Hive 入门
一、准备
1. Java 安装
Hive 是一个基于 Hadoop 的数据仓库,而 Hadoop 是基于 Java 开发的,所以我们需要安装 Java。
yum install -y java-1.8.0-openjdk-devel
[root@iZuf6c82diwquwsq69eqejZ ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
2. Hadoop 安装
Hadoop 是分布式文件存储系统,各个机器之间需要开启免密登录。为方便操作,这里我直接用 root 权限。如果是单机,就是自己免密登录自己,需要把生成的 id_rsa.pub 放到 authorized_keys 里面。
ssh-keygen -t rsa
我这里以三台机器为例,已经可以互相免密登录了。
139.196.112.183 hadoop-master
81.68.114.173 hadoop-slave1
47.102.144.35 hadoop-slave2
下载 Hadoop,实例为目前最新版本。(下载网址:https://hadoop.apache.org/releases.html)
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
解压出来,我这里解压到当前目录。
tar -zxvf hadoop-3.2.2.tar.gz
[root@iZuf6c82diwquwsq69eqejZ hadoop]# pwd
/work/docker/hadoop
修改 hadoop-env.sh 文件,添加 JAVE_HOME。
export JAVA_HOME=/usr
验证 Hadoop 是否安装成功。
[root@iZuf6c82diwquwsq69eqejZ hadoop]# /work/docker/hadoop/hadoop-3.2.2/bin/hadoop version
Hadoop 3.2.2
Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932
Compiled by hexiaoqiao on 2021-01-03T09:26Z
Compiled with protoc 2.5.0
From source with checksum 5a8f564f46624254b27f6a33126ff4
This command was run using /work/docker/hadoop/hadoop-3.2.2/share/hadoop/common/hadoop-common-3.2.2.jar
接着在三台机器上,修改四个 xml 文件。
# core-site.xml 文件,设置 hadoop 临时目录和 master。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/work/docker/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
</configuration>
# hdfs-site.xml 文件,设置 namenode 目录、datanode 目录和备份数。
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/work/docker/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/work/docker/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
# mapred-site.xml 文件,使用 yarn 集群来实现资源分配。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# yarn-site.xml 文件,设置 ResourceManager 对客户端暴露的地址,mapreduce_shuffle 为 NodeManager 上运行的附属服务,支持运行 MapReduce 程序。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
在 workers 文件中,列出所有节点的主机名或者 IP。
hadoop-master
hadoop-slave1
hadoop-slave2
分别在 sbin/start-dfs.sh, sbin/stop-dfs.sh 文件顶部添加如下配置:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
分别在 sbin/start-yarn.sh, sbin/stop-yarn.sh 文件顶部添加如下配置:
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
格式化 hdfs
/work/docker/hadoop/hadoop-3.2.2/bin/hdfs namenode -format
全部启动
/work/docker/hadoop/hadoop-3.2.2/sbin/start-all.sh
注意:以上操作都是在 master 进行,master 的 hosts 需要填内网 IP。
# master
[root@iZuf6c82diwquwsq69eqejZ hadoop]# jps
1241264 DataNode
1241079 NameNode
1242647 Jps
1241737 ResourceManager
1241902 NodeManager
1241484 SecondaryNameNode
# slave1
[root@VM-0-6-centos hadoop]# jps
10724 Jps
10519 NodeManager
10415 DataNode
# slave2
[root@iZuf65lasa7rugxfvzmywrZ hadoop]# jps
550760 Jps
550524 DataNode
550638 NodeManager
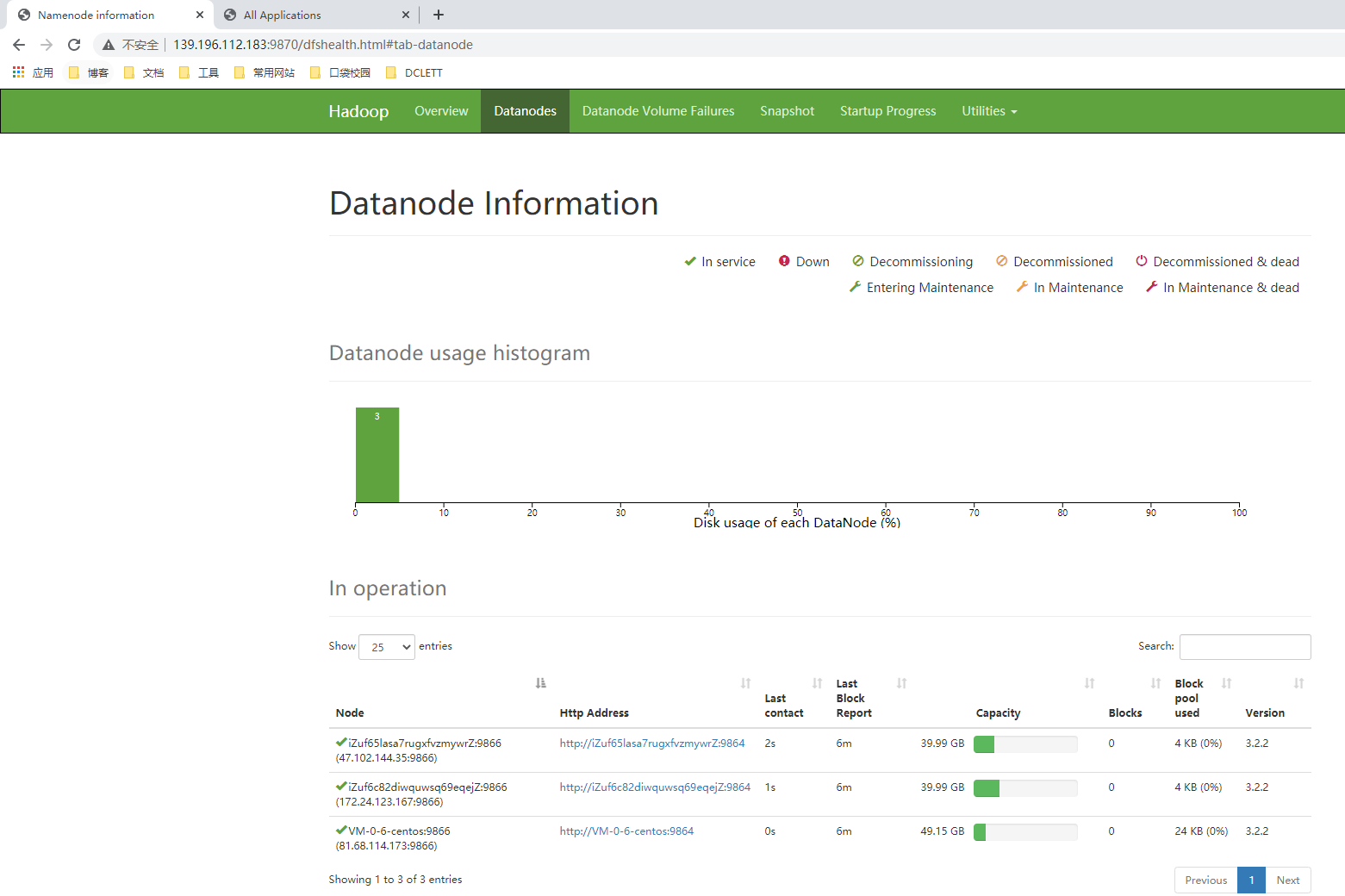
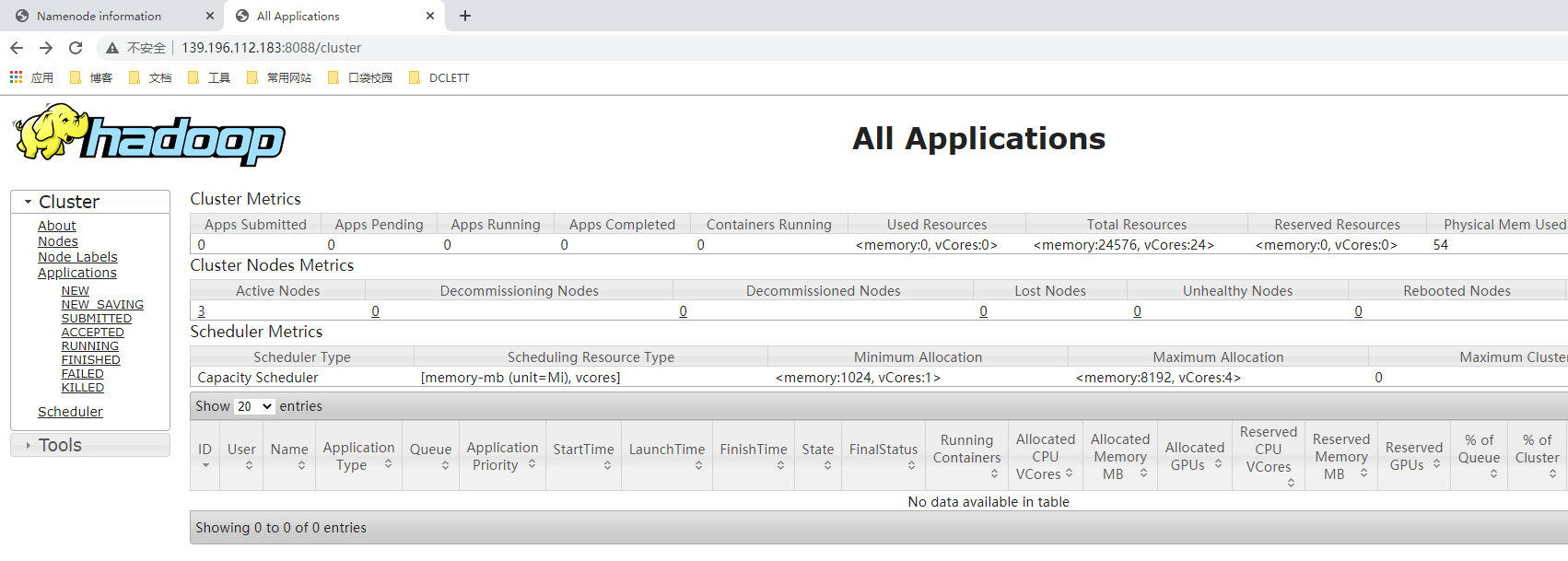
-
NameNode
在 master 上启动,负责调度。 当上传文件时,NameNode 会将文件分块并且分配到集群的 DataNode 节点上。NameNode 主要是用来保存 HDFS 的元数据信息,比如命名空间、块信息、节点信息等。当它运行的时候,这些信息是存在内存中的,也可以持久化到磁盘上。NameNode 启动的时候,会合并操作日志文件(edit logs)到镜像文件(fsimage)中,并且读取镜像文件。
-
SecondaryNameNode
只有在 NameNode 重启的时候,操作日志文件才会合并到镜像文件中,而 NameNode 是很少重启的,所以当 NameNode 运行了很长时间后,操作日志文件就会变得很大。这样如果 NameNode 挂了,重启将异常缓慢,并且会丢失内存中未来得及写入操作日志文件的数据。因此 SecondaryNameNode 应运而生,它会定期地获取 edit logs,并更新到自己的 fsimage 上,然后 cp 到 NameNode 中。如此 NameNode 下次重启时就会使用新的 fsimage 文件,减少重启时间。因此 SecondaryNameNode 最好单独放在一台配置和 NameNode 所在机器差不多的机器上。指定 SecondaryNameNode 需在 hdfs-site.xml 文件中配置:
<property> <name>dfs.secondary.http.address</name> <value>hadoop-slave2:50090</value> </property>注意:如果用的是云服务器,在 hadoop-slave2 机器上,这里得用内网 IP。
-
DataNode
它是文件系统的工作节点,负责存储数据,并且定期地向 NameNode 发送它们所存储的块的列表。当 DataNode 有写操作的时候,会跟 NameNode 通信,NameNode 会将元数据信息写入 edit logs。
-
NodeManager
是 YARN 集群每个节点上的代理,它管理 Hadoop 集群中单个计算节点。功能包括与 ResourceManager 保持通信,管理 Container(Container 是 YARN 中资源的抽象,它封装了某个节点上一定量的资源)的生命周期、监控每个 Container 的资源使用(内存、CPU等)情况、追踪节点健康状况、管理日志和不同应用程序用到的附属服务等。
-
ResourceManager
负责 YARN 集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序。
更多关于 Yarn 的资料:https://zhuanlan.zhihu.com/p/54192454
3. Hive 安装
因为我们的 Hadoop 版本是 3.2.2,所以 Hive 要下载与之匹配的 3.1.2 版本。下载地址:http://www.apache.org/dyn/closer.cgi/hive/
http://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
解压到当前目录:
tar -zxvf apache-hive-3.1.2-bin.tar.gz
[root@iZuf6c82diwquwsq69eqejZ hive]# pwd
/work/docker/hive
在 conf 目录下新增 hive-env.sh 配置文件并设置 Hadoop 环境。
HADOOP_HOME=/work/docker/hadoop/hadoop-3.2.2
修改 hive-site.xml 配置文件:
cp hive-default.xml.template hive-site.xml
# 设置 Hive 临时文件目录
<property>
<name>system:java.io.tmpdir</name>
<value>/work/docker/hive/tmp</value>
</property>
# 修改文件中所有的 ${system:user.name} 为 ${user.name}
# 如下所示
${system:java.io.tmpdir}/${user.name}
# 设置 metastore 为 MySQL
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://139.224.**.**:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
下载对应版本的 MySQL 驱动,下载地址:https://downloads.mysql.com/archives/c-j/
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-8.0.22.tar.gz
解压出来复制到 lib 目录下:
cp mysql-connector-java-8.0.22.jar /work/docker/hive/apache-hive-3.1.2-bin/lib
注意: 3.2.2 版本的 Hadoop 和 3.1.2 版本的 Hive 有一个坑,两者的 guava-19.0.jar 版本不一样,启动会报错。我们需要把低版本的删掉,高版本的 cp 过来。
rm -rf /work/docker/hive/apache-hive-3.1.2-bin/lib/guava-19.0.jar
cp /work/docker/hadoop/hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar /work/docker/hive/apache-hive-3.1.2-bin/lib
初始化 MySQL 数据库:
/work/docker/hive/apache-hive-3.1.2-bin/bin/schematool -dbType mysql -initSchema
注意: 这里还有一个坑,初始化的时候会报错:
Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3219,96,"file:/work/docker/hive/apache-hive-3.1.2-bin/conf/hive-site.xml"]
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3040)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2989)
at org.apache.hadoop.conf.Configuration.loadProps(Configuration.java:2864)
at org.apache.hadoop.conf.Configuration.addResourceObject(Configuration.java:1012)
at org.apache.hadoop.conf.Configuration.addResource(Configuration.java:917)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5151)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.<init>(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Caused by: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3219,96,"file:/work/docker/hive/apache-hive-3.1.2-bin/conf/hive-site.xml"]
at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:621)
at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:491)
at com.ctc.wstx.sr.StreamScanner.reportIllegalChar(StreamScanner.java:2456)
at com.ctc.wstx.sr.StreamScanner.validateChar(StreamScanner.java:2403)
at com.ctc.wstx.sr.StreamScanner.resolveCharEnt(StreamScanner.java:2369)
at com.ctc.wstx.sr.StreamScanner.fullyResolveEntity(StreamScanner.java:1515)
at com.ctc.wstx.sr.BasicStreamReader.nextFromTree(BasicStreamReader.java:2828)
at com.ctc.wstx.sr.BasicStreamReader.next(BasicStreamReader.java:1123)
at org.apache.hadoop.conf.Configuration$Parser.parseNext(Configuration.java:3336)
at org.apache.hadoop.conf.Configuration$Parser.parse(Configuration.java:3130)
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3023)
... 14 more
我们只需要删掉 hive-site.xml 文件中,报错的那一行就行了。(这里我把整个 description 删掉了)
3218 <description>
3219 Ensures commands with OVERWRITE (such as INSERT OVERWRITE) acquire Exclusive locks fortransactional tables. This ensures that inserts (w/o overwrite) running concurrently
3220 are not hidden by the INSERT OVERWRITE.
3221 </description>
再次初始化数据库,成功。至此,Hive 已经安装完毕。
二、实战
有这样一个业务场景,用户给主播刷礼物,然后主播查看每天的礼物报表。
如此经典的情形,我们可以在服务端按照一定的格式打点,然后推送到 HDFS,再由 Hive 读取。这里有个很重要的概念,就是分区,在 HDFS 里面,分区体现在多个目录 。Hive 里面,分区体现在创表的时候的 PARTITIONED BY 语句。
先在 Hadoop 里面创建好对应的目录:
./hadoop fs -mkdir -p /dclett/tv_gift
[root@iZuf6c82diwquwsq69eqejZ bin]# ./hadoop fs -ls /dclett
Found 1 items
drwxr-xr-x - root supergroup 0 2021-05-05 17:31 /dclett/tv_gift
打点日志文件:
# /work/dclett/tv_gift/210505/gift.log
1,Dick,1001,17,101,apple,10,1620207298
2,Erick,1001,17,102,banana,12,1620207345
3,Alicia,1002,18,103,lipstick,1,1620207394
# /work/dclett/tv_gift/210506/gift.log
4,Dick,1002,18,104,candy,99,1620293698
5,Alicia,1002,18,105,donut,99,1620293758
[root@iZuf6c82diwquwsq69eqejZ dclett]# tree
.
└── tv_gift
├── 210505
│ └── gift.log
└── 210506
└── gift.log
分别将两天的日志文件推送到 HDFS:
./hadoop fs -mkdir /dclett/tv_gift/dt=210505; ./hadoop fs -put -f /work/dclett/tv_gift/210505/gift.log /dclett/tv_gift/dt=210505
./hadoop fs -mkdir /dclett/tv_gift/dt=210506; ./hadoop fs -put -f /work/dclett/tv_gift/210506/gift.log /dclett/tv_gift/dt=210506
[root@iZuf6c82diwquwsq69eqejZ bin]# ./hadoop fs -ls /dclett/tv_gift
Found 2 items
drwxr-xr-x - root supergroup 0 2021-05-05 17:47 /dclett/tv_gift/dt=210505
drwxr-xr-x - root supergroup 0 2021-05-05 17:48 /dclett/tv_gift/dt=210506
创建 Hive 数据库和表(使用 dt 字段作为分区):
create database dclett;
use dclett;
create table tv_gift(
id int,
name string,
room_id int,
anchor_id int,
goods_id int,
goods_name string,
goods_num int,
create_time int
)
PARTITIONED BY (
`dt` string)
row format delimited fields terminated by ','
location 'hdfs://hadoop-master:9000/dclett/tv_gift';
如此一来,貌似已经大功告成了。然而当我 select 的时候,却发现没有数据。
hive> select * from tv_gift;
OK
Time taken: 0.489 seconds
难道分区没有成功?
hive> show partitions tv_gift;
OK
Time taken: 0.447 seconds
可以说是分区没有成功,因为我们还少了一步操作:将分区信息写入 metastore。
hive> msck repair table tv_gift;
OK
Partitions not in metastore: tv_gift:dt=210505 tv_gift:dt=210506
Repair: Added partition to metastore tv_gift:dt=210505
Repair: Added partition to metastore tv_gift:dt=210506
Time taken: 0.672 seconds, Fetched: 3 row(s)
hive> show partitions tv_gift;
OK
dt=210505
dt=210506
Time taken: 0.739 seconds, Fetched: 2 row(s)
MySQL 查看分区信息:
mysql> select * from PARTITIONS;
+---------+-------------+------------------+-----------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+-----------+-------+--------+
| 3 | 1620209674 | 0 | dt=210505 | 26 | 23 |
| 4 | 1620209674 | 0 | dt=210506 | 27 | 23 |
+---------+-------------+------------------+-----------+-------+--------+
2 rows in set (0.00 sec)
Hive 中现在有数据了:
hive> select * from tv_gift;
OK
1 Dick 1001 17 101 apple 10 1620207298 210505
2 Erick 1001 17 102 banana 12 1620207345 210505
3 Alicia 1002 18 103 lipstick 1 1620207394 210505
4 Dick 1002 18 104 candy 99 1620293698 210506
5 Alicia 1002 18 105 donut 99 1620293758 210506
Time taken: 0.503 seconds, Fetched: 5 row(s)
如此才是大功告成,记得每次 put 新分区的时候在 Hive 执行下 msck repair table TableName 命令。