看linux内核协议栈的时候看到tcp_sendmsg函数,看起来并不难理解,但是申请skb的时候主buff大小让我很困惑。我以前一直以为会根据sack/ip option/pmtu等计算一个mss,然后申请主buff大小为mss的skb。看到代码我发现我想的太简单了,linux有一个特性就是推迟分片(GSO),根据https://lwn.net/Articles/188489/这篇文章的说法GSO在支持SG的网卡上效率大概能提升17.5%,但是在不支持SG的网卡上反而会慢很多(毕竟需要拷贝两次)。
什么是SG(scatter/gather)
SG就是说网卡支持一次发送多个不连续的数据段。

GSO就是利用上面这个特性,在tcp_sendmsg的时候申请的skb的主buff只存L2/L3/L4的协议头,把所有的数据先放到skb_shinfo(skb)->frags里。等到skb交给网卡驱动前再分片。
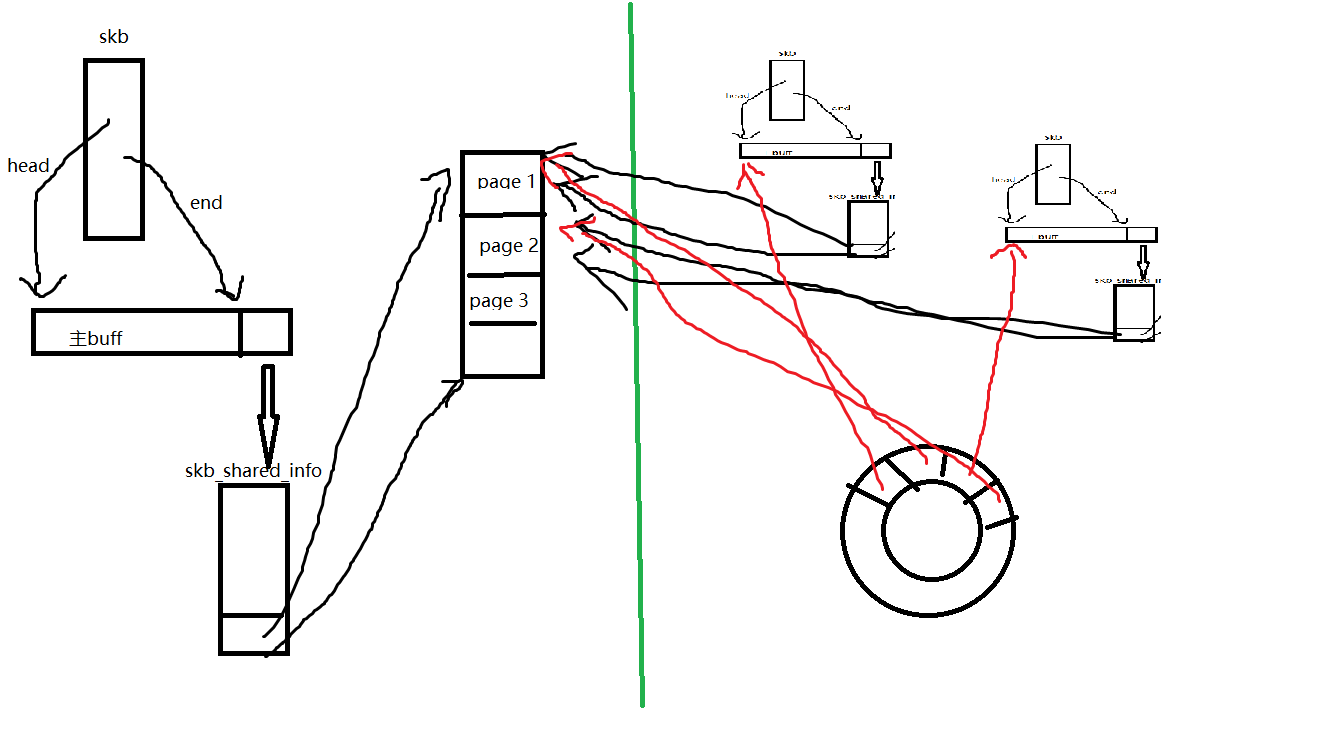
在sendmsg函数里只申请了左边这样的skb,在发给驱动之前把skb分片成右边这样,然后利用网卡的SG发送。看起来并没有减少拷贝次数,也没有减少内存分配的次数,那为什么效率有提升呢?