(一)在eclipse中新建一个java项目,就普通建一个java项目就可以,然后添加hadoop的依赖包
(二)打开后选择add Exernal jars
添加hadoop的包,包的位置如下(/usr/local/hadoop/是我的hadoop路径)
/usr/local/hadoop/share/hadoop/common下所有jar包
/usr/local/hadoop/share/hadoop/common/lib下所有jar包
/usr/local/hadoop/share/hadoop/hdfs下所有jar包
/usr/local/hadoop/share/hadoop/hdfs/lib下所有jar包

(三)现在就可以开始编码了但是一定要先把hadoop打开,命令是在你的hadoop路径下./sbin/start-all.sh,输入jps可以验证是否打开了hadoop
(1)判断hdfs上是否存在某文件代码如下
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFS_Judge_exist {
public static void main(String[] args){
try{
String fileName = "input/test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))){
System.out.println("文件存在");
}else{
System.out.println("文件不存在");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
(2)往HDFS中插入某一个文件代码如下
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
public class HDFS_insert {
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
byte[] buff = "Hello world".getBytes(); // 要写入的内容
String filename = "input/test1.txt"; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println("Create:"+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
(3)查询hdfs的文件内容
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class HDFS_readFile {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("input/test.txt");
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
String content1 = d.readLine(); //读取文件一行
System.out.println(content1);
String content2 = d.readLine(); //读取文件一行
System.out.println(content2);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
(四)下面介绍如何把Java应用程序生成JAR包,部署到Hadoop平台上运行。首先,在Hadoop安装目录下新建一个名称为myapp的目录,存放jar包。命令:kdir myapp
(1)点击eclipse导航条中File-Export

(2)点击next
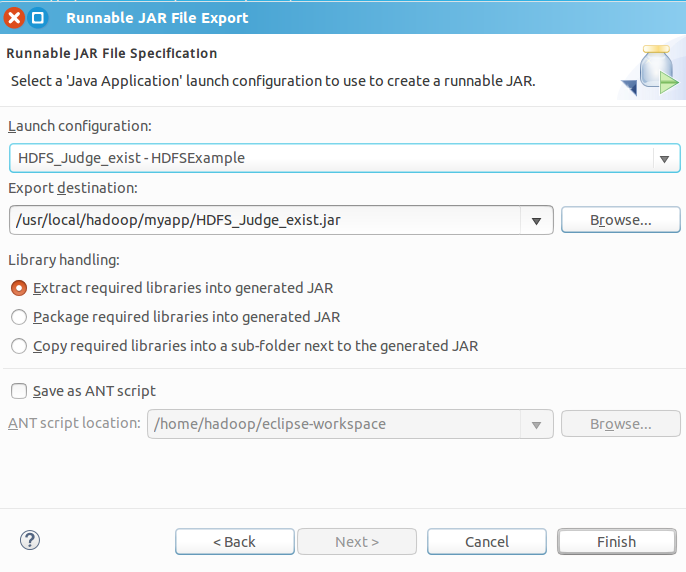
第一个Launch Configuration用于设置生成的JAR包被部署启动时运行的主类,点击三角形在下拉列表中选择就好了。
第二个是让我们填入包存放的路径,选择我们刚才新建的myapp路径
(3)点击finish
点击finish的过程中会出现报错,不要管他直接点确认,哪两个错误提示不影响后面操作
(4)在hadoop的路径下输入:./bin/hadoop jar ./myapp/HDFS_Judge_exist.jar
这条命令是指我们要使用hadoop,通过jar包的方式,jar包的位置在当前目录下/myapp/HDFS_Judge_exist.jar的地方
