前言:最近有个项目涉及的业务数据量很大,以平常的方式直接对数据库的查询操作的话,查询效果会变的很差,响应时间会成线性变长。。。
如果加上一些复杂点的查询(例如like)语句,数据库会放弃索引全文检索,并且对全部的关键字进行匹配,那么表中数据只需达到几万条就显得非常吃力,这是我们非常不愿意看到的现象。
因此,最近了解到了一个搜索引擎,也就是Elasticsearch。获取你最常听到的是云搜索服务,例如华为云ES,阿里云ES(阿里和Elastic在国内的唯一官方合作?),腾讯云ES等等。
注:ES是Elasticsearch的简称。
1、Elasticsearch简介
您知道,用于搜索(和分析)
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎。Logstash和Beats有助于收集,聚合和丰富您的数据并将其存储在Elasticsearch中。使用Kibana,您可以交互式地探索,可视化和共享对数据的见解,并管理和监视堆栈。Elasticsearch是建立索引,搜索和分析魔术的地方。
Elasticsearch为所有类型的数据提供实时搜索和分析。无论您是结构化文本还是非结构化文本,数字数据或地理空间数据,Elasticsearch都能以支持快速搜索的方式有效地对其进行存储和索引。您不仅可以进行简单的数据检索,还可以聚合信息来发现数据中的趋势和模式。随着数据和查询量的增长,Elasticsearch的分布式特性使您的部署可以随之无缝地增长。
尽管并非每个问题都是搜索问题,但是Elasticsearch都提供了速度和灵活性来处理各种用例中的数据:
- 将搜索框添加到应用或网站
- 存储和分析日志,指标和安全事件数据
- 使用机器学习自动实时建模数据行为
- 使用Elasticsearch作为存储引擎自动化业务工作流程
- 使用Elasticsearch作为地理信息系统(GIS)管理,集成和分析空间信息
- 使用Elasticsearch作为生物信息学研究工具来存储和处理遗传数据
人们不断使用搜索的新颖方式使我们不断感到惊讶。但是,无论您的用例与其中之一相似,还是正在使用Elasticsearch解决新问题,在Elasticsearch中处理数据,文档和索引的方式都是相同的。
1.1 数据输入:文档和索引
Elasticsearch是一个分布式文档存储。Elasticsearch不会将信息存储为列数据的行,而是存储已序列化为JSON文档的复杂数据结构。当集群中有多个Elasticsearch节点时,存储的文档将分布在集群中,并且可以从任何节点立即访问。
存储文档时,将在1秒钟内几乎实时地对其进行索引和完全搜索。Elasticsearch使用称为倒排索引的数据结构,该结构支持非常快速的全文本搜索。反向索引列出了出现在任何文档中的每个唯一单词,并标识了每个单词出现的所有文档。
索引可以认为是文档的优化集合,每个文档都是字段的集合,这些字段是包含数据的键值对。默认情况下,Elasticsearch对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。例如,文本字段存储在倒排索引中,数字字段和地理字段存储在BKD树中。使用按字段数据结构组合并返回搜索结果的能力使Elasticsearch如此之快。
Elasticsearch还具有无模式的能力,这意味着无需显式指定如何处理文档中可能出现的每个不同字段即可对文档建立索引。启用动态映射后,Elasticsearch自动检测并向索引添加新字段。这种默认行为使索引和浏览数据变得容易-只需开始建立索引文档,Elasticsearch就会检测布尔值,浮点数和整数值,日期和字符串并将其映射到适当的Elasticsearch数据类型。
但是,最终,您比Elasticsearch更了解您的数据以及如何使用它们。您可以定义规则来控制动态映射,也可以显式定义映射以完全控制字段的存储和索引方式。
定义自己的映射使您能够:
- 区分全文字符串字段和精确值字符串字段
- 执行特定于语言的文本分析
- 优化字段以进行部分匹配
- 使用自定义日期格式
- 使用无法自动检测到的数据类型,例如
geo_point和geo_shape
为不同的目的以不同的方式对同一字段建立索引通常很有用。例如,您可能希望将一个字符串字段索引为全文搜索的文本字段和索引关键字,以便对数据进行排序或汇总。或者,您可能选择使用多个语言分析器来处理包含用户输入的字符串字段的内容。
在搜索时也会使用在索引期间应用于全文字段的分析链。当您查询全文字段时,对查询文本进行相同的分析,然后才能在索引中查找术语。
1.2 信息输出:搜索和分析
尽管您可以将Elasticsearch用作文档存储并检索文档及其元数据,但真正的强大之处在于能够轻松访问基于Apache Lucene搜索引擎库构建的全套搜索功能。
Elasticsearch提供了一个简单,一致的REST API,用于管理您的集群以及索引和搜索数据。为了进行测试,您可以轻松地直接从命令行或通过Kibana中的开发者控制台提交请求。在您的应用程序中,您可以使用Elasticsearch客户端作为您选择的语言:Java,JavaScript,Go,.NET,PHP,Perl,Python或Ruby。
搜索数据
Elasticsearch REST API支持结构化查询,全文查询和结合了两者的复杂查询。结构化查询类似于您可以在SQL中构造的查询类型。例如,您可以搜索索引中的gender和age字段,employee然后按hire_date字段对匹配项进行排序。全文查询会找到所有与查询字符串匹配的文档,并按相关性对它们进行归还(它们与您的搜索词的匹配程度如何)。
除了搜索单个术语外,您还可以执行短语搜索,相似性搜索和前缀搜索,并获得自动完成建议。
是否要搜索地理空间或其他数字数据?Elasticsearch在支持高性能地理和数字查询的优化数据结构中索引非文本数据。
您可以使用Elasticsearch全面的JSON样式查询语言(Query DSL)访问所有这些搜索功能。您还可以构造SQL样式的查询,以在Elasticsearch内部本地搜索和聚合数据,并且JDBC和ODBC驱动程序使范围广泛的第三方应用程序可以通过SQL与Elasticsearch进行交互。
分析数据
Elasticsearch聚合使您能够构建数据的复杂摘要,并深入了解关键指标,模式和趋势。通过汇总,您不仅可以找到谚语“大海捞针”,还可以回答以下问题:
- 大海捞针有多少根?
- 针的平均长度是多少?
- 针头的中位长度是多少,由制造商细分?
- 在过去六个月的每个月中,有多少根针被添加到干草堆中?
您还可以使用聚合来回答更细微的问题,例如:
- 您最受欢迎的针头制造商是哪些?
- 是否有异常或异常的针团?
由于聚合利用用于搜索的相同数据结构,因此它们也非常快。这使您可以实时分析和可视化数据。您的报告和仪表板会随着数据的更改而更新,因此您可以根据最新信息采取措施。
而且,聚合与搜索请求一起运行。您可以在单个请求中同时对相同数据搜索文档,过滤结果并执行分析。而且由于聚合是在特定搜索的上下文中计算的,因此您不仅显示了所有70针大小的针数,而且还显示了符合用户搜索条件的70针大小的针数-例如,所有尺寸的不绣花70针。
但是等等,还有更多
是否想自动分析您的时间序列数据?您可以使用机器学习功能在数据中创建正常行为的准确基准,并识别异常模式。通过机器学习,您可以检测到:
- 与值,计数或频率的时间偏差有关的异常
- 统计稀有度
- 人口成员的异常行为
最好的部分是?您无需指定算法,模型或其他与数据科学相关的配置即可执行此操作。
1.3 可扩展性和弹性:集群,节点和碎片
Elasticsearch旨在始终可用并根据您的需求扩展。它是通过自然分布来实现的。您可以将服务器(节点)添加到集群以增加容量,Elasticsearch会自动在所有可用节点之间分配数据和查询负载。无需大修您的应用程序,Elasticsearch知道如何平衡多节点集群以提供扩展性和高可用性。节点越多,越好。
这是如何运作的?在幕后,Elasticsearch索引实际上只是一个或多个物理碎片的逻辑分组,其中每个碎片实际上是一个独立的索引。通过将文档分布在多个分片中的索引中,然后将这些分片分布在多个节点中,Elasticsearch可以确保冗余,这既可以防止硬件故障,又可以在将节点添加到集群中时提高查询能力。随着集群的增长(或收缩),Elasticsearch会自动迁移碎片以重新平衡集群。
分片有两种类型:主数据库和副本数据库。索引中的每个文档都属于一个主分片。副本分片是主分片的副本。副本可提供数据的冗余副本,以防止硬件故障并提高处理读取请求(例如搜索或检索文档)的能力。
创建索引时,索引中主碎片的数量是固定的,但是副本碎片的数量可以随时更改,而不会中断索引或查询操作。
这取决于... ...
在分片大小和为索引配置的主分片数量方面,存在许多性能方面的考虑和权衡取舍。碎片越多,维护这些索引的开销就越大。分片大小越大,当Elasticsearch需要重新平衡集群时,移动分片所需的时间就越长。
查询很多小的分片会使每个分片的处理速度更快,但是更多的查询意味着更多的开销,因此查询较小数量的大分片可能会更快。简而言之...要视情况而定。
作为起点:
- 旨在将平均分片大小保持在几GB到几十GB之间。对于具有基于时间的数据的用例,通常会看到20GB到40GB范围内的碎片。
- 避免庞大的碎片问题。节点可以容纳的分片数量与可用堆空间成比例。通常,每GB堆空间中的分片数量应少于20。
确定用例最佳配置的最佳方法是通过使用自己的数据和查询进行测试。
在灾难的情况下
出于性能原因,群集内的节点必须位于同一网络上。跨不同数据中心中的节点的群集中的碎片平衡太简单了。但是高可用性架构要求您避免将所有鸡蛋都放在一个篮子里。如果一个位置发生重大故障,则另一个位置的服务器需要能够接管。无缝地。答案?跨集群复制(CCR)。
CCR提供了一种方法,可以自动将索引从主群集同步到可以用作热备份的辅助远程群集。如果主群集出现故障,则辅助群集可以接管。您还可以使用CCR创建辅助群集,以接近地理位置的方式向您的用户提供读取请求。
跨集群复制是主动-被动的。主群集上的索引是活动的领导者索引,并处理所有写请求。复制到辅助群集的索引是只读关注者。
照顾和喂养
与任何企业系统一样,您需要工具来保护,管理和监视Elasticsearch集群。集成到Elasticsearch中的安全性,监视和管理功能使您可以将Kibana用作控制中心来管理集群。类似的特征数据汇总和指标生命周期管理可帮助您明智随着时间的推移管理您的数据。
注:Kibana是完好支持Elasticsearch的一个可视化界面工具。可以很好在Kibana可视化界面进行维护数据、验证概念操作和分析数据等
——————————————————————————————————————————————————————
注:下面的文章来源于华为云社区—–版主:ES_Siyu,与及间接搬运链接为:https://blog.csdn.net/weixin_39819880/article/details/82083034
1.响应时间
MySQL
背景:
作者在做测试时,发现当数据库中的文档数仅仅上万条时,关键词查询就比较慢了。如果一旦到企业级的数据,响应速度就会更加不可接受。
原因:
在数据库做模糊查询时,如LIKE语句,它会遍历整张表,同时进行字符串匹配。
例如,当作者在数据库查询“市场”时,数据库会在每一条记录去匹配“市场”这两字是否出现。实际上,并不是所有记录都包含“市场”,所以做了很多无用功。
这两个步骤都不高效,而且随着数据量的增大,消耗的资源和时间都会线性的增长。
Elasticsearch
提升:
作者使用了云搜索服务后,发现这个问题被很好解决,TB级数据在毫秒级就能返回检索结果,很好地解决了痛点。
原因:
而Elasticsearch是基于倒排索引的,例子如下。
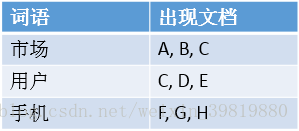
当作者搜索“手机”时,Elasticsearch就会立即返回文档F,G,H。这样就不用花多余的时间在其他文档上了,因此检索速度得到了数量级的提升
——————————————————————————————————————————————————————
2.分词
MySQL
背景:
在做中文搜索时,作者发现组合词检索在数据库是很难完成的。
例如,当用户在搜索框输入“四川火锅”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“推荐四川好吃的火锅”,这时候就没有结果了。
原因:
数据库并不支持分词。如果人工去开发分词功能,费时费精力。
Elasticsearch
提升:
作者使用云搜索服务后,就不用太过于关注分词了,因为Elasticsearch支持中文分词插件,很好地解决了问题。
原因:
当用户使用Elasticsearch时进行搜索时,Elasticsearch就自动帮他分好词了。
例如当作者输入“四川火锅”时,Elasticsearch会自动做下面两件事
(1) 将“四川火锅”分词成“四川”和“火锅”
(2) 查找包含这两个词的文档
——————————————————————————————————————————————————————
3.相关性
MySQL
背景:
在用数据库做搜索时,结果经常会出现一系列文档。作者不禁思考:
· 到底什么文档是用户真正想要的呢?
· 怎么才能把用户想看的文档放在搜索列表最前面呢?
原因:
数据库并不支持相关性搜索。
例如,当用户搜索“咖啡厅”的时候,他很可能更想知道附近哪里可以喝咖啡,而不是怎么开咖啡厅。
Elasticsearch
提升:
作者使用了云搜索服务后,发现Elasticsearch能很好地支持相关性评分。通过合理的优化,云搜索服务能够返回精准的结果,满足用户的需求。
原因:
Elasticsearch支持全文搜索和相关度评分。这样在返回结果就会根据分数由高到低排列。分数越高,意味着和查询语句越相关。
例如,当用户搜索“星巴克咖啡”,带有“星巴克咖啡”的信息就要比只包含“咖啡”的信息靠前。
——————————————————————————————————————————————————————
4.可视化界面
MySQL
背景:
在使用数据库进行查询数据时,很多时候都是通过工程代码或者命令端完成。作者发现很多时候分析结果并不太方便,缺少一个可视化界面来提高效率。
原因:
数据库自身通常不带可视化界面。而在完成搜索相关的任务时,常常需要根据搜索结果来进行分析。
Elasticsearch
提升:
作者使用了云搜索服务后,发现可视化Kibana界面提升了研发的速度。
原因:
Kibana可视化界面完美支持Elasticsearch。研发人员能够在上面快速地进行概念验证,分析结果,提高开发效率。