2.5 安全字符串函数
|
不安全的字符串函数 |
Strsafe函数 |
Safe CRT函数 (C运行库) |
|
strcpy, wcscpy, _tcscpy, _mbscpy, strcpy , lstrcpy, _tccpy, _mbccpy |
StringCchCopy StringCbCopy StringCchCopyEx StringCbCopyEx |
strcpy_s |
|
strcat, wcscat , _mbscat, strcat, lstrcat, , strcatbuff, strcatchain, _tccat, _mbccat |
StringCchCat StringCbCat StringCchCatEx StringCbCatEx |
strcat_s |
|
wnsprintf, wsprintf, sprintf, swprintf, _stprintf |
StringCchPrintf StringCbPrintf StringCchPrintfEx StringCbPrintfEx |
_snprintf_s _snwprintf_s |
|
目标缓冲区太小时,不发生截断 |
目标缓冲区太小时,会发生截断 |
不发生截断 |
★String Safe函数:微软提供的内联形式函数,可以当做API(在strsafe.h文件中,注意要在包含其他文件之后,才包含该文件!)
★Safe CRT函数:C运行库
【SafeString程序】自定义错误处理函数

/*--------------------------------------------------------------------------------------- 功能:实现课本P19页,自定义函数调用失败处理程序 ----------------------------------------------------------------------------------------*/ #include <tchar.h> #include <stdlib.h> #include <windows.h> #include <stdint.h> #include <crtdbg.h> //要用到_CrtSetReportMode函数 #include <strsafe.h> //自定义函数调用失败的处理程序——只有在Debug版下才有效,Release中所有的参数将被传入NULL或0。 //当某个函数调用失败,系统会调用该函数,同时传入“错误描述文本”、出错的函数名称,文件名及出错所在行数。 void InvalidParameterHandle(PCTSTR expression, PCTSTR function, PCTSTR file, unsigned int line, uintptr_t /*pReserved*/) { _tprintf(_T("expression %s, function %s, file %s, line %d "),expression,function,file,line); } int _tmain() { _CrtSetReportMode(_CRT_ASSERT, 0); //禁用“调试断言失败”对话框 TCHAR szBefore[5] = { _T('B'), _T('B'), _T('B'), _T('B') ,'�'}; TCHAR szBuffer[10] = { _T('-'), _T('-'), _T('-'), _T('-'), _T('-'), _T('-'), _T('-'), _T('-'), '�' }; TCHAR szAfter[5] = { _T('A'), _T('A'), _T('A'), _T('A'), '�' }; //注册函数调用失败的处理程序 _set_invalid_parameter_handler(InvalidParameterHandle); //源字符串10个字符(不含�),目标缓冲区,只能容纳9个,会出错(发生错误时,不弹出Debug //Assertion Failure对话框而是调用自定义的InvalidParameterHandle函数)
errno_t ret = _tcscpy_s(szBuffer, _countof(szBuffer), _T("0123456789"));
return 0;
}
2.6 Str Safe函数的介绍(须含包strsafe.h文件)——目标缓冲区太小时,会发生截断。
(1)StringCchXXXX函数——其中的Cch表示字符的个数,可用_countof(pszDest)计算
①StringCchCopy——复制一个字符串到缓冲区,但要求提供目标缓冲区的长度,以确保写入数据不会超出缓冲区的末尾使用该函数替代以下函数:strcpy、wcscpy、_tcscpy、lstrcpy、StrCpy等函数。
|
参数 |
描述 |
|
LPTSTR pszDest |
缓冲区,用于接收拷贝过来的字符串 |
|
size_t cchDest |
①目标缓冲区的大小(字符个数)——_countof(pszDest) ②该值必须大于或等于 lstrlen(pszSrc) + 1(待拷贝字符串的字符+'�') ③这个数不能超过 STRSAFE_MAX_CCH。 |
|
LPCTSTR pszSrc |
待拷贝的字符串 |
|
返回值 |
①S_OK:字符串正常拷贝 ②STRSAFE_E_INVALID_PARAMETER:cchDest 参数的值为 0或cchDest 参数的值大于 STRSAFE_MAX_CCH。 ③STRSAFE_E_INSUFFICIENT_BUFFER:因缓冲区空间不足导致失败;结果被截断,但仍然包含'�'结尾;如果截断操作可以被接受,则不一定被看作是失败,即这时的返回值也可认为是可接受的。 |
②StringCchCat——将一个字符串拼接到另一个字符,使用该函数替代以下函数:strcat、 wcscat、_tcsat、lstrcat、StrCat和StrCatBuff等函数。
|
参数 |
描述 |
|
LPTSTR pszDest |
①目标缓冲区,同时包含第一个字符串 ②该缓冲区应该大于或等于(lstrlen(pszDest) +lstrlen(pszSrc) + 1)*sizeof(TCHAR) |
|
size_t cchDest |
①目标缓冲区的大小(字符个数)——_countof(pszDest) ②该缓冲区必须大于或等于lstrlen(pszDest) +lstrlen(pszSrc) + 1(两个字符串的字符总和+'�') ③这个数不能超过 STRSAFE_MAX_CCH。 |
|
LPCTSTR pszSrc |
第2个字符串 |
|
返回值 |
①S_OK:字符串正常拼接 ②STRSAFE_E_INVALID_PARAMETER:cchDest 参数的值为 0或cchDest 参数的值大于 STRSAFE_MAX_CCH;目标缓冲区空间已满。 ③STRSAFE_E_INSUFFICIENT_BUFFER:因缓冲区空间不足导致失败;结果被截断,但仍然包含'�'结尾;如果截断操作可以被接受,则不一定被看作是失败。 |
③StringCchLength——用于确定字符串是否超过了规定的长度,以字符为计算单位(不含�),用来替换strlen、wcslen和_tcslen函数。
|
参数 |
描述 |
|
LPCTSTR psz |
指向待检查的字符串 |
|
size_t cchMax |
①psz 参数里最大允许的字符数量,包括'�' ②这个数不能超过 STRSAFE_MAX_CCH。 |
|
size_t *pcch |
①psz 参数指向字符串的字符个数,不包括'�',字符串长度返回这参数中。 ②这个值只有在 psz 指针不为 NULL,且函数成功时有效 |
|
返回值 |
①S_OK:psz 指向的字符串不为空,且字符串的长度(包括'�')小于等于 cchMax ②STRSAFE_E_INVALID_PARAMETER:psz 指向空字符串;cchMax 的值大于STRSAFE_MAX_CCH;psz 指向的字符串的字符个数超过 cchMax。 |
④StringCchPrintf——把数据格式化写入到指定的缓冲区里,使用该函数替代以下函数:
Sprintf、swprintf、 _stprintf、wsprintf、wnsprintf、_snprintf、_snwprintf和 _sntprintf等函数
|
参数 |
描述 |
|
LPTSTR pszDest |
指定格式化数据将要写入的缓冲区 |
|
size_t cchDest |
①缓冲区大小,应该设置足够大,以容纳字符串和结束标记(' ') ②最大允许的字符数是 STRSAFE_MAX_CCH |
|
LPCTSTR pszFormat |
①格式化字符串,与 pirntf 的格式化字符串一致 ②这个值只有在 psz 指针不为 NULL,且函数成功时有效 |
|
... |
可变参数,参数的个数取决 pszFormat 参数 |
|
返回值 |
①S_OK:psz 表示有足够的空间将拷贝到 pszDest,没有发生截断 ②STRSAFE_E_INVALID_PARAMETER:cchDest 的值为 0 或大于 STRSAFE_MAX_CCH。 ③STRSAFE_E_INSUFFICIENT_BUFFER:由于缓冲区空间不足而导致的复制失败;结果被截断,当仍然包含'�'结尾;如果截断操作可以被接受,则不一定被看作是失败。 |
(2)StringCcbXXXX函数:其中的Ccb表示目标缓冲区的字节数,可用sizeof(pszDest)求
(3)StringCchXXXXEx和StringCcbEx等扩展版本的函数,(见课本P22页)
2.7 Unicode与ANSI字符串的转换
(1)MultiByteToWideChar——多字节字符串转为Unicode字符串
|
参数 |
描述 |
|
UINT uCodePage |
指定与ANSI字符串关联的代码页。 CP_ACP:指定为当前系统代码页 CP_OEMCP 当前系统OEM代码页 |
|
DWORD dwFlags |
指定如何处理没有转换的字符,一般设为0。 |
|
PCTSTR pMultiByteStr |
要转换的字符串 |
|
int cbMultiByte |
要转换字符串的长度(字节数),当-1时,函数会自动判断源字符串的长度 |
|
PWSTR pWideCharStr |
转换后的Unicode字符串存入的目标缓冲区 |
|
int cchWideChar |
目标缓冲区最大的长度(字符数) |
|
返回值 |
函数失败,返回0,可调用GetLastError函数 函数成功,两种情况: A、cchWideChar设为0,则返回值为转换后宽字符数(含�)。 B、cchWideChar设为非0,返回写入目标缓冲区的字符数(包括字符串结尾的NULL); |
★★转换的步骤
①计算所需目标缓冲区的大小:-先将目标缓冲区为NULL,长度为0,表示不转换只统计。
iSize = MultiByteToWideChar(CP_ACP,0,pMultiByteStr,-1,NULL,0);
②分配iSize*sizeof(wchar_t)大小的目标缓冲区。
③再次调用MultiByteToWideChar(CP_ACP,0,pMultiByteStr,-1, pWideCharStr,iSize);
④使用转换后的字符串
⑤释放Unicode字符串内存块
(2)WideCharToMultiByte——宽字节字符串转为多字节字符串
|
参数 |
描述 |
|
UINT uCodePage |
指定新字符串相关联的ANSI代码页。 CP_ACP:指定为当前系统代码页 CP_OEMCP 当前系统OEM代码页 CP_UTF8:将宽字节转为UTF_8 |
|
DWORD dwFlags |
指定如何处理没有转换的字符,一般设为0。 |
|
PCWSTR pWideCharStr |
要转换的字符串 |
|
int cchWideChar |
要转换字符串的长度(字符数),当-1时,函数会自动判断源字符串的长度 |
|
PSTR pMultiByteStr |
转换后的多字节字符串存入的目标缓冲区 |
|
int cbMultiByte |
目标缓冲区最大的长度(字节数) |
|
pDefaultChar |
在uCodePage指定的代码页中找不到对应的字符时,用该字符来替换,如果设为NULL,则会用系统默认的字符,一般是?替换。 |
|
pfUsedDefaultChar |
转换过程中,如果至少有一个被pDefaultChar指定的字符替换,则这里会被设为TRUE,否则,设为FALSE。可以通过这个变量,验证转换是否成功。该参数一般设为NULL。 |
|
返回值 |
函数失败,返回0,可调用GetLastError函数 函数成功,两种情况: A、cbMultiByte设为0,则返回值为转换后所需的字节数(含�)。 B、cbMultiByte设为非0,返回写入目标缓冲区的字节数(包括字符串结尾的NULL); |
★★转换的步骤——与MultiByteToWideChar相似,唯一不同的是第1 次调用时返回值就是本身所需的字节数,所以无需进行乘法运算。
(3)利用ATL库中的函数来转换字符集
①使用时先#include <atlconv.h>,然后调用宏USES_CONVERSION(只需调用一次)
②宏A2T、A2W、W2T、W2A进行转换
★2表示to,W表示Unicode,A表示ANSI(或MBCS),T表示通用类型(看UNICODE宏)
★使用 ATL 转换宏,在栈上分配内存,由于不用释放临时空间,所以使用起来非常方便。但使用时要注意几点:
A:只适合于进行短字符串的转换;
B:不要试图在一个次数比较多的循环体内进行转换;
C:不要试图对字符型文件内容进行转换,因为文件尺寸一般情况下是比较大的;
D:对情况 B 和 C,要使用 MultiByteToWideChar和 WideCharToMultiByte;
【AnsiAndUnicode】多字节与Unicode之间的转换
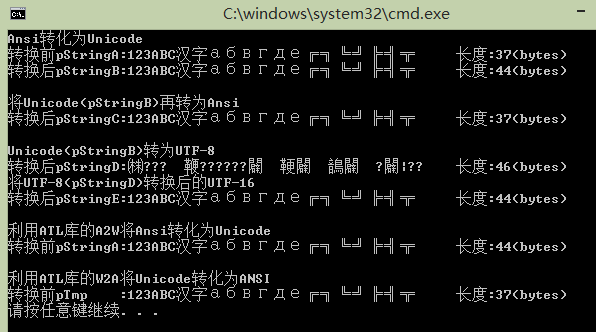
/*------------------------------------------------------------------------------------ 多字节与Unicode之间的转换 -------------------------------------------------------------------------------------*/ #include <windows.h> #include <tchar.h> #include <stdio.h> #include <locale.h> #include <atlconv.h> //ATL库提供了更简便的字符集转换函数 //Ansi转化Unicode TCHAR* AnsiToUnicode(PCSTR pMuliByteStr) { int iCount; TCHAR* pRet; //计算所需缓冲区大小(字符数) iCount = MultiByteToWideChar(CP_ACP, 0, pMuliByteStr,-1,NULL,0);//返回字符个数(含�) pRet = (TCHAR*)malloc(iCount*sizeof(wchar_t)); //分配目标缓冲区大小 MultiByteToWideChar(CP_ACP, 0, pMuliByteStr, -1, pRet, iCount); return pRet; } //Unicode转化Ansi char* UnicodeToAnsi(wchar_t* pWideChar) { int iCount; char* pRet; //计算所需缓冲区大小(字节数) iCount = WideCharToMultiByte(CP_ACP, 0, pWideChar, -1, NULL, 0,NULL,NULL);//返回字节数(含�) pRet = (char*)malloc(iCount); //分配目标缓冲区大小 WideCharToMultiByte(CP_ACP, 0,pWideChar,-1,pRet,iCount,NULL,NULL); return pRet; } //UnicodeToUTF8 char* UnicodeToUTF8(wchar_t* pWideChar) { int iCount; char* pRet; //计算所需缓冲区大小(字节数) iCount = WideCharToMultiByte(CP_UTF8, 0, pWideChar, -1, NULL, 0, NULL, NULL);//返回字节数(含�) pRet = (char*)malloc(iCount); //分配目标缓冲区大小 WideCharToMultiByte(CP_UTF8, 0, pWideChar, -1, pRet, iCount, NULL, NULL); return pRet; } //UTF8转化Unicode TCHAR* UTF8ToUnicode(PCSTR pMuliByteStr) { int iCount; TCHAR* pRet; //计算所需缓冲区大小(字符数) iCount = MultiByteToWideChar(CP_UTF8, 0, pMuliByteStr, -1, NULL, 0);//返回字符个数(含�) pRet = (TCHAR*)malloc(iCount*sizeof(wchar_t)); //分配目标缓冲区大小 MultiByteToWideChar(CP_UTF8, 0, pMuliByteStr, -1, pRet, iCount); return pRet; } int _tmain() { setlocale(LC_ALL, "chs"); //Ansi字符 char pStringA[] = "123ABC汉字абвгде╔╗╚╝╠╣╦"; printf("Ansi转化为Unicode "); printf("转换前pStringA:%s 长度:%d(bytes) ", pStringA,sizeof(pStringA)); wchar_t* pStringB = AnsiToUnicode(pStringA); wprintf(L"转换后pStringB:%s 长度:%d(bytes) ", pStringB,(lstrlenW(pStringB)+1)*sizeof(wchar_t)); printf(" 将Unicode(pStringB)再转为Ansi "); char* pStringC = UnicodeToAnsi(pStringB); printf("转换后pStringC:%s 长度:%d(bytes) ", pStringC, (strlen(pStringC) + 1)); printf(" Unicode(pStringB)转为UTF-8 "); char* pStringD = UnicodeToUTF8(pStringB); wprintf(L"转换后pStringD:%s 长度:%d(bytes) ", pStringD,(strlen(pStringD) + 1)); printf("将UTF-8(pStringD)转换后的UTF-16 "); wchar_t* pStringE = UTF8ToUnicode(pStringD); wprintf(L"转换后pStringE:%s 长度:%d(bytes) ", pStringE, (lstrlenW(pStringE) + 1)*sizeof(wchar_t)); USES_CONVERSION; //要使用ATL库,需调用该宏,只须调用一次。 //使用ATL库进行字符集转换 printf(" 利用ATL库的A2W将Ansi转化为Unicode "); wchar_t* pTmp = A2W(pStringA); wprintf(L"转换前pStringA:%s 长度:%d(bytes) ", pTmp, (lstrlenW(pTmp) + 1)*sizeof(wchar_t)); printf(" 利用ATL库的W2A将Unicode转化为ANSI "); char* pTmpChar = W2A(pTmp); printf("转换前pTmp :%s 长度:%d(bytes) ", pTmpChar, (strlen(pTmpChar) + 1)); free(pStringB); free(pStringC); free(pStringD); free(pStringE); return 0; }
2.8 其他与字符串有关的函数
(1)IsTextUnicode——判断文件是否包含Unicode或ANSI(利用统计规律,并不精确)
|
参数 |
描述 |
|
LPVOID lpBuffer |
要测试的字符串,其缓冲区地址 |
|
int cb |
lpBuffer指向的字节数(注意是不是字符数) |
|
LPINT lpi |
是个in/out类型的,传入时指定哪些测试项目,传出时为符合哪个测试项目。如果为NULL,表示执行每一项测试。 |
|
返回值 |
TRUE或FALSE |
(2)系统本地语言支持(National Language Support)
①GetACP函数:可以检索系统中ANSI代码页标识符。
②GetCpInfo函数:可以得到代码页中的详细信息:最大字符大小、缺省字符、前置符(详见CPINFO结构体)
③IsDBCSLeadByte函数:可以判定所给字符是否是双字节字符的第一个字节。
④获取系统安装的语言版本,系统区域设置等信息
|
函数 |
描述 |
|
GetSystemDefaultLCID |
获取系统默认的区域设置ID;具体可以对照一下:控制面板è区域和语言选项→高级; |
|
GetUserDefaultLCID |
获取当前用户默认的区域设置ID; 具体可以对照一下:控制面板è区域和语言选项→区域选项 |
|
GetLocaleInfo |
根据区域设置ID来获取本地语言名称 |
|
GetSystemDefaultLangID |
取得系统默认ID 对应的国家地区 |
|
GetUserDefaultLangID |
为当前用户取得默认语言ID |
【StringReverse程序】反转字符串(动态链接库中提供ANSI和Unicode两种版本的导出函数)

/*--------------------------------------------------------------------------------------- 导出ANSI和Unicode 动态链接库函数 ---------------------------------------------------------------------------------------*/ #include <windows.h> #include "..ReverseDLLReserveDll.h" #include <tchar.h> #include <stdio.h> //静态调用动态库 #pragma comment(lib,"..\Debug\reverseDll.lib") int _tmain() { //Unicode版的翻转 printf("Unicode版的翻转 "); wchar_t szWideChar[] = L"I am a Student."; printf("翻转前字符串:%ws ", szWideChar); StringReverseW(szWideChar, lstrlenW(szWideChar)); printf("翻转后字符串:%ws ", szWideChar); printf(" ANSI版的翻转 "); char szAnsiBuffer[] = "You are a teacher!"; printf("翻转前字符串:%s ", szAnsiBuffer); StringReserseA(szAnsiBuffer, strlen(szAnsiBuffer)); printf("翻转后字符串:%s ", szAnsiBuffer); int a = sizeof("A"); return 0; }
//reverseDll.h
#pragma once #include <windows.h> #ifdef _cplusplus #ifdef API_EXPORT #define EXPORT extern "C" __declspec(dllexport) //当头文件供动态库本身使用时 #else #define EXPORT extern "C" __declspec(dllimport) //当头文件供调用库的程序使用时 #endif #else #ifdef API_EXPORT #define EXPORT __declspec(dllexport) //当头文件供动态库本身使用时 #else #define EXPORT __declspec(dllimport) //当头文件供调用库的程序使用时 #endif #endif EXPORT BOOL StringReverseW(PWSTR pWideCharStr, DWORD cchLength); EXPORT BOOL StringReserseA(PSTR pMultiByteStr, DWORD cchLength); #ifdef UNICODE #define StringReverse StringReverseW #else #define StringReverse StringReserseA #endif // DEBUG
//reverseDll.c
#define API_EXPORT #include "ReserveDll.h" int WINAPI DllMain(HINSTANCE hInstance, DWORD fdwReason, PVOID pvReserved) { return TRUE; } EXPORT BOOL StringReverseW(PWSTR pWideCharStr, DWORD cchLength) { //获取字符串最后一个字符的指针 PWSTR pEndOfStr = pWideCharStr + wcsnlen_s(pWideCharStr, cchLength) - 1; wchar_t cCharT; //临时变量 //循环直到到达字符串中间的字符 while (pWideCharStr <pEndOfStr) { //交换字符 cCharT = *pWideCharStr; //将变量保存在临时变量中 *pWideCharStr = *pEndOfStr;//交换 *pEndOfStr = cCharT; pWideCharStr++; pEndOfStr--; } return TRUE; } EXPORT BOOL StringReserseA(PSTR pMultiByteStr, DWORD cchLength) { int nLenofWideChar; PWSTR pWideCharStr; BOOL fOk = FALSE; //计算字符的个数以创建容纳Unicode字符串 nLenofWideChar = MultiByteToWideChar(CP_ACP, 0, pMultiByteStr, cchLength, NULL, 0); //在调用进程的默认堆上申请一块不可移动的内存 pWideCharStr = (PWSTR)HeapAlloc(GetProcessHeap(), 0, nLenofWideChar*sizeof(wchar_t)); if (pWideCharStr == NULL) return fOk; //转换为Unicode字符串 MultiByteToWideChar(CP_ACP, 0, pMultiByteStr, cchLength, pWideCharStr, nLenofWideChar); //调用StringReverseW函数进行实际的转换 fOk = StringReverseW(pWideCharStr,cchLength); if (fOk) { //将Unicode再转换为Ansi WideCharToMultiByte(CP_ACP, 0, pWideCharStr, cchLength, pMultiByteStr, (int)strlen(pMultiByteStr), NULL, NULL); } //释放内存 HeapFree(GetProcessHeap(), 0, pWideCharStr); return fOk; }