课程链接:http://ufldl.stanford.edu/tutorial/supervised/MultiLayerNeuralNetworks/
这一节前半部分介绍了神经网络模型及前向传导,定义了很多的变量,这些变量到底代表了什么一定要搞懂,否则后半部分的推导就看不懂了。
首先是active function,一般选的是sigmod,但深度学习中选的是rectified linear function,既没有边界,也不可连续可微:
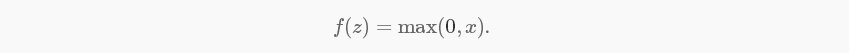
下面是几个active function的对比图:

rectified linear function 是逐段线性的,且在小于0的地方是饱和的。它在小于0是梯度为0,大于0时梯度为1,在0的地方没有定义
但在实际过程中没有问题,“we average the gradient over many training examples during optimization”。
后半部分前的是BP,其实就是怎么求w,b.BP算法是通过反向逐层计算残差来计算梯度,具体参考这篇博客http://blog.csdn.net/itplus/article/details/11022243,总结加注释,写的非常非常好
其实整个过程就是,用梯度下降法来求得最优的w和b,但我们只知道最后一个输出,那么隐含的各层的梯度该如何求呢?这就要用到BP了。
然后是作业部分。里面用到几个函数,简单分析下(主要是好多我没看懂)。
stack = params2stack(params, ei)将一个flattened parameter vector(不明白那个扁平是什么意思)转为a nice "stack" structure,
ei是auxiliary variable containing the configuration of the network
函数首先得到网络的深度depth,并初始化一个这么大的cell(stack),取得前一层的大小(单元个数?)prev_size,并定义了一个表示参数向量位置的向量。
接下来是一个循环。目的是取得所有层的权值与偏差。最后返回的stack包括每层的权值和偏差。
未完待续。。。。