A Loss Function for Learning Region Proposals
训练RPN时,只对两种anchor给予正标签:和gt_box有着最高的IoU && IoU超过0.7。如果对于
所有的gt_box,其IoU都小于0.3,则标记为负。损失函数定义如下:

其中i为一个mini-batch中某anchor的索引,pi表示其为目标的预测概率,pi*表示gt_box(正为1,否则为0)。
ti和ti*分别表示预测框的位置和gt_box框的位置。Lreg如下:
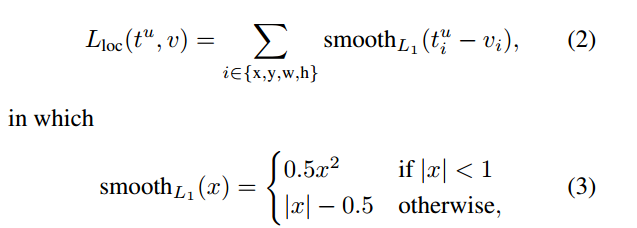
bound-box regression中各参数的计算方式为:
 (4)
(4)
其对应的SmoothL1LossLayer代码如下,整个过程分为两部分:前向计算以及后向计算(1)式的后半部分:
// ------------------------------------------------------------------ // Fast R-CNN // Copyright (c) 2015 Microsoft // Licensed under The MIT License [see fast-rcnn/LICENSE for details] // Written by Ross Girshick // ------------------------------------------------------------------ #include "caffe/fast_rcnn_layers.hpp" namespace caffe { //SmoothL1前向计算(3)式 template <typename Dtype> __global__ void SmoothL1Forward(const int n, const Dtype* in, Dtype* out, Dtype sigma2) { // f(x) = 0.5 * (sigma * x)^2 if |x| < 1 / sigma / sigma // |x| - 0.5 / sigma / sigma otherwise CUDA_KERNEL_LOOP(index, n) { Dtype val = in[index]; Dtype abs_val = abs(val); if (abs_val < 1.0 / sigma2) { out[index] = 0.5 * val * val * sigma2; } else { out[index] = abs_val - 0.5 / sigma2; } } } // template <typename Dtype> void SmoothL1LossLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { int count = bottom[0]->count(); caffe_gpu_sub( count, bottom[0]->gpu_data(), //ti bottom[1]->gpu_data(), //ti* diff_.mutable_gpu_data()); // d := ti-ti* if (has_weights_) { //乘上相关的权重,对应于(1)式中的pi*,有目标时为1 // apply "inside" weights caffe_gpu_mul( count, bottom[2]->gpu_data(), //pi* diff_.gpu_data(), diff_.mutable_gpu_data()); // d := w_in * (b0 - b1) }
//代入计算SmoothL1 SmoothL1Forward<Dtype><<<CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS>>>( count, diff_.gpu_data(), errors_.mutable_gpu_data(), sigma2_); CUDA_POST_KERNEL_CHECK; if (has_weights_) { //乘上相关的权重 // apply "outside" weights caffe_gpu_mul( count, bottom[3]->gpu_data(), // 1/Nreg errors_.gpu_data(), errors_.mutable_gpu_data()); // d := w_out * SmoothL1(w_in * (b0 - b1)) } Dtype loss; caffe_gpu_dot(count, ones_.gpu_data(), errors_.gpu_data(), &loss); top[0]->mutable_cpu_data()[0] = loss / bottom[0]->num(); } //反向计算,对smoothLoss求导 template <typename Dtype> __global__ void SmoothL1Backward(const int n, const Dtype* in, Dtype* out, Dtype sigma2) { // f'(x) = sigma * sigma * x if |x| < 1 / sigma / sigma // = sign(x) otherwise CUDA_KERNEL_LOOP(index, n) { Dtype val = in[index]; Dtype abs_val = abs(val); if (abs_val < 1.0 / sigma2) { out[index] = sigma2 * val; } else { out[index] = (Dtype(0) < val) - (val < Dtype(0)); } } } // template <typename Dtype> void SmoothL1LossLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { // after forwards, diff_ holds w_in * (b0 - b1) int count = diff_.count();
//调用反向smoothloss,diff_.gpu_data()表示x,diff_.mutable_gpu_data()表示smoothloss的导数 SmoothL1Backward<Dtype><<<CAFFE_GET_BLOCKS(count), CAFFE_CUDA_NUM_THREADS>>>( count, diff_.gpu_data(), diff_.mutable_gpu_data(), sigma2_);
//类似于前向 CUDA_POST_KERNEL_CHECK; for (int i = 0; i < 2; ++i) { if (propagate_down[i]) { const Dtype sign = (i == 0) ? 1 : -1; const Dtype alpha = sign * top[0]->cpu_diff()[0] / bottom[i]->num(); caffe_gpu_axpby( count, // count alpha, // alpha diff_.gpu_data(), // x Dtype(0), // beta bottom[i]->mutable_gpu_diff()); // y if (has_weights_) { // Scale by "inside" weight caffe_gpu_mul( count, bottom[2]->gpu_data(), bottom[i]->gpu_diff(), bottom[i]->mutable_gpu_diff()); // Scale by "outside" weight caffe_gpu_mul( count, bottom[3]->gpu_data(), bottom[i]->gpu_diff(), bottom[i]->mutable_gpu_diff()); } } } } INSTANTIATE_LAYER_GPU_FUNCS(SmoothL1LossLayer); } // namespace caffe