数字类型
整型int
用途: 记录年龄等级各种号码
定义方式:

age=18
age=int(18)
x=int('123') #只能将纯数字的字符串转换成整型
print(type(x))
print(int(3.7)) #这个小数部分没有了
常用操作+内置的方法( 赋值比较算术)
该类型总结: 存一个值 ; 不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
判断是否哈希
print(hash(10))
print(hash([1,2,3]))
浮点型float
用途: 记录身高体重薪资
定义方式
salary=1.3
#salary=float(1.3)
x=float('3.1')
print(x,type(x))
常用操作+内置的方法
赋值比较算术
该类型总结: 存一个值 ; 不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
x=3.1
print(id(x))
x=3.2
print(id(x))
了解:
#复数
x=1-2j
print(x,type(x))
print(x.real)
print(x.imag)
#长整型
#不常见,知道有这个东西就行,至于到哪一位属于长整形,没必要了解
其他进制=>十进制
十进制: 0-9
11 = 1*10^1 + 1*10^0
二进制: 0 1
11 = 1*2^1 + 1*2^0
八进制: 0-7
11 = 1*8^1+1*8^0
十六进制:0-9 A-F
11 = 1*16^1+1*16^0
十进制=>其他进制
print(bin(13)) # 十进制=>二进制
print(oct(13)) # 十进制=>八进制
print(hex(13)) # 十进制=>十六进制
字符串类型
基本使用
用途:记录描述性质的特征,比如名字地址性别
定义方式:在单引号双引号三引号内包含的一串字符
msg='aaa"bbb"'
#msg=str(...)
可以将任意类型转换成字符串
str(1)
str(1.3)
x=str([1,2,3])
print(x,type(x))
常用操作+内置的方法
#strip 方法用于移除字符串头尾指定的字符(默认为空格)。 #str.strip([chars]); # chars移除字符串头尾指定的字符。 这是一个包含的关系 name = "*joker**" print(name.strip("*")) print(name.lstrip("*")) #去除左边 print(name.rstrip("*")) #去除右边 #长度len msg='你好啊a' print(len(msg)) #成员运算in和not in msg='yangyuanhu 老师是一个非常虎的老师' print('yangyuanhu' in msg) print('虎' not in msg) print(not '虎' in msg) #format的三种玩法 一种格式化输出的手段 print('my name is %s my age is %s' %('egon',18)) print('my name is %s my age is %s' %(18,'egon')) print('my name is {name} my age is {age} '.format(age=18,name='egon')) 了解 print('my name is {} my age is {} '.format(18,'egon')) print('my name is {0} my age is {1} '.format(18,'egon')) print('my name is {1} my age is {0} '.format(18,'egon')) #replace name = "joker is good joker boy!" print(name.replace('joker','li')) #所有joker替换li print(name.replace('joker','li',1)) #从左到右只替换1次 #split 字符串切分,切分的结果是列表 name = 'root:x:0:0::/root/:bin/bash' print(name.split(':')) #默认分隔符为空格 name = 'c:/a/b/c/d.txt' #想拿到顶级目录 print(name.split('/',1)) #按多少次切片,从左边 name = 'a|b|c' print(name.rsplit('|',1)) #按多少次切片,从右边 #join 有切分就有拼接,不过join只能拼接字符串(其他类型会报错),会形成一个新的字符串 tag = ' ' print(tag.join(['joker','li','good','boy'])) #可迭代对象必须都是字符串 #也就是说这个方法是将列表转换为字符串,如果tag有变量的话,就会循环加 #startswith,endswith name = "joker_li" print(name.endswith("li")) #判断是否以什么结尾 print(name.startswith("joker")) #判断是否以什么开头 #find,rfind,index,rindex,count name = 'jokerk say hi' print(name.find('s'))#find()是从字符串左边开始查询子字符串匹配到的第一个索引,找不到不会报错会返回-1 print(name.count('k')) #统计包含有多少个 print(name.rfind('s')) # rfind()是从字符串右边开始查询字符串匹配到的第一个索引 print(name.index('s')) #index方法是在字符串里从左边查找子串第一次出现的位置,类似字符串的find方法, # 不过比find方法更好的是,如果查找不到子串,会抛出异常,而不是返回-1 #center,ljust,rjust,zfill name = 'joker' print(name.center(10,'_')) #不够10个字符,用_补齐 print(name.ljust(10,'*')) #左对齐 print(name.rjust(10,'*')) #右对齐,注意这个引号内只能是一个字符 print(name.zfill(10)) #右对齐,用0补齐()控制0的数量 #expandtabs name = 'joker hello' print(name) print(name.expandtabs(4)) #expand扩张的意思,就是将tab建转为多少个空格 #lower,upper name = 'joker' print(name.lower()) #大写变小写,如果本来就是小写,那就没变化 print(name.upper()) #小写变大写,如果本来就是大写,那就没变化 #capitalize,swapcase,title name = 'joker li' print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写对调 print(name.title()) #每个单词的首字母大写 #expandtabs print('hello world'.expandtabs(5)) #hello与world直间打印了5个空格 #is数字系列 num1 = b'4' #bytes 类型 print(type(num1)) num2 = u'4' #unicode类型,在3里默认就是这个类型 print(type(num2)) num3 = '四' #中文数字 num4 = 'Ⅳ' #罗马数字 #isdigt,bytes,unicode print(num1.isdigit()) #是不是一个整数数字,如果是浮点数就会False print(num2.isdigit()) print(num3.isdigit()) #False print(num4.isdigit()) #罗马数字 False ,不是一个整数 #isdecimal,uncicode #bytes类型无isdecimal方法 print(num2.isdecimal()) #检查字符串是否只包含十进制字符。这种方法只存在于unicode对象 #注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可 print(num3.isdecimal()) print(num4.isdecimal()) #isnumberic:unicode,中文数字,罗马数字 #bytes类型无isnumberic方法 print(num2.isnumeric()) #判断是不是数字,包括中文大写数字,罗马数字等 print(num3.isnumeric()) print(num4.isnumeric()) #三者不能判断浮点数 num5='4.3' #全是false print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric()) # 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 # 如果要判断中文数字或罗马数字,则需要用到isnumeric #is print('===>') name='joker123' print(name.isalnum()) #字符串由字母和数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isidentifier()) #判断是不是一个合法的表示符 print(name.islower()) #判断是不是小写 print(name.isupper()) #是不是大写 print(name.isspace()) #判断是不是空格 print(name.istitle()) #每个单词字母首字母大小
该类型总结:存一个值 ;有序 ; 不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
列表类型
基本使用
用途:记录多个值,比如人的多个爱好
定义方式: 在[]内用逗号分隔开多个任意类型的值
li=[1,2,3] # li=list([1,2,3]) x=list('hello') x=list({'a':1,'b':2,'c':3}) print(x)
常用操作+内置的方法
按索引存取值(正向存取+反向存取):即可存也可以取
li=['a','b','c','d']
print(li[-1])
li[-1]='D'
print(li)
li[4]='e'
del li[0]
print(li)
切片
切片的语法:
list[start:end:step] start:起始位置 end:结束位置 step:步长 其中步长可有可无 对于冒号的使用: [m : ] 代表列表中的第m+1项到最后一项 [ : n] 代表列表中的第一项到第n项 [::-1] 可以视为翻转操作 [::2] 隔一个取一个元素的操作 顾头不顾尾是指结束位置的元素不取,只取到前面一个元素
长度
print(len(li))
成员运算 in 和 not in
users=['egon','lxx','yxx','cxxx',[1,2,3]]
print('lxx' in users)
print([1,2,3] in users)
print(1 in users)
追加
li=['a','b','c','d']
print(id(li))
li.append('e')
li.append([1,2,3])
print(li,id(li))
删除
li=['a','b','c','d']
#按照元素值去单纯地删除某个元素
del li[1]
res=li.remove('c')
print(li)
print(res)
#按照元素的索引去删除某个元素并且拿到该元素作为返回值
res=li.pop(1)
print(li)
print(res)
循环
li=['a','b','c','d'] for item in li: print(item)
切片赋值和插入
作用:可以改变原列表的排序,可以插入和修改数据
可以用切片改变列表的对应元素的值
语法:
列表[切片] = 可迭代对象
注: 赋值运算符的右侧必须是一个可迭代对象
示例:
L = [2, 3, 4]
L[0:1] = [1.1, 2.2]
#L = [1.1,2.2,3,4]
L = [2, 3, 4]
L[1:] = [3.3, 4.4, 5.5]
#L=[2,3.3,4.4,5.5] #改变了切片后面的值,没有个数限制,统统加到原来的列表中
L = [2, 3, 4]
L[:] = [0, 1]
# L = [0, 1]
L = [2, 4]
L[1:1] = [3.1, 3.2]
# L = [2,3.1,3.2,4] # 实现中间插入 [3.1, 3.2]
L = [2,3,4]
L[0:0] = [0, 1] # 实现在前面插入[0,1]
L = [2,3,4]
L[3:3] = [5, 6] # 实现在后面插入[5,6]
#L[4:4] = [5, 6] #这种也能实现后面插入 切片里面索引值是可以超过列表本身的
L = [1,4]
L[1:1] = range(2,4) #用range函数生成的可迭代对象赋值
L = [2,3,4]
L[1:2] = "ABCD" # "ABCD"也是可迭代对象
# 切片赋值注意事项:
# 对于步长不等于1的切片赋值,赋值运算符右侧的可迭代对象提供的元素个数一定要等于切片切出的段数
L = [1, 2, 3, 4, 5, 6]
print(L[::2])
L[::2] = "ABC" # 对的 意思是从头到尾按步长为2赋值 "ABC"可以看作三个元素
print(L)
'''[1, 3, 5]
['A', 2, 'B', 4, 'C', 6]
'''
# # 以下切出三段,但给出5个元素填充是错的
L[::2] = "ABCDE"
print(L)
该类型总结:存多个值 ;有序 ; 可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
print(hash([1,2,3]))
列表常用方法
li=['a','b','c','d','c','e']
print(li.count('c')) #计算li中字符c的个数
li.extend([1,2,3]) #把括号里列表里的元素添加到li
li.append([1,2,3]) #把括号里的列表增加到列表末尾
print(li)
print(li.index('z')) #打印出z的索引值
print(li.index('b'))
print(li.index('d',0,3))
li.insert(1,'egon') #在索引值1处插入字符串egon
print(li)
li=[3,1,9,11]
li.reverse() #翻转列表的顺序
print(li)
li.sort(reverse=True) #按照数字或字母顺序排序
print(li)
练习,模拟堆栈和队列
队列: 先进先出
q=[]
入队
q.append('first')
q.append('second')
q.append('third')
print(q)
出队
print(q.pop(0))
print(q.pop(0))
print(q.pop(0))
堆栈: 先进后出
q=[]
入栈
q.append('first')
q.append('second')
q.append('third')
出栈
print(q.pop(-1))
print(q.pop(-1))
print(q.pop(-1))
元组类型
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表,用于存放多个值,当存放的多个值只有读的需求没有改的需求时用元组最合适
定义方式 : 在()内用逗号分隔开多个任意类型的值
t=(1,3.1,'aaa',(1,2,3),['a','b']) # t=tuple(...)
print(type(t))
res=tuple('hello')
res=tuple({'x':1,'y':2})
print(res)
元组的另外一种建立方式
用逗号建立一个元组,就是这么神奇
# res='dsb',
#('dsb',)
res='dsb','yyh'
print(res)
#('dsb', 'yyh')
在后面项目中遇到的坑
# 处理数据库的连接
class Connection:
# 目前的连接数
current_connect_count = 0
host = "127.0.0.1",
user = "root",
password = "root",
database = "ormtest",
charset = "utf8",
autocommit = True
def create_conn(self):
pass
# 在定义类的时候,在共有属性后面加上逗号,就成了元组,不用逗号才是正常的类型
print(Connection.host,Connection.database)
print(type(Connection.current_connect_count))
常用操作+内置的方法
优先掌握的操作:
按索引取值(正向取+反向取):只能取
t=('a','b',1)
t[0]=111
切片(顾头不顾尾,步长)
t=('h','e','l','l','o')
res=t[1:3]
print(res)
print(t)
长度
t=('h','e','l','l','o')
print(len(t))
成员运算in和not in
t=('h','e','l','l','o')
print('h' in t)
循环
t=('h','e','l','l','o')
for item in t:
print(item)
该类型总结 :存多个值,有序,不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
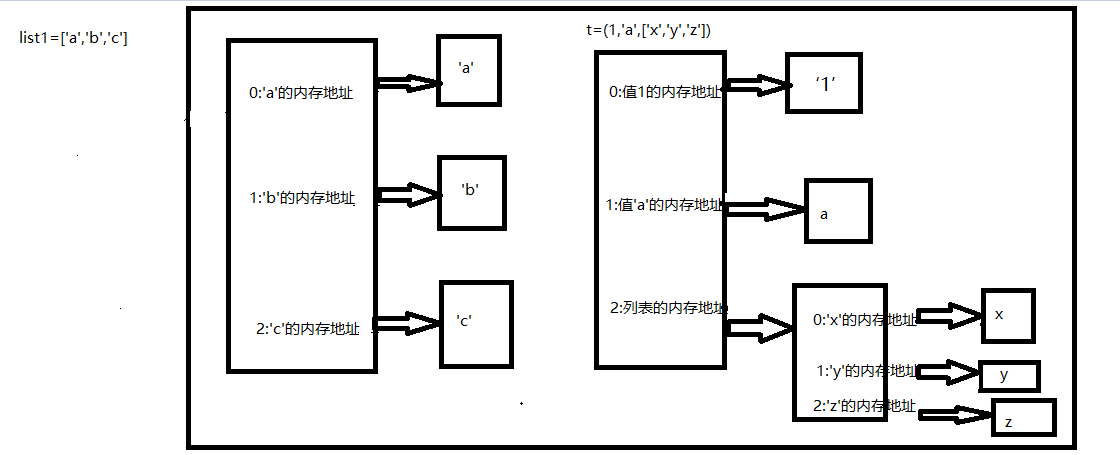
t=(1,'a',['x','y','z'])
# print(id(t[2]))
# print(id(t))
t[2][0]='X'
print(t)
print(id(t))
print(id(t[2]))
list1=['a','b','c']
print(id(list1[0]))
print(id(list1[1]))
print(id(list1[2]))
print('='*50)
list1[1]='B'
print(id(list1[0]))
print(id(list1[1]))
print(id(list1[2]))
t=('a','b','a')
print(t.index('a'))
t.index('xxx')
可变类型与不可变类型图解分析
字典类型
字典的特性:
- dict 是无序的
- key 必须是唯一的,不能重复
常用操作+内置的方法
增加
info={'stu1102': 'LongZe Luola', 'stu1104': '苍井空'}
info['huahuagongzi']='lengdigaga' #只要对应字典的键值对就能增加
print(info)
修改

>>> info['stu1101'] = "武藤兰"
>>> info
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
删除
>>> info
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
>>> info.pop("stu1101") #标准删除姿势
'武藤兰'
>>> info
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
>>> del info['stu1103'] #换个姿势删除
>>> info
{'stu1102': 'LongZe Luola'}
>>>
>>>
>>>
>>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
>>> info
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} #随机删除
>>> info.popitem()
('stu1102', 'LongZe Luola')
>>> info
{'stu1103': 'XiaoZe Maliya'}
查找
>>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
>>>
>>> "stu1102" in info #标准用法
True
>>> info.get("stu1102") #获取
'LongZe Luola'
>>> info["stu1102"] #同上,但是看下面
'LongZe Luola'
>>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'stu1105'
多级字典嵌套及操作
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来"
print(av_catalog["大陆"]["1024"])
#ouput
['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
其他操作
#values >>> info.values() dict_values(['LongZe Luola', 'XiaoZe Maliya']) #keys >>> info.keys() dict_keys(['stu1102', 'stu1103']) #items info={'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} info_new=info.items() #Python 字典 items() 方法以列表返回可遍历的(键, 值) 元组数组 print(info_new,type(info_new)) #返回可遍历的(键, 值) 元组数组 #setdefault #setdefault:key不存在则设置默认值,并且将默认值添加到values中 #key存在则不设置默认,并且返回已经有的值 >>> info.setdefault("stu1106","Alex") 'Alex' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} >>> info.setdefault("stu1102","龙泽萝拉") 'LongZe Luola' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #update >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} >>> b = {1:2,3:4, "stu1102":"龙泽萝拉"} >>> info.update(b) >>> info {'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #fromkeys() 用于创建一个新的字典,其中包含seq的值和设置为value的值。 语法 dict.fromkeys(seq[, value])) 参数 seq - 这是用于字典键准备的值的列表。 value - 这是可选的,如果提供,则值将被设置为此值。 返回值 此方法返回值的列表。 #!/usr/bin/python3 seq = ('name', 'age', 'sex') dict = dict.fromkeys(seq) print ("New Dictionary : %s" % str(dict)) dict = dict.fromkeys(seq, 10) print ("New Dictionary : %s" % str(dict)) 当运行上面的程序,它产生以下结果 - New Dictionary : {'age': None, 'name': None, 'sex': None} New Dictionary : {'age': 10, 'name': 10, 'sex': 10}
循环dict
info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
for key in info: #默认遍历字典的键
print(key,info[key])
字典内置函数
len(dict) #计算字典元素个数,即键的总数。 str(dict) #输出字典可打印的字符串表示。 type(variable) #返回输入的变量类型,如果变量是字典就返回字典类型
字典内置方法
radiansdict.clear() #删除字典内所有元素 radiansdict.copy() #返回一个字典的浅复制 radiansdict.fromkeys() #创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 radiansdict.get(key, default=None) #返回指定键的值,如果值不在字典中返回default值 radiansdict.has_key(key) #如果键在字典dict里返回true,否则返回false radiansdict.items() #以列表返回可遍历的(键, 值) 元组数组 radiansdict.keys() #以列表返回一个字典所有的键 radiansdict.setdefault(key, default=None) #和get()类似, 但如果键不已经存在于字典中,将会添加键并将值设为default radiansdict.update(dict2) #把字典dict2的键/值对更新到dict里 radiansdict.values() #以列表返回字典中的所有值
集合
a = t | s # t 和 s的并集
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
# set 无序,不重复序列
# 创建
# se = {'123',345}
# print(type(se))
# s = set() # 创建一个空集合
# # 对比,之前我们把元祖转换成列表的方法
# l = list((1,2,3))
# print(l) # [1, 2, 3] 实际里面运行了for循环,也就是init方法
#
# s1 = set(l)
# print(s1) # {1, 2, 3} 集合还有一个机制就是,如果有相同的就会去除
# 功能
# s = set()
# s.add(1)
# s.add(1)
# print(s) # {1}
# s.clear()
# print(s) # 清空
# 差集
s1 = {11,22,33}
s2 = {22,33,44}
# s3= s1.difference(s2) # s1中存在,s2中不存在 {11}
# s1.difference_update(s2) 更新到s1里面,不需要创建新的集合
# print(s3)
# 对称差集
# s3 = s1.symmetric_difference(s2) # 对称差集 {11, 44}
# s1.symmetric_difference_update(s2) 更新到s1里面,不需要创建新的集合
# print(s3)
# 删除
# s1.discard(11)
# print(s1) # {33, 22} 移除指定元素,不存在不报错
# s1.remove(11)
# print(s1) {33, 22} ,不存在报错
# ret = s1.pop() 随机的,有返回值
# print(ret)
# 交集
# ret = s1.intersection(s2)
# print(ret) {33, 22}
# s1.intersection_update(s2)
# ret = s1.isdisjoint(s2)
# print(ret) # 没有交集返回true,有交集返回true
# s1.issubset() # 是否是子序列,包含的关系
# s1.issuperset() # 是否是父序列,被包含的关系
# 并集
# ret = s1.union(s2)
# print(ret) {33, 22, 11, 44} 并集
# li = [1,2,3]
# s1.update(li) # 接收一个可迭代的相比add,它可以添加个序列,并且循环执行add
#
# print(s1) # {33, 2, 3, 1, 11, 22}
什么是集合
在{}内用逗号分隔开多个值,集合的特点:
每个值必须是不可变类型
集合无序
集合内元素不能重复
为何要用集合
用于做关系运算
去重
集合的第一大用途: 关系运算
pythons={'egon','张铁蛋','李铜蛋','赵银弹','王金蛋','艾里克斯'}
linuxs={'欧德博爱','李铜蛋','艾里克斯','lsb','ysb','wsb'}
求同时报名两门课程的学生姓名:交集
print(pythons & linuxs)
print(pythons.intersection(linuxs))
pythons=pythons & linuxs
print(pythons) #{'李铜蛋', '艾里克斯'}
pythons.intersection_update(linuxs) #pythons=pythons.intersection(linuxs)
print(pythons) #{'艾里克斯', '李铜蛋'}
求报名学校课程的所有学生姓名:并集
print(pythons | linuxs)
print(pythons.union(linuxs))
求只报名python课程的学生姓名: 差集
print(pythons - linuxs)
print(pythons.difference(linuxs))
print(linuxs - pythons) #求只报名linux课程的学生姓名
print(linuxs.difference(pythons))
求没有同时报名两门课程的学生姓名: 对称差集
print((pythons - linuxs) | (linuxs - pythons))
print(pythons ^ linuxs)
print(pythons.symmetric_difference(linuxs))
父子集:指的是一种包含与被包含的关系
s1={1,2,3}
s2={1,2}
print(s1 >= s2)
print(s1.issuperset(s2))
print(s2.issubset(s1))
情况一:
print(s1 > s2) #>号代表s1是包含s2的,称之为s1为s2的父集
print(s2 < s1)
情况二:
s1={1,2,3}
s2={1,2,3}
print(s1 == s2) #s1如果等于s2,也可以称为s1是s2的父集合
综上:
s1 >= s2 就可以称为s1是s2的父集
s3={1,2,3}
s4={3,2,1}
print(s3 == s4)
s5={1,2,3}
s6={1,2,3}
print(s5 >= s6)
print(s6 >= s5)
集合的第二大用途:去重
集合去重的局限性:
1. 会打乱原值的顺序
2. 只能针对不可变的值去重
stus=['egon','lxx','lxx','alex','alex','yxx']
new_l=list(set(stus))
print(new_l)
old_l=[1,[1,2],[1,2]]
set(old_l)
l = [
{'name': 'egon', 'age': 18, 'sex': 'male'},
{'name': 'alex', 'age': 73, 'sex': 'male'},
{'name': 'egon', 'age': 20, 'sex': 'female'},
{'name': 'egon', 'age': 18, 'sex': 'male'},
{'name': 'egon', 'age': 18, 'sex': 'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
需要掌握的操作
s1.update({3,4,5})
print(s1)
print(s1.pop())
print(s1)
s1.remove(2)
print(s1)
s1={1,2,3}
print(id(s1))
s1.add(4)
print(s1)
print(id(s1))
s1={1,2,3}
s1.discard(4) 移除指定元素,不存在不报错
s1.remove(4) print(s1) s1={1,2,3} s2={4,5} print(s1.isdisjoint(s2))
总结 : 存多个值 ; 无序 ; set可变
布尔值
所有数据类型都自带布尔值
1、None,0,空(空字符串,空列表,空字典等)三种情况下布尔值为False
2、其余均为真
数据类型总结
按存储空间的占用分(从低到高):
数字
字符串
集合:无序,即无序存索引相关信息
元组:有序,需要存索引相关信息,不可变
列表:有序,需要存索引相关信息,可变,需要处理数据的增删改
字典:无序,需要存key与value映射的相关信息,可变,需要处理数据的增删改
按存值个数区分:
标量/原子类型:数字,字符串
容器类型:列表,元组,字典
按可变不可变区分
可变 列表,字典
不可变 数字,字符串,元组
按访问顺序区分
直接访问 数字
顺序访问(序列类型) 字符串,列表,元组
key值访问(映射类型) 字典