1 概述
上一篇文章介绍了如何使用虚拟机搭建集群,到了这篇文章就是实战了,使用真实的三台不同服务器进行Hadoop集群的搭建。具体步骤其实与虚拟机的差不多,但是由于安全组以及端口等等一些列的问题,会与虚拟机有所不同,废话不多说,下面正式开始。
2 约定
Master节点的ip用MasterIP表示,主机名用master表示- 两个
Worker节点的ip用Worker1IP/Worker2IP表示,主机名用worker1/worker2表示 - 这里为了演示方便统一使用
root用户登录,当然生产环境不会这样
3 (可选)本地Host
修改本地Host,方便使用主机名来进行操作:
sudo vim /etc/hosts
# 添加
MaterIP master
Worker1IP worker1
Worker2IP worker2
4 ssh
本机生成密钥对后复制公钥到三台服务器上:
ssh-keygen -t ed25519 -a 100 # 使用更快更安全的ed25519算法而不是传统的RSA-3072/4096
ssh-copy-id root@master
ssh-copy-id root@worker1
ssh-copy-id root@worker2
这时可以直接使用root@host进行连接了:
ssh root@master
ssh root@worker1
ssh root@worker2
不需要输入密码,如果不能连接或者需要输入密码请检查/etc/ssh/sshd_config或系统日志。
5 主机名
修改Master节点的主机名为master,两个Worker节点的主机名为worker1、worker2:
# Master节点
vim /etc/hostname
master
# Worker1节点
# worker1
# Worker2节点
# worker2
同时修改Host:
# Master节点
vim /etc/hosts
Worker1IP worker1
Worker2IP worker2
# Worker1节点
vim /etc/hosts
MasterIP master
Worker2IP worker2
# Worker1节点
vim /etc/hosts
MasterIP master
Worker1IP worker1
修改完成之后需要互ping测试:
ping master
ping worker1
ping worker2
ping不通的话应该是安全组的问题,开放ICMP协议即可:

6 配置基本环境
6.1 JDK
scp上传OpenJDK 11,解压并放置于/usr/local/java下,同时修改PATH:
export PATH=$PATH:/usr/local/java/bin
如果原来的服务器装有了其他版本的JDK可以先卸载:
yum remove java
注意设置环境变量后需要测试以下java,因为不同服务器的架构可能不一样:


比如笔者的Master节点为aarch64架构,而两个Worker都是x86_64架构,因此Master节点执行java时报错如下:

解决办法是通过yum install安装OpenJDK11:
yum install java-11-openjdk
6.2 Hadoop
scp上传Hadoop 3.3.0,解压并放置于/usr/local/hadoop下,注意选择对应的架构:
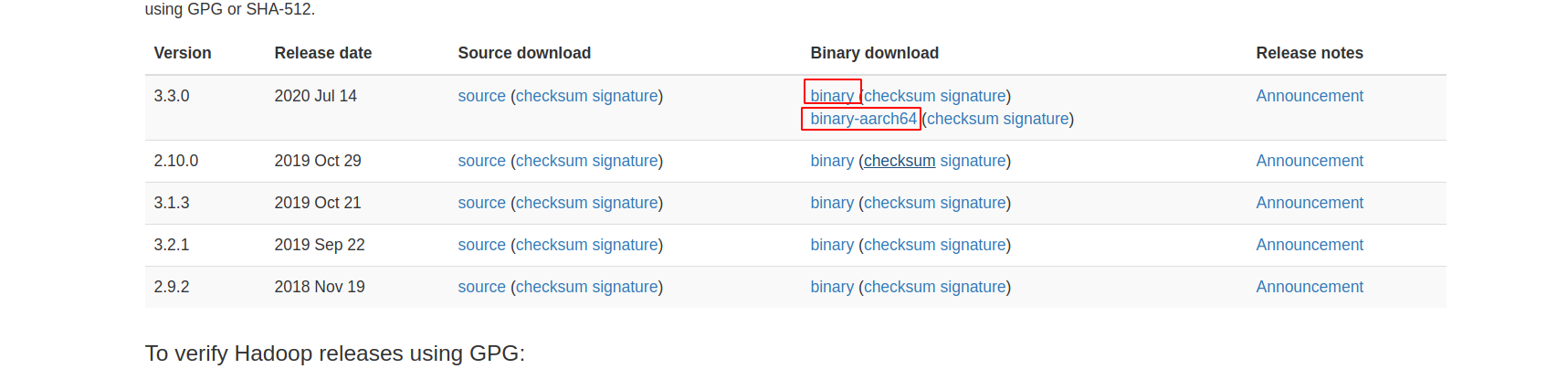
解压后修改以下四个配置文件:
etc/hadoop/hadoop-env.shetc/hadoop/core-site.xmletc/hadoop/hdfs-site.xmletc/hadoop/workers
6.2.1 hadoop-env.sh
修改JAVA_HOME环境变量即可:
export JAVA_HOME=/usr/local/java # 修改为您的Java目录
6.2.2 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
</configuration>
具体选项与虚拟机方式的设置相同,这里不再重复叙述。
6.2.3 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
6.2.4 workers
worker1
worker2
6.2.5 复制配置文件
# 如果设置了端口以及私钥
# 加上 -P 端口 -i 私钥
scp /usr/local/hadoop/etc/hadoop/* worker1:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/* worker2:/usr/local/hadoop/etc/hadoop/
7 启动
7.1 格式化HDFS
在Master中,首先格式化HDFS
cd /usr/local/hadoop
bin/hdfs namenode -format
如果配置文件没错的话就格式化成功了。
7.2 hadoop-env.sh
还是在Master中,修改/usr/local/hadoop/etc/hadoop/hadoop-env.sh,末尾添加:
HDFS_DATANODE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
7.3 启动
首先Master开放9000以及9870端口(一般安全组开放即可,如果开启了防火墙firewalld/iptables则添加相应规则),并在Master节点中启动:
sbin/start-dfs.sh
浏览器输入:
MasterIP:9870
即可看到如下页面:

如果看到Live Nodes数量为0请查看Worker的日志,这里发现是端口的问题:

并且在配置了安全组,关闭了防火墙的情况下还是如此,则有可能是Host的问题,可以把Master节点中的:
# /etc/hosts
127.0.0.1 master
删去,同样道理删去两个Worker中的:
# /etc/hosts
127.0.0.1 worker1
127.0.0.1 worker2
8 YARN
8.1 环境变量
修改/usr/local/hadoop/etc/hadoop/hadoop-env.sh,添加:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
8.2 YARN配置
在两个Worker节点中修改/usr/local/hadoop/etc/hadoop/yarn-site.xml:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
8.3 开启YARN
Master节点中开启YARN:
cd /usr/local/hadoop
sbin/start-yarn.sh
同时Master的安全组开放8088以及8031端口。
8.4 测试
浏览器输入:
MasterIP:8088
应该就可以访问如下页面了:
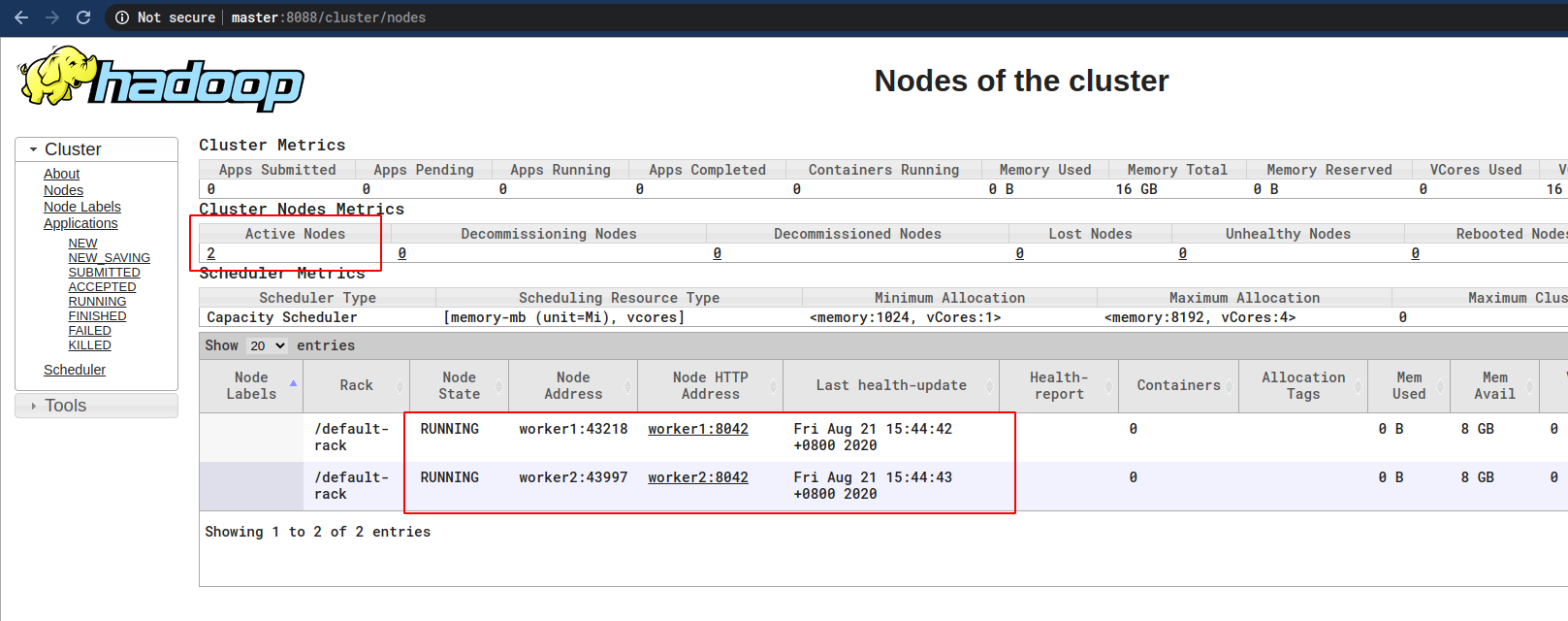
至此集群正式搭建完成。