方案背景
Sunny软件公司开发了一套简单的基于字符界面的格式化指令,可以根据输入的指令在字符界面中输出一些格式化内容,例如输入“LOOP 2 PRINT杨过 SPACE SPACE PRINT 小龙女BREAK END PRINT郭靖 SPACE SPACE PRINT 黄蓉”,将输出如下结果:
杨过 小龙女
杨过 小龙女
郭靖 黄蓉
其中关键词LOOP表示“循环”,后面的数字表示循环次数;PRINT表示“打印”,后面的字符串表示打印的内容;SPACE表示“空格”;BREAK表示“换行”;END表示“循环结束”。每一个关键词对应一条命令,计算机程序将根据关键词执行相应的处理操作。
现使用解释器模式设计并实现该格式化指令的解释,对指令进行分析并调用相应的操作执行指令中每一条命令。
Sunny软件公司开发人员通过分析,根据该格式化指令中句子的组成,定义了如下文法规则:
expression ::= command* //表达式,一个表达式包含多条命令
command ::= loop | primitive //语句命令
loop ::= 'loopnumber' expression 'end' //循环命令,其中number为自然数
primitive ::= 'printstring' | 'space' | 'break' //基本命令,其中string
根据以上文法规则,通过进一步分析,绘制如图所示结构图:
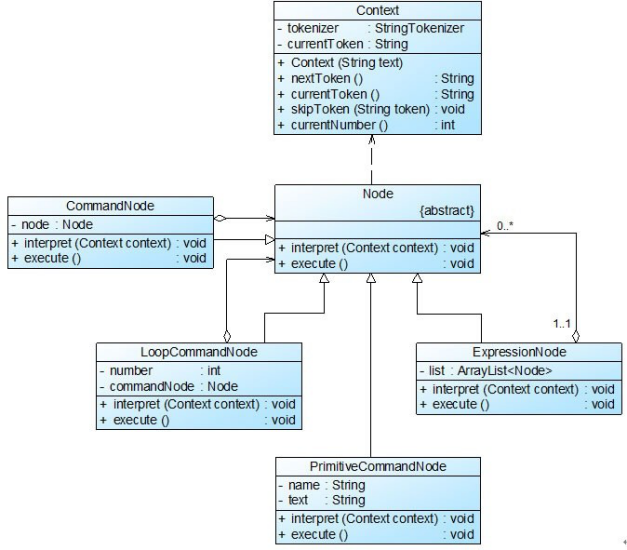
在图中,Context充当环境角色,Node充当抽象表达式角色,ExpressionNode、CommandNode和LoopCommandNode充当非终结符表达式角色,PrimitiveCommandNode充当终结符表达式角色。完整代码如下所示:
//环境类:用于存储和操作需要解释的语句,在本实例中每一个需要解释的单词可以称为一个 class Context { private StringTokenizer tokenizer; //StringTokenizer类,用于将字符private String currentToken; //当前字符串标记 public Context(String text) { tokenizer = new StringTokenizer(text); //通过传入的指令字符串创建nextToken(); } //返回下一个标记 public String nextToken() { if (tokenizer.hasMoreTokens()) { currentToken = tokenizer.nextToken(); } else { currentToken = null; } return currentToken; } //返回当前的标记 public String currentToken() { return currentToken; } //跳过一个标记 public void skipToken(String token) { if (!token.equals(currentToken)) { System.err.println("错误提示:" + currentToken + "解释错误!"); } nextToken(); } //如果当前的标记是一个数字,则返回对应的数值 public int currentNumber() { int number = 0; try { number = Integer.parseInt(currentToken); //将字符串转换为整 } catch ( NumberFormatException e) { System.err.println("错误提示:" + e); } return number; } }
//抽象节点类:抽象表达式 abstract class Node { public abstract void interpret(Context text); //声明一个方法用于解释 public abstract void execute(); //声明一个方法用于执行标记对应的命令 }
//表达式节点类:非终结符表达式 class ExpressionNode extends Node { private ArrayList<Node> list = new ArrayList<Node>(); //定义一个集 public void interpret(Context context) { //循环处理Context中的标记 while (true) { //如果已经没有任何标记,则退出解释 if (context.currentToken() == null) { break; } //如果标记为END,则不解释END并结束本次解释过程,可以继续之后的解释 else if (context.currentToken().equals("END")) { context.skipToken("END"); break; } //如果为其他标记,则解释标记并将其加入命令集合 else { Node commandNode = new CommandNode(); commandNode.interpret(context); list.add(commandNode); } } } //循环执行命令集合中的每一条命令 public void execute() { Iterator iterator = list.iterator(); while (iterator.hasNext()) { ((Node) iterator.next()).execute(); } } }
//语句命令节点类:非终结符表达式 class CommandNode extends Node { private Node node; public void interpret(Context context) { //处理LOOP循环命令 if (context.currentToken().equals("LOOP")) { node = new LoopCommandNode(); node.interpret(context); } //处理其他基本命令 else { node = new PrimitiveCommandNode(); node.interpret(context); } } public void execute() { node.execute(); } }
//循环命令节点类:非终结符表达式 class LoopCommandNode extends Node { private int number; //循环次数 private Node commandNode; //循环语句中的表达式 //解释循环命令 public void interpret(Context context) { context.skipToken("LOOP"); number = context.currentNumber(); context.nextToken(); commandNode = new ExpressionNode(); //循环语句中的表达式 commandNode.interpret(context); } public void execute() { for (int i = 0; i < number; i++) commandNode.execute(); } }
//基本命令节点类:终结符表达式 class PrimitiveCommandNode extends Node { private String name; private String text; //解释基本命令 public void interpret(Context context) { name = context.currentToken(); context.skipToken(name); if (!name.equals("PRINT") && !name.equals("BREAK") && !name.equals("SPACE")) { System.err.println("非法命令!"); } if (name.equals("PRINT")) { text = context.currentToken(); context.nextToken(); } } public void execute() { if (name.equals("PRINT")) System.out.print(text); else if (name.equals("SPACE")) System.out.print(" "); else if (name.equals("BREAK")) System.out.println(); } }
在本实例代码中,环境类Context类似一个工具类,它提供了用于处理指令的方法,如nextToken()、currentToken()、skipToken()等,同时它存储了需要解释的指令并记录了每一次解释的当前标记(Token),而具体的解释过程交给表达式解释器类来处理。我们还可以将各种解释器类包含的公共方法移至环境类中,更好地实现这些方法的重用和扩展。
针对本实例代码,我们编写如下客户端测试代码:
class Client { public static void main(String[] args) { String text = "LOOP 2 PRINT 杨过 SPACE SPACE PRINT 小龙女 BREAK END PRINT 郭靖 SPACE SPACE PRINT 黄蓉"; Context context = new Context(text); Node node = new ExpressionNode(); node.interpret(context); node.execute(); } }
杨过 小龙女
杨过 小龙女
郭靖 黄蓉
解释器模式的主要优点如下:
(1) 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
(2) 每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
(3) 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂,还可以通过一些工具自动生成节点类代码。
(4) 增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合“开闭原则”。
解释器模式的主要缺点如下:
(1) 对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护,此时可以考虑使用语法分析程序等方式来取代解释器模式。
(2) 执行效率较低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
在以下情况下可以考虑使用解释器模式:
(1) 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
(2) 一些重复出现的问题可以用一种简单的语言来进行表达。
(3) 一个语言的文法较为简单。
执行效率不是关键问题。【注:高效的解释器通常不是通过直接解释抽象语法树来实现的,而是需要将它们转换成其他形式,使用解释器模式的执行效率并不高。】