接请求监听。如果有某个设备发送了建立连接的请求过来,那么那个线程就把这个建立好的连接交给processor线程。每个processor线程会被分配N多个连接,一个线程就可以负责维持N多个连接,他同样会基于底层操作系统的支持监听N多连接的请求。果某个连接发送了请求过来,那么这个processor线程就会把请求放到一个请求队列里去。着后台有一个线程池,这个线程池里有工作线程,会从请求队列里获取请求,处理请求,接着将请求对应的响应放到每个processor线程对应的一个响应队列里去。最后,processor线程会把自己的响应队列里的响应发送回给客户端。
为什么可以实现百万线程的连接,就是processor线程是一个维护等多个线程,在操作系统的特殊机制的支持,一个processor监听多个连接请求。而且那个processor线程仅仅是接收请求和发送响应,所有的请求都会入队列排队,交给后台线程池来处理。在这种模式下,每台机器有限的线程数量可以抗住大量的连接。
因此实际上我们在设计这种支撑大量连接的系统的时候,完全可以参考这种架构,设计成多路复用的模式,用几十个线程处理成千上万个连接,最终实现百万连接的处理架构。
在实现百万连接中使用的多路复用的解决方案,以及提供一个排队队列,接受和处理分离这些思想其实很早就有,只是不能灵活的运用他们,因此在今后的实践工作中不仅仅是学习编程、更重要的是拓宽自己的知识面,深入了解原理。