一. MyISAM与Innodb区别
1. MyISAM:
不提供事务的支持;
不支持行级锁和外键;
数据和索引分别存储;
索引实现方式:B+树索引,MyISAM是堆表。
2. Innodb:
提供了对数据库ACID事务的支持;
提供行级锁(锁定粒度小并发能力高)和外键的约束;
数据和索引是集中存储;
索引实现方式:B+树索引,Innodb是索引组织表;
InnoDB写的处理效率差一些,并且会占用更多的磁盘空间以保留数据和索引。
二. 策略优化
对于经常变更的数据来说,CHAR比VARCHAR更好,因为CHAR不容易产生碎片。
对于非常短的列,CHAR比VARCHAR在存储空间上更有效率。
使用时要注意只分配需要的空间,更长的列排序时会消耗更多内存。
尽量避免使用TEXT/BLOB类型,查询时会使用临时表,导致严重的性能开销。
日期和时间类型,尽量使用timestamp,空间效率高于datetime,用整数保存时间戳通常不方便处理。如果需要存储微妙,可以使用bigint存储。
三. 索引优化
1. 索引的原理(就是把无序的数据变成有序的查询)
1)把创建了索引的列的内容进行排序
2)对排序结果生成倒排表
3)在倒排表内容上拼上数据地址链
4)在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
2. 构建索引优劣势
优势:
类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本;
通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
劣势:
实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间;
虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。
3. 索引设计原则
1)对查询频次较高,且数据量比较大的表建立索引;
2)索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合;
3)索引可以有效的提升查询数据的效率,但对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,降低DML操作的效率;
4)索引名尽量短些,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
6)定义有外键的数据列一定要建立索引
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引(索引时间=去索引中取+取相应的数据条件,而重复值太多效率反而更慢)
8)对于定义为text、image和bit的数据类型的列不要建立索引
9)利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS);
就相当于对name 创建索引 ;对name , email 创建了索引 ;对name , email, status 创建了索引
4. sql语句索引优化
1)order by
当我们使用order by将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序,即将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果,影响性能。
优化:我们对该字段建立索引alter table 表名 add index(字段名),那么由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。
2)join
对join语句匹配关系(on)涉及的字段建立索引能够提高效率
3)优化关联查询
确定ON是否有索引,确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引
4)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
(select id from t where num is null,可以在num上设置默认值0,确保表中num列没有null值)

5)应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描(但mysql5.7版本已经支持)
6)in 和 not in 也要慎用,否则会导致全表扫描
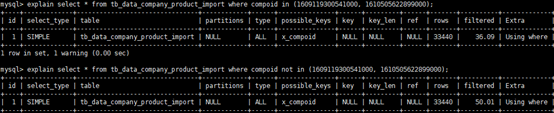
7)应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
(select id from t where substring(name,1,3)=’abc’
-- name以abc开头的id应改为:
select id from t where name like ‘abc%’)
8) like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效。
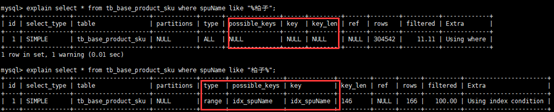
解决方案 : 通过覆盖索引来解决

9)字符串不加单引号,造成索引失效。
10)不要在索引列上进行运算操作,索引将失效。

11)尽量使用覆盖索引,避免select *;尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少select * 。

如果查询列,超出索引列,也会降低性能。