参考:http://www.cnblogs.com/ywl925/p/3275878.html
这个模型主要用于信息检索,但它的思想用于图像也未尝不可。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,
则认为此词或者短语具有很好的类别区分能力,适合用来分类。
只需理解两个概念就行了:
TF(词频)公式:
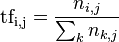
以上式子中  是该词在文件
是该词在文件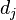 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
IDF反文档频率:
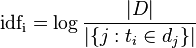
- |D|:语料库中的文件总数
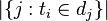 :包含词语
:包含词语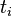 的文件数目(即
的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用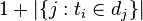
然后
