Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
而Tire树是很典型的用空间换时间的一种算法,为什么这么说呢?我在后面会做详尽解释,现在我们还是慢慢来。
Tire树的三大特点:
- 根数的节点不包含任何字符,除根节点以外节点有且只包含一个字符。
- 从根节点到某一节点,构成一个字符串,如果标记为红色,表示该字符串存在,反之不存在。
- 每个节点所包含的子节点都不相同。(在同一等级的节点上不存在相同的字符);
Tire树之怎样的一种模型:
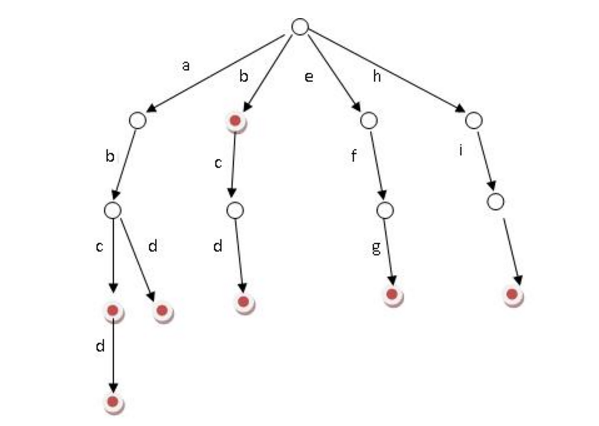
看到这图之后,你是否还有疑惑,如果是!没事,现在请你想象一下,某处有一个点,里面什么都没有。然后假设你有26个不同的点,你需要将这些点一个一个的接在第一个点的下方。接完后,你又得到26*26个点,你先在又需要把这些带你接到上26个点下,又要保证在同一个节点下的点不能够相同。好,你很累了,但是你又被要求在接26*26*26个点接上去。这个时候你很烦了,你不知道什么时候是个头。从这里你应该也清楚的知道该算法的空间复杂度有多高了。
Tire树存在三个模板,建树,查询,清空。那我们一个一个来讲。
建树:
char str[50];
tire *root = (tire*)malloc(sizeof(tire));//最初的节点,不包含任何内容。
for (int i = 0; i < LEN; i++)//所有子节点去全为空
root->next[i] = NULL;
root->isword = false;//标记为黑色(黑色不存在)
while (scanf("%s",str)!=EOF)
buildTire(root, str);


void insert(tire *root,char *word)//将初始节点和数组传进来
{
tire *p = root, *q;//q为新节点
while (*word!='�')//当还没到单词的末尾
{
if (p->next[*word - 'a'] == NULL)//该位置的单词还未标记
{
q = (tire*)malloc(sizeof(tire));//开辟一个新空间
for (int i = 0; i < LEN; i++)
q->next[i] = NULL;
q->isword = false;
p->next[*word - 'a'] = q;//将新空间附着在上一节点
}
p = p->next[*word - 'a'];//指向下一节点
word++;
}
p->isword = true;//标记为红色(红色为存在)
}
查询:
bool search(tire *root, char *word)
{
tire *p = root;
for (int i = 0; i < word[i] != '�'; i++)
{
if (p == NULL || p->next[word[i] - 'a'] == NULL)
return false;
p = p->next[word[i] - 'a'];
}
return p->isword;
}
题目练习 :Hat's Words :http://acm.hdu.edu.cn/showproblem.php?pid=1247 题目分析