类:节点NODE
用链表实现的基本模块是节点。每个节点对象必须持有至少两条信息。首先,节点必须包含列表元素本身。
我们将这称为该节点的“数据区”(data field)。此外,每个节点必须保持到下一个节点的引用。
示例1 显示了Python 的实现方法。需要指出,我们将通常以下图 所示的方式代表一个节点对象。
节点类还包括访问和修改的常用方法:返回节点
数据和引用到下一项。
class Node:
def __init__(self, initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self, newdata):
self.data = newdata
def setNext(self, newnext):
self.next = newnext
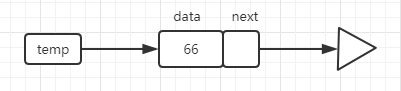
节点类对象包含本身的项目数据和对下一个节点的引用
我们以常见的方式创建了节点类。
>>> temp = Node(66) >>> temp.getData() 66 >>>
Python 的特殊值None 将在节点类和之后的链表类中发挥重要的作用。引用None 意味着没有下一个节点。
在构造器中,一个节点的对下一节点引用的初始赋值是None。因为这有时被称为把节点“接地”(grounding),
我们在图中将使用标准化的“接地”标志来表示一个值为None 的引用。
用None 来作为你在初始化时对下一个节点的引用是一个极妙的主意。
无序列表 UNORDERED LIST
无序列表将由一个节点集合组成,每一个节点采用显式引用链接到下一个节点。
只要我们知道第一个节点的位置(包含第一项),在这之后的每个元素都可以通过以下链
接找到下一个节点。为实现这个想法,UnorderedList 类必须保持一个对第一节点的引用。
代码2 显示了这种构造结构。注意每个UnorderedList 对象将保持列表的头一个节点的引用。
class UnorderedList:
def __init__(self):
self.head = None
实例化:
>>> mylist = UnorderedList()
在最初当我们建立一个列表时,其中没有任何元素。这些赋值语句建立了一个连接好的链表。
正如我们在定义节点类时讨论到的,特殊引用——None 会再被用来说明列表的头不指向任何东西。
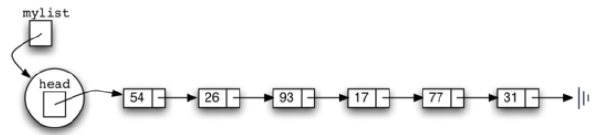
最终,如图所示,之前给出的示例列表将由一个链表来表示。列表的头指向包含列表的第一项的第一节点。
以此类推,该节点有一个指针指向到下一个节点(的内容)。需要注意的一点是,
列表类本身不包含任何节点。取而代之的是,它包含对链式存储结构的第一个节点的引用。
is_empty(判断链表是否为空)方法仅仅只是检查了列表的头是否指向None。其结果以布尔值表示,
如果链表中没有节点,self.head==None 的结果只能是True。因为新链表为空,所以构造器和
是否为空的检验必须与另一个保持一致。这个显示了使用指向None 来指示链表结构的结束。在
Python 中,None 可以与任何指向相提并论。如果两个指向同一个物体,那么他们是平等的。
def isEmpyty(self):
return self.head == None
从链表头部新增节点:
def add(self, item):
temp = Node(item)
temp.setNext(self.head)
self.head = temp
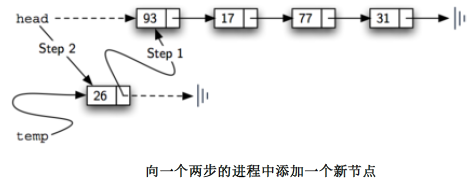
列表中的每个元素必定属于一个节点。第二行创建了一个新的节点并将插入的元素作为节点的数据。
现在我们必须通过链接这个新的节点与原有的结构来完成插入元素的工作。
- 第一个步骤(第3行)是把新插入节点的引用设为原来列表的头节点。
- 由于列表中的其他部分已经和这个新节点正确地连接了,我们可以把列表头部head 指向这个新的节点。
- 代码第4行就是这一步骤,它确定了列表的头部。
接下来我们所要实现的方法——求元素个数(size)、查找(search)和 移除(remove),全部
是基于一个叫做链表的遍历(traversal)的操作的。遍历指的是有序地访问每一个节点的过程。为了
做到这一点,我们可以使用一个外部引用,它最开始指向列表的第一个节点。每当我们访问一个节点时,
我们通过“侧向移动”(traversing)到下一个引用的方式,将外部引用移动到下一个节点。
为了实现“size 求元素个数”的方法,我们需要遍历链表,并且记录出现过的节点个数。
def size(self):
current = self.head
count = 0
while current is not None:
count += 1
current = current.getNext()
return count
我们把这个外部引用称为“当前”(current),
- 在第二行中它被初始化,指向列表的头部。最初我们并没有发现任何节点,所以计数的初值被设定为0。
- 第四到第六行实际上实现了这次遍历。
- 只要这个外部引用没有遇到列表的尾端(None),我们就将current移动到下一个节点,正如第6 行所示。
- 和前文相同,把引用和None 进行比较的操作非常有用。
- 每当current 移动到了一个新的节点,我们就把计数器加1(count)。
- 最终,我们在循环结束后返回了计数值。

在一个无序表中查询一个数值这一方法的实现同样需要用到遍历。每当我们访问一个链表中的节点时,
我们会判断储存在此的数据是否就是我们所要找的元素。
事实上,如果我们的工作进行到了列表的底端,这意味着我们所要寻找的元素在列表中并不存在。
同样,如果我们找到了那个元素,那么就没有必要继续寻找了。
def search(self, item):
current = self.head
found = False
while current is not None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
- 同size 方法一样,遍历在列表的头部被初始化(第2行)。
- 我们同样使用一个叫做found 的布尔变量来表示我们是否找到了我们所要找寻的元素。
- 考虑到我们在遍历开始时并没有找到那个元素,found 被设为假(False)(第3 行)。
- 第4 行中的循环同时考虑了上述的两种情况。
- 只要还有余下的未访问节点并且我们还没有找到元素,我们便继续检查下一个节点。
- 第5 行中的条件语句判断所寻的数据项是否在节点current 之中。如果是,那么found 被设为真(True)。
“移除(remove)”这个方法需要两个步骤。
- 首先我们需要遍历这个列表,来找寻我们想要移除的元素。
- 只要找到了这个元素(假设它存在),就必须移除它。第一步同查询(search)十分接近。
- 我们使用一个外部引用,让它开始时指向链表的头部,顺着链表遍历,直到找到要移除的元素为止。
- 由于我们假设待移除的元素一定存在,那么循环将会在遍历到列表底部前终止。
- 所以,我们这时只需要再使用一个布尔变量found。
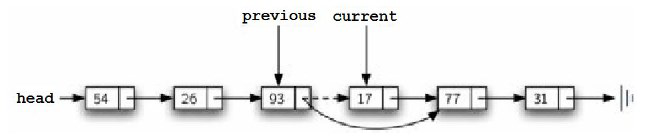
当found 为真(True)时,current 将会是对包含了要移除元素的一个引用。但我们要如何移除它?
解决这个难题的方法是,在遍历链表时使用两个外部引用。current 不变,仍然标记当前遍历到的位置。
新加入的引用——我们叫“前一个”(previous)——在遍历过程中总是落后于current 一个节点。
这样,当current 停在待删除节点时,previous 即停在链表中需要修改的节点处。
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous is None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
完整的移除(remove)过程:
- 第二第三行给两个外部引用赋了初始值。注意到current 如同其他的“遍历”实例一样,从列表的头部开始。
- 然而,我们设定previous 总是访问current 的前一个节点。因此,previous 的初值设为None,因为头部之前没有节点
- 布尔变量found 将会再次被用于控制这次循环。
- 在第六到第七行我们区分了储存在节点中的单元是否是我们想要移除的元素。
- 如果是,found 将会变成真(True)。如果我们没有找到元素,previous 和current 必须同时向后移动一个节点。
- 同样,这两个操作的顺序至关重要,首先previous 要向后移动一个节点,到current 的位置,
- 然后current 才能移动。这一过程常常被称为“一寸寸蠕动”(inch-worming),因为previous 先要跟上current,
current 才能向前移动。

移除(remove)工作中的查询步骤一旦完成,我们需要从链表中移除那个节点。图3.21显示了一个必须进行改动的连接。
然而这里又有一点需要特别说明。
如果要移除的那个元素恰好是列表中的第一个,那么current会引用链表第一个节点。这也就意味着previous的引用会是None。
我们之前提到,previous要指向那个引用要发生变化的节点。在这种情况下,需要改动的不是previous,而是链表的头节点(如图3.22)。

代码7的第12行让我们可以检查我们所要处理的情况是否是上述的特殊情况。
- 如果previous没有移动,那么当布尔变量found已经为真时,previous仍然是None。
- 这种情况下,链表头部head要发生变化,引用紧跟current的那个节点,实际效果就等于从列表中移除第一个节点。
- 而当previous不是None时,要移除的节点一定在链表中表头后方的某处。
- 这时previous将会让我们找到所要移除的节点的前一个节点。
- 第15行调用了previous的setNext方法来完成这次移除。
- 注意到在两种情况中,需要改动的节点或表头最终都指向了current的后一个节点。
链表反转
方法一:
对于一个长度为n的单链表list,用一个大小为n的数组arr储存从单链表从头到尾遍历的所有元素,
在从arr尾到头读取元素简历一个新的单链表; 时间消耗O(n),空间消耗O(n)
class Node:
def __init__(self, initdata):
self.data = initdata
self.next = None
def reverse_linkedlist1(head):
if head == None or head.next == None: # 边界条件
return head
arr = [] # 空间消耗为n, n 为单链表的长度
while head:
arr.append(head.data)
head = head.next
newhead = Node(0)
tmp = newhead
for i in arr[::-1]:
tmp.next = Node(i)
tmp = tmp.next
return newhead.next
方法二:
开始以单链表的第二个元素为循环变量,用2个变量循环向前操作,
并设置1个辅助变量tmp,保存数据; 时间消耗O(n),空间消耗O(1);
def reverse_linkedlist2(head):
if head == None or head.next == None: # 边界条件
return head
p1 = head # 循环变量1
p2 = head.next # 循环变量2
tmp = None # 保存数据的临时变量
while p2:
tmp = p2.next
p2.next = p1
p1 = p2
p2 = tmp
head.next = None
return p1
测试:
def create_all(arr):
pre = Node(0)
tmp = pre
for i in arr:
tmp.next = Node(i)
tmp = tmp.next
return pre.next
def print_all(head):
tmp = head
result = []
while tmp:
result.append(tmp.data)
tmp = tmp.next
print(result)
a = create_all(range(5))
print_all(a)
b = reverse_linkedlist1(a)
print_all(b)
c = reverse_linkedlist2(a)
print_all(c)