一年前就已经用过restframework, 当时觉得这个只是给web框架打辅助的, 他能实现的我也都实现(可能没有那么好用, 嘿嘿)
但是我有一种东西叫做效率, 时间就是金钱, 别人造好的就直接用就可以了, 自己其实没必要在去重复.
最近写一个调查问卷系统, 利用了以下知识点
1. django
2. restframework(重点重点重点)
3. Vue
4. axios
5. ..............
从这个项目中我对restframework有了重新的认识, 互联网的精神就是共享, 所以就分享出来了
restframework的序列化器
当项目的架构为前后端分离时, 前后端的数据交互就变的尤为的重要, restframework的序列化过程无外乎一下6步:
1. 获取数据集合(queryset)
2. 获取序列化器
3. 过滤, 排序
4. 分页
5. 对处理好的数据进行进行序列化
5. 响应序列化结果
这些都是最基本的步骤, 但是在每一步中都蕴藏了大量的小技术, 利用这些小技术, 也许你正在头疼的一小问题就能找到答案, 哈哈, 细节决定成败
选择性的对字段进行序列化
官方是这样说的
For example, if you wanted to be able to set which fields should be used by a serializer at the point of initializing it, you could create a serializer class like so
王氏翻译: 例如,如果您希望能够在初始化序列化器时设置序列化器应该使用哪些字段,您可以创建这样的序列化器类:
这个类就长这样
class DynamicFieldsModelSerializer(serializers.ModelSerializer): """ A ModelSerializer that takes an additional `fields` argument that controls which fields should be displayed. """ def __init__(self, *args, **kwargs): # Don't pass the 'fields' arg up to the superclass fields = kwargs.pop('fields', None) # Instantiate the superclass normally super(DynamicFieldsModelSerializer, self).__init__(*args, **kwargs) if fields is not None: # Drop any fields that are not specified in the `fields` argument. allowed = set(fields) existing = set(self.fields) for field_name in existing - allowed: self.fields.pop(field_name)
之后你的序列化器就可以继承这个类了, 但是要注意这个类是在ModelSerializer之上的
下面就是使用方法
序列化器
class BookSerializers(DynamicFieldsModelSerializer): class Meta: model = models.Book fields = "__all__"
在视图中使用序列化器
class TestView(APIView): def get(self, request, *args, **kwargs): queryset = models.Book.objects.all() serializer = serializers.BookSerializers(queryset, many=True, fields=("id", "title", "price")) # fields: 指定要序列化的字段 return Response(serializer.data)
自定义field
虽然内置有很多的字段类型, 但是从实际的开发角度来说, 内置的都是一些普遍使用的字段, 再生产环境中结合实际问题, 那就需要我们自己定义字段了
现在就有一种实际需求
公司购买了多台CDN服务器, 从来存放图片等静态资源, 现在有一个问题, 假如某一天公司换了CDN, 那么之前代码中的图片链接都要修改一遍吗, 肯定不行
其实解决这个问题的方法有多种, 下面就使用自定义字段来解决这个问题
1. 创建一个自定义字段
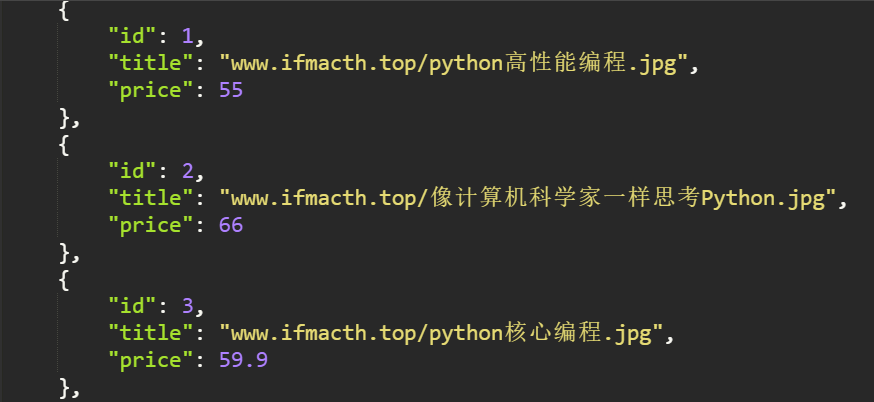
class ImagePathField(fields.Field): def __init__(self, cdn_host, *args, **kwargs): super(ImagePathField, self).__init__(*args, **kwargs) self.cdn_host = cdn_host # 封装CDN主机 def to_representation(self, value): """ 序列化时这个方法会被执行 :param value: :return: """ return "{}/{}".format(self.cdn_host, value) # 构建完整的链接地址, 返回值将作为数据源 def to_internal_value(self, data): pass
2. 在序列化器中使用自定义的字段
class BookSerializers(DynamicFieldsModelSerializer): title = fields.ImagePathField(settings.CND_HOST) # 使用自定义的字段, 还可以传递source参数, 就相当于执行ORM, 写什么就对这个对象"."什么 class Meta: model = models.Book fields = "__all__"
3. 验证序列化结果
方法字段
除了上面的自定义字段, 还有一种方法字段方法字段, 这种字段也能够起到自定义的效果
1. 在序列化器中使用方法字段
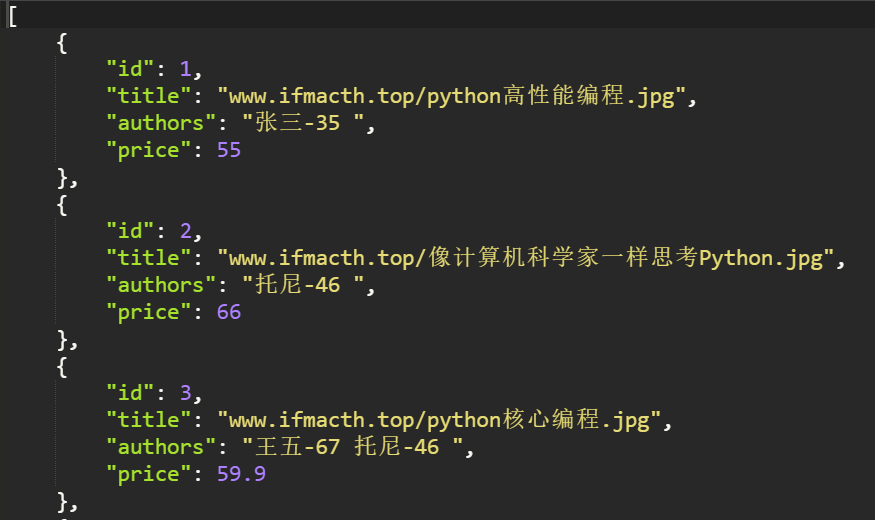
class BookSerializers(DynamicFieldsModelSerializer): authors = serializers.SerializerMethodField() # 使用方法字段 class Meta: model = models.Book fields = "__all__" def get_authors(self, value): """ 对authors这个字段进行序列化时, 会调用get_字段这个方法, 这个方法的返回值将作为数据源 :param value: :return: """ author_str = "" for author in value.authors.all(): author_str += "%s-%s " % (author.name, str(author.age)) return author_str
2. 在视图中对数据进行序列化
class TestView(APIView): def get(self, request, *args, **kwargs): queryset = models.Book.objects.all() serializer = serializers.BookSerializers(queryset, many=True, fields=("id", "title", "price", "authors")) # fields: 指定要序列化的字段 return Response(serializer.data)
3. 验证序列化结果
内置的时间字段 DateTimeField
在处理时间数据时, 让人头疼就是时间的格式, 不同的位置可能显示的格式不一样, 在DRF中内置了时间字段, 可以对时间数据做格式化
1. 在序列化器中使用时间字段
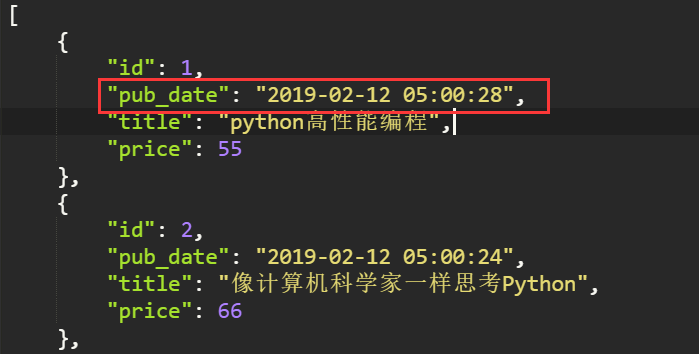
class BookSerializers(DynamicFieldsModelSerializer): pub_date = serializers.DateTimeField(format="%Y-%m-%d %X") # 使用时间字段, 指定时间格式 class Meta: model = models.Book fields = "__all__"
2. 验证序列化结果
内置字符串字段 CharField
字符串是用的最多的数据类型, 当你需要从一个ORM对象关联的另外一种表中取某某一个字段时, 那么你就可以使用CharField
1. 在序列器中使用CharField
很重要的一个参数就是source, 他可以执行ORM操作
还有一个参数就会default, 可以给一个默认值
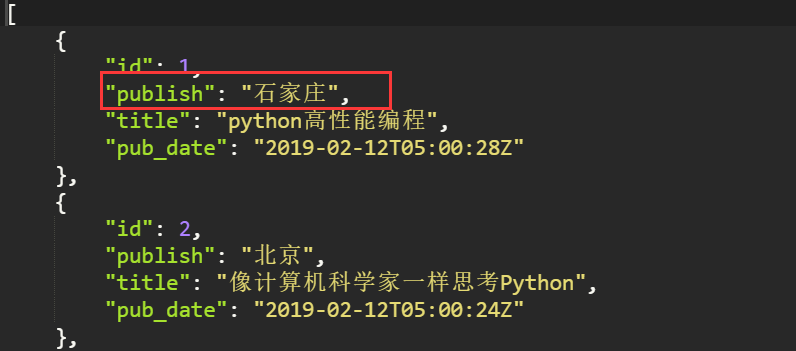
class BookSerializers(DynamicFieldsModelSerializer): publish = serializers.CharField(source="publish.address") # source默认就是publish, 不需要写, 使用"."的方式进行ORM操作 class Meta: model = models.Book fields = "__all__"
2. 验证序列化结果
嵌套的序列化器
当表结构很深的时候, 构建数据往往是很麻烦的事情, 而且考虑到网络传输的效率问题, 还要尽量的减少无用的数据传输, 只传输必须的数据
这样一来就需要在序列化的时候下功夫了.
ORM有外键和多对多, 一对一等数据类型, 对比着序列化器, 就是序列化一个元素, 序列化多个元素而已
下面是我在调查问卷系统中的一个嵌套的序列化器
class ChoicesSerializer(DynamicFieldsModelSerializer): """ 4. 用于获取问题所对应的选项的答案和答案所对应的分值的序列化器 """ class Meta: model = models.SurveyChoices fields = "__all__" class QuestionSerializer(DynamicFieldsModelSerializer): """ 3. 获取问卷调查模板的所有问题 """ survey = serializers.SerializerMethodField() survey_item = serializers.IntegerField(source="pk") choices = ChoicesSerializer(source="answers", many=True, fields=("content", "points")) # fields: 指定要序列化的字段 value = serializers.CharField(default="") error = serializers.CharField(default="") class Meta: model = models.SurveyItem fields = ( "survey", # 问题所属的调查问卷模板id "survey_item", # 问题的id "name", # 问题内容 "answer_type", # 问题的类型 "choices", # 如果是选择题, 对应的选项 "value", # 答案 "error", # 用作于提示的错误信息 ) def get_survey(self, instance): """ :param instance: :return: """ return self.context.get("survey_id") class SurveysSerializers(DynamicFieldsModelSerializer): """ 2. 获取调查问卷使用的问卷模板 """ questions = serializers.ListSerializer(child=QuestionSerializer()) class Meta: model = models.Survey fields = ( "id", # 问卷模板的id "name", # 问卷模板的名称 "questions", # 该问卷模板关联的所有问题 ) def to_representation(self, instance): """ :param instance: :return: """ self.context["survey_id"] = instance.pk data = super(SurveysSerializers, self).to_representation(instance) return data class GetQuestionnaireDetailSerializers(DynamicFieldsModelSerializer): """ 1. 获取调查问卷详情页的序列化器的入口 """ surveys = SurveysSerializers(many=True) class Meta: model = models.MiddleSurvey fields = ( "name", # 调查表的名字 "surveys", # 本次调查表使用的所有问题模板 )
看着代码挺多, 其实套路都是一样
当要序列化的字段是一个外键关系时, 就给这个字段指定另外一个序列化器,
如果是多对多, 那么序列化器中就需要指定many=True, 否则就不用.
和正常的使用序列化器一样
上面说的是序列化, 还有反序列化, 同样可以使用嵌套序列化器