1 利用jupyter notebook写代码
C:Userszuo>jupyter notebook
2 在jupyter notebook页面,有快捷方式,可以在help中设置。

3 BeautifulSoup的常用方法
from bs4 import BeautifulSoup text = ''' <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no"> <title>Title</title> <link rel="stylesheet" href="bootstrap-3.3.7-dist/css/bootstrap.min.css"> </head> <body> <h1>hello world</h1> <span class="s1">xxx</span> <a id="a1" href="" name="y">yyy</a> <a href="https://baidu.com" name="baidu">百度</a> <a href="https://tencent.com" name="tentent">腾讯</a> <script src="jquery-3.2.1.min.js"></script> <script src="bootstrap-3.3.7-dist/js/bootstrap.min.js"></script> </body> </html> ''' soup = BeautifulSoup(text,'html.parser') # 需要传参,解析器 print(soup.text) # 筛选标签 print(soup.select('a')) print(soup.select('h1')) print(soup.select('h1')[0]) print(soup.select('h1')[0].text) # 筛选 id print(soup.select('#a1')) print(soup.select('#a1')[0]) print(soup.select('#a1')[0].text) # 筛选 class print(soup.select('.s1')) print(soup.select('.s1')[0]) print(soup.select('.s1')[0].text) # 筛选所有a表的href的属性 for link in soup.select('a'): print(link,type(link),link['href'],link['name']) # tag的属性操作方法与字典相同
输出:
D:Anaconda3python.exe D:/virtualenv/xxx/xxx/1.py Title hello world xxx yyy 百度 腾讯 [<a href="" id="a1" name="y">yyy</a>, <a href="https://baidu.com" name="baidu">百度</a>, <a href="https://tencent.com" name="tentent">腾讯</a>] [<h1>hello world</h1>] <h1>hello world</h1> hello world [<a href="" id="a1" name="y">yyy</a>] <a href="" id="a1" name="y">yyy</a> yyy [<span class="s1">xxx</span>] <span class="s1">xxx</span> xxx <a href="" id="a1" name="y">yyy</a> <class 'bs4.element.Tag'> y <a href="https://baidu.com" name="baidu">百度</a> <class 'bs4.element.Tag'> https://baidu.com baidu <a href="https://tencent.com" name="tentent">腾讯</a> <class 'bs4.element.Tag'> https://tencent.com tentent
select('#id span p ')
text = ''' <!DOCTYPE html> <html lang="zh-CN"> <body> <div class="d1"> <span class="s1"></span> <div class="d2"> <span class="s2"></span> <div class="d3"> <p class="p1">hello world</p> </div> </div> </div> <div class="d1"> </div> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(text,'html.parser') res = soup.select('.d1 div p') #select方法可以通过标签 逐层查找 print(res,len(res))
输出:
[<p class="p1">hello world</p>] 1
.contents,contents 属性可以将tag的子节点以列表的方式输出
text = '''
<!DOCTYPE html>
<html lang="zh-CN">
<body>
<div class="d1">
<span class="s1"></span>
<div class="d2">
<span class="s2"></span>
<div class="d3">
<p class="p1">hello world</p>
</div>
</div>
</div>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(text,'html.parser')
res = soup.select('.d1')[0]
for i in range(len(res.contents)):
print(res.contents[i])
print(res.contents,len(res.contents))
输出:
<span class="s1"></span> <div class="d2"> <span class="s2"></span> <div class="d3"> <p class="p1">hello world</p> </div> </div> [' ', <span class="s1"></span>, ' ', <div class="d2"> <span class="s2"></span> <div class="d3"> <p class="p1">hello world</p> </div> </div>, ' '] 5
4 requests,BeautifulSoup两者的结合的简单应用,爬虫腾讯nba首页的标题及相关网址。比较easy。
import requests from bs4 import BeautifulSoup res = requests.get('http://sports.qq.com/nba/') res.encoding = 'gbk' soup = BeautifulSoup(res.text,'html.parser') for item in soup.select('.icon-v'): title = item.text url = item['href'] print(title,url)
输出:
数据帝:火箭刷新三分纪录 詹皇一成就称霸NBA http://sports.qq.com/a/20180402/023995.htm 红黑榜:剩4场还需59板!韦少想场均三双得“刷”了 http://sports.qq.com/a/20180402/017828.htm 2日综述:西蒙斯准三双76人十连胜 詹皇三双骑士胜 http://sports.qq.com/a/20180402/018807.htm 哈登25+8集锦 http://v.qq.com/x/page/v0026yjpvej.html 比赛单节回放 http://v.qq.com/x/page/v00267dvuvl.html 五佳球 http://v.qq.com/x/page/z0026q6tai0.html 火箭季后赛首轮最想打谁?这两支球队成理想对手 http://sports.qq.com/a/20180402/006580.htm 直击-圣城今夜中国风 哈登领衔秀中文:爱你! http://sports.qq.com/a/20180402/004477.htm 三分40中6!哈登手感成迷 是否也该让他轮休 http://sports.qq.com/a/20180402/002498.htm 詹姆斯集锦 https://v.qq.com/x/cover/qpj1wfj6xs37jcv/t0026a945ua.html 五佳球:詹姆斯禁区飞身怒扣 https://v.qq.com/x/cover/qpj1wfj6xs37jcv/b0026yudkdb.html 骑士赢球仍被狂嘘 詹皇:我能做其他事帮助获胜 http://sports.qq.com/a/20180402/012409.htm KD集锦 http://v.qq.com/x/page/v0026lzsnes.html 汤神集锦 http://v.qq.com/x/page/y0026vjpbqj.html 五佳球 http://v.qq.com/x/page/n0026t1h3nd.html 单节回放 https://v.qq.com/x/cover/3s23igd42po7lmy/h0026lt9nbp.html 阿杜被新秀晃倒强硬回击 一夜缔造两项里程碑 http://sports.qq.com/a/20180402/014353.htm 前方直击-麦考伤情无碍今日出院 勇士全队啥反应? http://sports.qq.com/a/20180402/017943.htm 韦少26+15+13集锦 http://v.qq.com/x/page/y0026zgw6j0.html 雷霆vs鹈鹕五佳球 http://v.qq.com/x/page/q0026e8qbh4.html 《NBA数据酷》:乔丹神奇比赛力压科比81分 http://v.qq.com/x/page/l0026s5o0qe.html 火箭本季夺冠无悬念?美娜粉嫩出镜为你详解 https://v.qq.com/x/cover/bnt1h8oqszrau20/i002619v18i.html 马刺完了?你还是太年轻!保持连胜他们仍能拿50胜 http://sports.qq.com/a/20180402/018352.htm 密歇根防守强在哪儿?翻版绿军欲推翻维拉诺瓦 http://sports.qq.com/a/20180402/018459.htm 博彩公司看好维拉诺瓦夺冠 3年2夺冠已成定局? http://sports.qq.com/a/20180402/019851.htm 当《灌篮高手》在日本成现实 中国篮球为何无动于衷? http://sports.qq.com/a/20180402/004467.htm 直击-最终四强有多疯狂?四个人为看它挤一张床 http://sports.qq.com/a/20180402/013969.htm 对话密歇根球员:维拉诺瓦像勇士 不愿自比灰姑娘 http://sports.qq.com/a/20180402/015985.htm 一文读懂希腊篮球:获乔丹盛赞 催生最强美国男篮 http://sports.qq.com/a/20180402/022059.htm
5 爬取163新闻页面
import requests from bs4 import BeautifulSoup from datetime import datetime import re import json def get_comment_vote(news): key = re.search('/(w+).html',news).group(1) comment_url = 'http://sdk.comment.163.com/api/v1/products/a2869674571f77b5a0867c3d71db5856/threads/{}'.format(key) comment_res = requests.get(comment_url) jd = json.loads(comment_res.text) comment = jd['tcount'] vote = jd['cmtAgainst'] + jd['cmtVote'] + jd['rcount'] return (comment,vote) def crawl(news): try: result = {} res = requests.get(news) res.encoding = 'gbk' soup = BeautifulSoup(res.text,'html.parser') title = soup.select('.post_content_main h1')[0].text date1 = soup.select('.post_time_source')[0].contents[0].lstrip().rstrip('u3000来源: ') date = datetime.strptime(date1,'%Y-%m-%d %H:%M:%S') source = soup.select('.cDGray span')[0].contents[1].lstrip(' 本文来源:') author = soup.select('.cDGray span')[1].text.lstrip('责任编辑:') comment,vote = get_comment_vote(news) result['title'] = title result['date'] = date result['source'] = source result['author'] = author result['comment'] = comment result['vote'] = vote return result except: pass NEWS = 'http://news.163.com/' res = requests.get(NEWS) res.encoding= 'gbk' soup = BeautifulSoup(res.text,'html.parser') for item in soup.select('a'): if item.get('href') and item['href'].startswith('http://news.163.com/18/'): print(item['href']) result = crawl(item['href']) print(result)
6 开发者工具中的XHR
一句话,记录ajax中的请求。
7 页面加载过程中的异步加载现象
比如新浪新闻,当往下拉到地步,会有自动加载的现象,网易新闻和腾讯新闻并没有这种现象。这便是异步加载,同时JS实现的。
在开发者工具中的Network的JS中可以捕捉到。返回的json数据外面套了一层JS函数。

8 使用pandas 整理数据
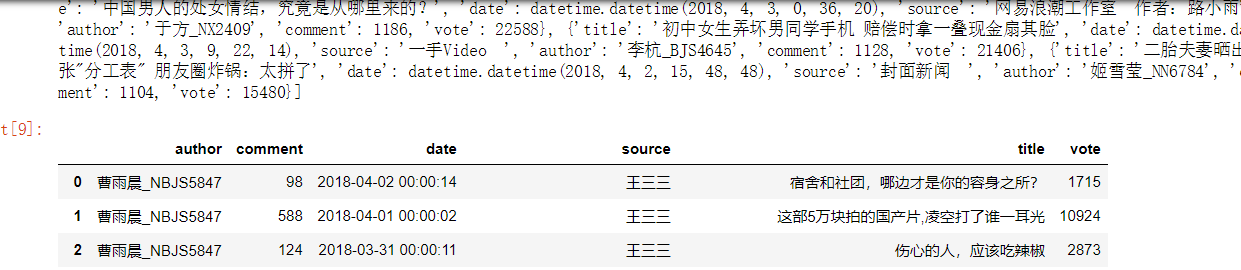
这里涉及到图表,pycharm不如jupyter notebook好用
import pandas print(total) df = pandas.DataFrame(total) df
输出:
在这里,total 是一个列表,列表中的元素是一个个拥有键值对的字典。
df = pandas.DataFrame(total)
df 的样式如下如所示。
9 数据存储到数据库
df.to_excel('news.xlsx')
注意,xlsx的后缀名要加上。
最后生成excel文件。
