1、首先是安装python(注意python3.X和python2.X是不兼容的,我们最好用python3.X)
安装方法:安装python
2、安装成功后,再进行我们需要的插件安装。(这里我们需要用到requests和pymssql两个插件re是自带的)注:这里我们使用的是sqlserver所以安装的是pymssql,如果使用的是mysql可以参考:安装mysql驱动
安装插件的方法为
安装pymssql->进入命令行输入命令:pip install pymssql
安装requests->进入命令行输入命令:pip install requests
可以通过命令pip list来查看是否安装成功。
3、安装完成后,我们编写代码如下:
import requests from requests.exceptions import RequestException import re import pymssql #通过url获得页面内容 def get_one_page(url): try: response = requests.get(url)
#解决乱码问题
response.encoding = response.apparent_encoding if response.status_code == 200: return response.text return None except RequestException: return None #通过正则表达式抓取我们所需要的页面内容 def parse_one_page(html): pattern = re.compile('<div class="newBox">.*?src="(.*?)".*?<h4>.*?<div class="fp_subtitle">.*?>(.*?)</a></div>.*?</h4>.*?<p>(.*?)</p>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?</div>',re.S) items = re.findall(pattern,html) return items; #数据库连接 def db_conn(): server = '192.168.6.111mssqlzf' user = 'sa' password = 'sa@2016' database = 'zfnewdb' return pymssql.connect(server, user, password, database) #定义main() def main(): conn = db_conn() url = 'http://www.stdaily.com/cxzg80/index.shtml' html = get_one_page(url) cursor = conn.cursor() #将抓取回来的数据循环插入到数据库中,注意:parse_one_page返回的数据类型为 for item in parse_one_page(html): cursor.execute("INSERT INTO tblGrabNews VALUES (%s,%s,%s,%s,%s,%s)",(item[1], item[2], item[0], item[5], item[3], item[4])) conn.commit() conn.close() #执行main() if __name__ == '__main__': main()
注意,parse_one_page(html)函数返回的数据类型如下:[(),(),()...],所以上面程序要的for循环才会那么去写,如果不知道什么是list和tuple的同学可以看一下这篇文章list和tuple。

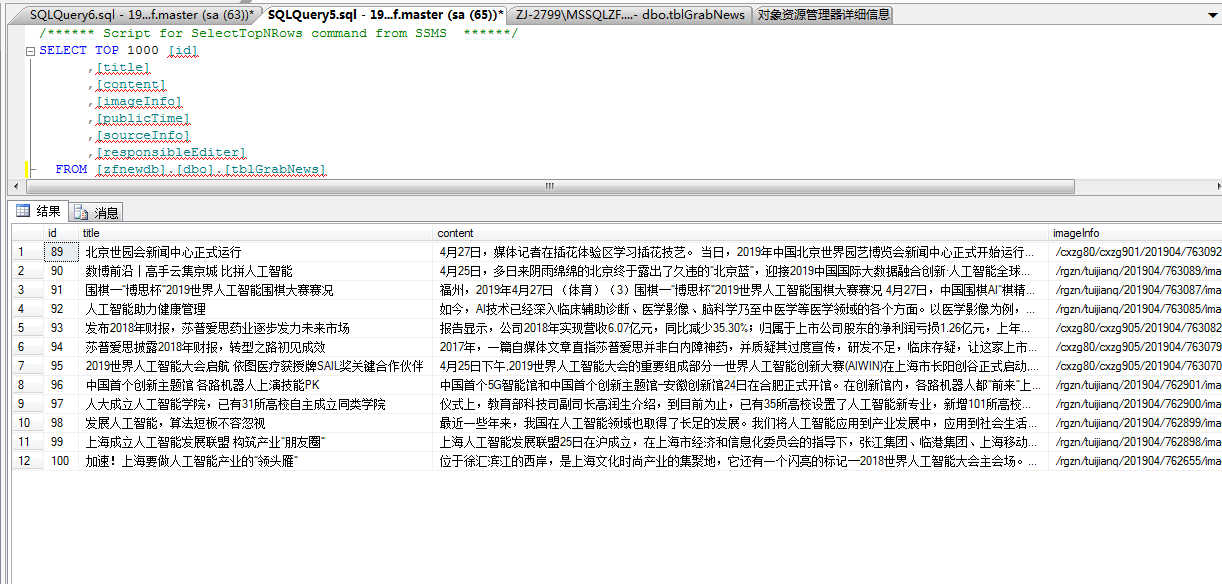
运行上述代码后,可在数据库中看到爬下来的数据。
数据表结构为:
create table [zfnewdb].[dbo].[tblGrabNews] (
id int identity (1,1) primary key,
title varchar(255),
content text,
imageInfo text,
publicTime varchar(100),
sourceInfo varchar(100),
responsibleEditer varchar(100)
)
希望能帮助到有需要的人。