一、插入数据(INSERT)
MariaDB [(none)]> help insert
Name: 'INSERT'
Description:
Syntax:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
{VALUES | VALUE} ({expr | DEFAULT},...),(...),...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
MariaDB [testdb]> INSERT INTO students VALUES (1,'Yang Guo',20,'m'),(2,'guo xiang', 30,'f');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
(如果省略字段col_name,则是给表中所有字段都添加值,如果是允许为空的,都也必须空出来,一般情况我们建议插入数据的时候,都必须指定字段col_name)
Or:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
插入单个字段的值
MariaDB [testdb]> insert into students set name='hongqigong';
Query OK, 1 row affected, 1 warning (0.01 sec)
MariaDB [testdb]> select * from students;
+-----+------------+------+--------+
| sid | name | age | gender |
+-----+------------+------+--------+
| 0 | hongqigong | NULL | NULL |
| 1 | Yang Guo | 20 | m |
| 2 | guo xiang | 30 | f |
+-----+------------+------+--------+
3 rows in set (0.00 sec)
MariaDB [testdb]> insert into students (sid,name) values (3,'zhaomi'),(4,'zhangwuji');
Or:
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
二、检索数据(SELECT)
MariaDB [testdb]> help select
Name: 'SELECT'
Description:
Syntax:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
Select col1,col2,.... from tb1_name [where clause][ORDER BY 'col_name'][Limit M,{n}]
字段表示:
*: 所有字段
as: 字段别名------------col1 AS alias1
查找条件:WHERE
操作符:
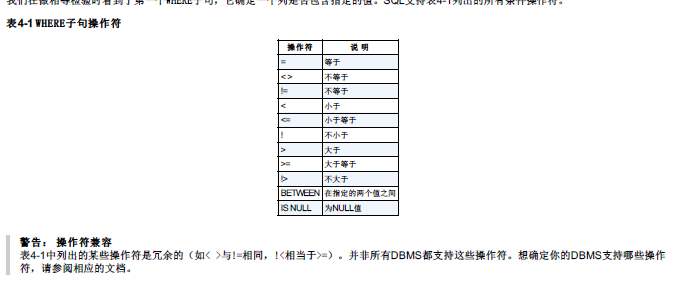
组合条件:
and 与 or 或 not 非
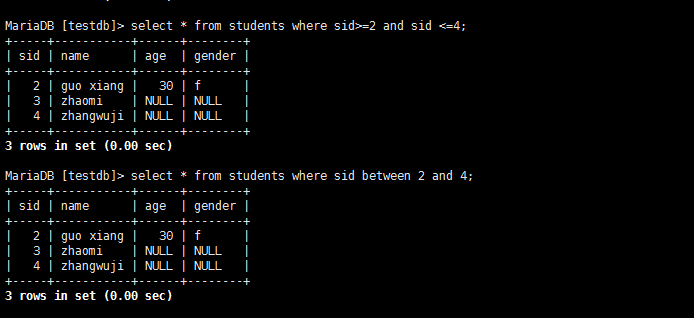
between 值1 and 值 2
MariaDB [testdb]> SELECT prod_name, prod_price FROM Products WHERE vend_id = 'DLL01' OR vend_id = ‘BRS01’;
Like操作符
%: 任意长度的任意字符
_: 任意长度单个字符

IN操作符:IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配。IN取一组由逗号分隔、括在圆括号中的合法值
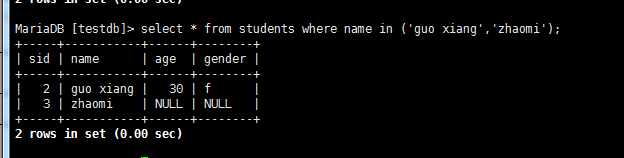
为什么要使用IN操作符?其优点为:
在有很多合法选项时,IN操作符的语法更清楚,更直观。
在与其他AND和OR操作符组合使用IN时,求值顺序更容易管理。
IN操作符一般比一组OR操作符执行得更快(在上面这个合法选项很少的例子中,你看不出性能差异)。
IN的最大优点是可以包含其他SELECT语句,能够更动态地建立WHERE子句。第11课会对此进行详细介绍。
排序:ORDER BY
单个字段:
多个字段:
经常需要按不止一个列进行数据排序。例如,如果要显示雇员名单,可能希望按姓和名排序(首先按姓排序,然后在每个姓中再按名排序)。
如果多个雇员有相同的姓,这样做很有用
排序方向:默认为升序(asc)
升序:ASC
降序:DESC
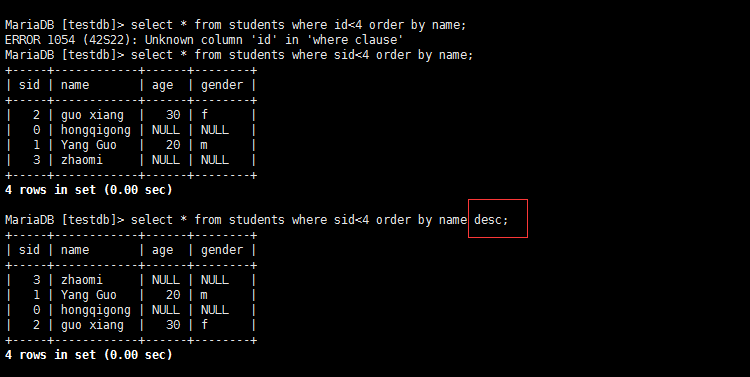

案例:单表查询
MariaDB [testdb]> select * from students where sid<3;
+-----+------------+------+--------+
| sid | name | age | gender |
+-----+------------+------+--------+
| 0 | hongqigong | NULL | NULL |
| 1 | Yang Guo | 20 | m |
| 2 | guo xiang | 30 | f |
+-----+------------+------+--------+
3 rows in set (0.00 sec)
MariaDB [testdb]> select * from students where gender='m';
+-----+----------+------+--------+
| sid | name | age | gender |
+-----+----------+------+--------+
| 1 | Yang Guo | 20 | m |
+-----+----------+------+--------+
1 row in set (0.00 sec)
MariaDB [testdb]> select * from students where gender is null;
+-----+------------+------+--------+
| sid | name | age | gender |
+-----+------------+------+--------+
| 0 | hongqigong | NULL | NULL |
| 3 | zhaomi | NULL | NULL |
| 4 | zhangwuji | NULL | NULL |
+-----+------------+------+--------+
3 rows in set (0.00 sec)