除了提供诸如同步控制,线程池等基本工具外,为了提高开发人员的效率,JDK已经为我们准备了一大批好用的并发容器,这些容器都是线程安全的,可以大大减少开发工作量。你可以在里面找到链表、HashMap、队列等。你可以在里面找到链表、HashMap、队列等。
JDK提供的这些容器大部分在java.util.con-current包中。
•ConcurrentHashMap:这是一个高效的并发HashMap。你可以理解为一个线程安全的HashMap。
•CopyOnWriteArrayList:这是一个List,从名字看就是和ArrayList是一族的。在读多写少的场合,这个List的性能非常好,远远好于Vector。
•ConcurrentLinkedQueue:高效的并发队列,使用链表实现。可以看做一个线程安全的LinkedList。
•BlockingQueue:这是一个接口,JDK内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
•ConcurrentSkipListMap:跳表的实现。这是一个Map,使用跳表的数据结构进行快速查找。
除了以上并发包中的专有数据结构外,java.util下的Vector是线程安全的(虽然性能和上述专用工具没得比),另外Collections工具类可以帮助我们将任意集合包装成线程安全的集合。
一.在多线程环境中使用HashMap
1.一种可行的方法是使用Collections.synchronizedMap()方法包装我们的HashMap
public static Map m=Collections.synchronizedMap(new HashMap());
Collections.synchronizedMap()会生成一个名为SynchronizedMap的Map。它使用委托,将自己所有Map相关的功能交给传入的HashMap实现,而自己则主要负责保证线程安全。
SynchronizedMap内包装了一个map
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
通过mutex实现对这个m的互斥操作。比如,对于Map.get()方法,它的实现如下:
public V get(Object key) {
synchronized (mutex) {
return m.get(key);}
}
而其他所有相关的Map操作都会使用这个mutex进行同步。从而实现线程安全。这会导致所有对Map的操作全部进入等待状态,直到mutex锁可用。如果并发级别不高,一般也够用。但是,在高并发环境中,我们也有必要寻求新的解决方案。
2.一个更加专业的并发HashMap是ConcurrentHashMap。它位于java.util.concurrent包内。它专门为并发进行了性能优化,因此,更加适合多线程的场合。
二、在多线程环境中使用List
参考前面对HashMap的包装,在这里我们也可以使用
1. Collections. synchronizedList()方法来包装任意List,如下所示:
public static List<String> l=Collections.synchronizedList(new LinkedList<String>());
此时生成的List对象就是线程安全的。
2.vector
三、高效读写的队列:ConcurrentLinkedQueue
ConcurrentLinkedQueue应该算是在高并发环境中性能最好的队列就可以了。它之所有能有很好的性能,是因为其内部复杂的实现。
对Node进行操作时,使用了CAS操作。
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);}
方法casItem()表示设置当前Node的item值。它需要两个参数,第一个参数为期望值,第二个参数为设置目标值。当当前值等于cmp期望值时,就会将目标设置为val。同样casItem()方法也是类似的,但是它是用来设置next字段,而不是item字段
ConcurrentLinkedQueue内部有两个重要的字段,head和tail,分别表示链表的头部和尾部,它们都是Node类型。对于head来说,它永远不会为null,并且通过head以及succ()后继方法一定能完整地遍历整个链表。对于tail来说,它自然应该表示队列的末尾。
该队列特点:
1.tail的更新会产生滞后,并且每次更新会跳跃两个元素。
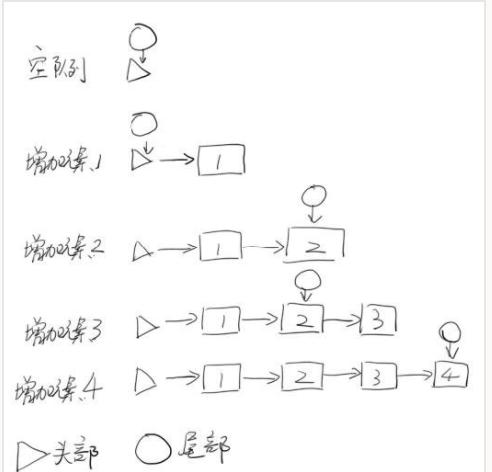
2.线程安全完全由CAS操作和队列的算法来保证。整个方法的核心是for循环,这个循环没有出口,直到尝试成功,这也符合CAS操作的流程。
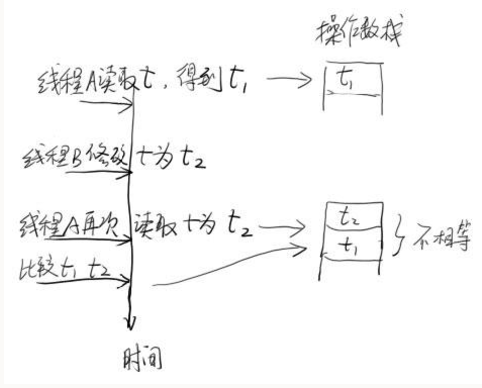
3. p = (t != (t = tail)) ? t : head;
这句代码虽然只有短短一行,但是包含的信息比较多。首先“!=”并不是原子操作,它是可以被中断的。也就是说,在执行“!=”是,程序会先取得t的值,再执行t=tail,并取得新的t的值。然后比较这两个值是否相等。在单线程时,t!=t这种语句显然不会成立。但是在并发环境中,有可能在获得左边的t值后,右边的t值被其他线程修改。这样,t!=t就可能成立。这里就是这种情况。如果在比较过程中,tail被其他线程修改,当它再次赋值给t时,就会导致等式左边的t和右边的t不同。如果两个t不相同,表示tail在中途被其他线程篡改。这时,我们就可以用新的tail作为链表末尾,也就是这里等式右边的t。但如果tail没有被修改,则返回head,要求从头部开始,重新查找尾部。
/**入队操作*/
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p 是最后一个节点
if (p.casNext(null, newNode)) {
//每2次,更新一下tail
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
//遇到哨兵节点,从都head开始遍历。
//但如果tail被修改,则使用tail(因为可能被修改正确了)
p = (t != (t = tail)) ? t : head;
else
// 取下一个节点或者最后一个节点
p = (p != t && t != (t = tail)) ? t : q;
}
}
/**弹出队列操作*/
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item; }
else if ((q = p.next) == null) {
updateHead(h, p); //将head设置为哨兵
return null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);
}
四、高效读取的数组:CopyOnWriteArrayList
为了将读取的性能发挥到极致,JDK中提供了CopyOnWriteArrayList类。对它来说,读取是完全不用加锁的,并且更好的消息是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。
所谓CopyOn-Write就是在写入操作时,进行一次自我复制。换句话说,当这个List需要修改时,我并不修改原有的内容(这对于保证当前在读线程的数据一致性非常重要),而是对原有的数据进行一次复制,将修改的内容写入副本中。写完之后,再将修改完的副本替换原来的数据。这样就可以保证写操作不会影响读了。
读取实现:
private volatile transient Object[] array;
public E get(int index) {
return get(getArray(), index);}
final Object[] getArray() {
return array;}
private E get(Object[] a, int index) {
return (E) a[index];}
写实现:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
首先,写入操作使用锁,当然这个锁仅限于控制写-写的情况。其重点在于进行了内部元素的完整复制。因此,会生成一个新的数组newElements。然后,将新的元素加入newElements。接着,使用新的数组替换老的数组,修改就完成了。整个过程不会影响读取,并且修改完后,读取线程可以立即“察觉”到这个修改(因为array变量是volatile类型)。
五、数据共享通道:BlockingQueue
ConcurrentLinkedQueue作为高性能的队列。对于并发程序而言,高性能自然是一个我们需要追求的目标。但多线程的开发模式还会引入一个问题,那就是如何进行多个线程间的数据共享呢?比如,线程A希望给线程B发一个消息,用什么方式告知线程B是比较合理的呢?
BlockingQueue是一个接口,实现类如下图:
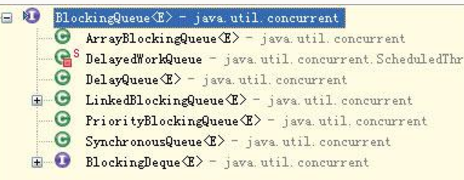
其中ArrayBlockingQueue是基于数组实现的,而LinkedBlockingQueue基于链表。也正因为如此,ArrayBlockingQueue更适合做有界队列,因为队列中可容纳的最大元素需要在队列创建时指定(毕竟数组的动态扩展不太方便)。而LinkedBlock-ingQueue适合做无界队列,或者那些边界值非常大的队列,因为其内部元素可以动态增加,它不会因为初值容量很大,而一口气吃掉你一大半的内存。
线程是如何知道队列中来了下一条消息的?
一种是线程按照一定的时间间隔不停地循环和监控这个队列,这是可行的,但是造成了不必要的资源浪费。
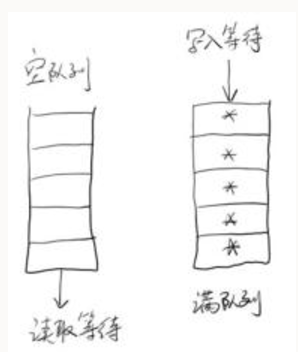
而BlockingQueue之所有适合作为数据共享的通道,其关键还在于Blocking上,BlockingQueue很好地解决了这个问题。它会让服务线程在队列为空时,进行等待,当有新的消息进入队列后,自动将线程唤醒
工作模式如下:
ArrayBlockingQueue的内部元素都放置在一个对象数组中:
final Object[] items;
1.向队列中压入元素可以使用offer()方法和put()方法。对于offer()方法,如果当前队列已经满了,它就会立即返回false。如果没有满,则执行正常的入队操作。我们需要关注的是put()方法。put()方法也是将元素压入队列末尾。但如果队列满了,它会一直等待,直到队列中有空闲的位置。
2.从队列中弹出元素可以使用poll()方法和take()方法。它们都从队列的头部获得一个元素。不同之处在于:如果队列为空poll()方法直接返回null,而take()方法会等待,直到队列内有可用元素。
因此,put()方法和take()方法才是体现Blocking的关键。
在ArrayBlockingQueue内部定义了以下一些字段:
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
当执行take()操作时,如果队列为空,则让当前线程等待在notEmpty上。新元素入队时,则进行一次notEmpty上的通知。
下面的代码显示了take()的过程:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
下面是元素入队的代码:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
当新元素进入队列后,需要通知等待在notEmpty上的线程,让他们继续工作。同理,对于put()操作也是一样的,当队列满时,需要让压入线程等待
六、随机数据结构:跳表(SkipList)
在JDK的并发包中,除了常用的哈希表外,还实现了一种有趣的数据结构——跳表。跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全。而对于跳表,你只需要部分锁即可。这样,在高并发环境下,你就可以拥有更好的性能。而就查询的性能而言,跳表的时间复杂度也是O(logn)。所以在并发数据结构中,JDK使用跳表来实现一个Map。
跳表的另外一个特点是随机算法。跳表的本质是同时维护了多个链表,并且链表是分层的,如图
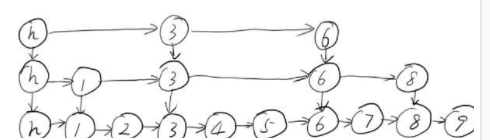
最低层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集,一个元素插入哪些层是完全随机的。因此,如果你运气不好的话,你可能会得到一个性能很糟糕的结构。但是在实际工作中,它的表现是非常好的。
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的
在跳表中查找元素7。查找从顶层的头部索引节点开始。由于顶层的元素最少,因此,可以快速跳跃那些小于7的元素。很快,查找过程就能到元素6。由于在第2层,元素8大于7,故肯定无法在第2层找到元素7,故直接进入底层(包含所有元素)开始查找,并且很快就可以根据元素6搜索到元素7。整个过程,要比一般链表从元素1开始逐个搜索快很多。如图:

因此,很显然,跳表是一种使用空间换时间的算法。
使用跳表实现Map和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。
实现这一数据结构的类是ConcurrentSkipListMap
和HashMap不同,对跳表的遍历输出是有序的。
跳表的内部实现有几个关键的数据结构组成。
1.首先是Node,一个Node就是表示一个节点
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
对Node的所有更新操作,使用的是CAS方法:
/**
* compareAndSet value field
*/
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
/**
* compareAndSet next field
*/
boolean casNext(Node<K,V> cmp, Node<K,V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
方法casValue()用来设置value的值,相对的casNext()用来设置next的字段。
2.另外一个重要的数据结构是Index。顾名思义,这个表示索引。它内部包装了Node,同时增加了向下的引用和向右的引用。
static class Index<K,V> {
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
整个跳表就是根据Index进行全网的组织的。
3.此外,对于每一层的表头,还需要记录当前处于哪一层。为此,还需要一个称为HeadIndex的数据结构,表示链表头部的第一个Index。它继承自Index。
/**
* Nodes heading each level keep track of their level.
*/
static final class HeadIndex<K,V> extends Index<K,V> {
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
核心内部元素就这三个,对于跳表的所有操作,就是组织好这些Index之间的连接关系。