和UDP这种“滚珠”式的协议不同(一份数据就是一个udp packet),TCP以报文段的方式传递数据,其大小受网络链路的限制。在SYN报文段中互相通告最大报文段长(MSS)。所以业务层交付的数据,会被TCP拆分/合并为合适的报文段(这也就是为嘛TCP数据跟水流似的,没有边界)。
对于每个报文段而言,就很像UDP的“滚珠”了,不保证顺序、不保证到达。TCP要对收到的报文重新排序,再才交给应用层。发出一个报文段后,会启动一个定时器,等待对端ACK确认收到,否则将重传该报文。由于重传机制,报文段可能发生重复,接收端须丢弃重复报文。借此TCP实现了自己的可靠性。
那如何高效实现此可靠性的呢?
【ack确认】
首先是ack的设计,最直白的方式:跟我们平时写异步IO很相似,发送一份数据,等待对方确认,再发下一份。
由于TCP是双全工的,两端都可有数据交互,对端的ack可以合并至其正常报文段中,减少交互量。此即:“经受延时的确认”——通常TCP在接收到数据时并不立即发送ACK;相反,它推迟发送,以便将ACK与需要沿该方向发送的数据一起发送。
再者,ACK是确认收到的字节序,未必每一条报文都须ACK,可一次ACK多条数据。比如连续收到两个报文段“PSH 1:1025; PSH 1025:2049”,只需回复一条“ack 2049”即可。“隔一个报文段确认”策略——接收方不必确认每一个收到的分组,ACK是累积的,它们表示收方已正确收到了一直到确认序号减一的所有字节。
【快速重传】
如果数据丢失/错误,每次都等超时才重传会慢。
收到一个失序报文段(前面一条丢失/错误/暂未抵达),TCP立即产生一个ack(重复的,且不被延时),如果发方连续收到3(或以上)次相同的ack,就非常可能是报文段丢失/错误,于是重传报文段,不必等timeout。
(PS:为什么是3次,查资料说是经验数据,连续3次,即表示嫌疑报文后的两条报文都正在到达对端了,由于由于链路层的失序造成的时差几乎不可能如此剧烈,可以认为是丢了或校验出错)
还有重传哪些报文段的问题。譬如连续发生5条报文,第二条丢了,其它均到达,发方收到4个ack(2),仅知道2号报文必须重传,3/4/5号是不清楚的(某些TCP实现采用的是重传丢包后的所有报文)。
可在TCP包头中加入SACK,汇报收到的数据碎片,这样发送端就可知道哪些数据到了,哪些是丢了。还是刚才的例子,发方仍收到4个ack(2),多了sack:sack(1, 3-5)。
【Nagle算法和滑动窗口】
其次,我们是有宽带的,要是用户让发多少就发多少,会很浪费。好像200人的航班带两个人飞过。解决方案也很简单:
一、限制小包的数目(Nagle算法,连接上最多只能有一个未确认的小分组,该分组的ack到达之前不能发送其他小分组了,算法是自适应的,收到的ack越快发的就越快);
二、上buffer,缓存用户数据,再分发成块交给IP层传输,相应的对端也要要个接收buffer,两片buffer配合工作,保证收发正确性。
这就是TCP最大特征的“滑动窗口”了。
每条报文段的TCP头部中都会通告当前窗口大小,发送端据此得知可预留多少字节的buffer给应用层。具体工作流程如下图(请忽略字体,多谢):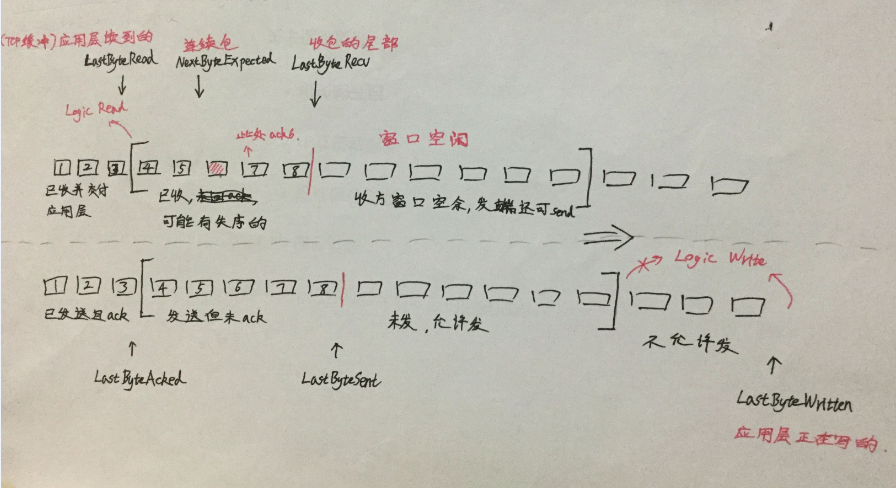
通告窗口为0,显示接收方虽已收到所有数据,但其应用层尚未及时从TcpRecvBuff中读取,发方会停止发送。
Zero Window下,应用层读取数据后,窗口重新空闲,要通知发送方(窗口更新)。一个单独的主动ack,不确认数据,仅报告新的窗口大小。
【坚持定时器】
“单独的主动ack”,跟一般的ack不一样,还记得一般得ack丢了怎么重传的吗?那这货丢了怎么办?
TCP四大定时器(重传、坚持、保活、2MSL)之坚持定时来搞定。
Zero Window后,发方停止发送数据,并设置其坚持定时器,若超时前仍未收到窗口更新,则发送一个特殊的探查报文,获知对端窗口大小。探查含1字节,但不被ack确认,会一直重复。
【糊涂窗口综合征】
好,我们有了Nagle算法,有了滑动窗口,是不是就完全搞定了宽带高效利用呢?
考虑这样一种场景,Zero Window后,收方应用程序每次仅拷走1个字节,触发窗口更新,ack win 1,发方窗口右边沿更新,发送了1字节数据,停止,等下一波窗口更新……loop(PS:实际不可能只是1字节,tcp头都20字节)
相应的解决方案:
1)接收方不通告小窗口,除非窗口增加至MSS(最大报文段长),或增加到接收方缓冲空间的一半。
2)发送方只在下列条件之一满足时才发数据:
(a) 可以发送一个满长度的报文段
(b) 可以发送至少接收方窗口大小一半的报文段
(c) 无未被确认的数据,且能够发送所有缓冲数据
(d) 连接关闭了Nagle算法
【拥塞避免、慢启动】
还有问题吗?之前由于宽带利用问题,我们要滑动窗口,避免频繁发小包;类似的,由于路由问题,我们还得避免不要太粗暴。
假设连接建立起始(窗口均空闲)便发送大量数据,塞满网络,而链路速率较慢——中间路由器就必须缓存分组了,一旦路由存储空间耗尽,后来的分组会被直接丢弃,TCP吞吐量便随之严重降低了。
“慢启动、拥塞避免”上场——拥塞窗口(congestion window,记作cwnd),慢启动门限(ssthresh)。
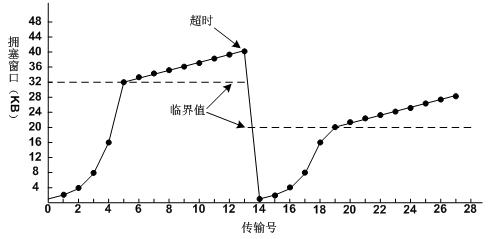
TCP连接建立时,ssthresh初始化为65535字节,拥塞窗口初始化为1个报文段(MSS),每收到一个ack,cwnd便增加一个报文段大小。发送方取min(拥塞窗口,滑动窗口)作为发送上限。
发方先发送一个报文段,等ack,收到后cwnd增加到2,可发两个报文段。收到这两个报文段的ack时,cwnd增加到4……指数增涨(慢启动)。
攀升到一定值后抵达网络容量,中间路由丢弃分组,发方重传定时器超时,知晓cwnd过大引起拥塞,cwnd被重设为1个报文段,ssthresh则被设置为当前cwnd的一半。
还有种拥塞指示:收到重复ack,比如中间某报文损坏。此时仅设置ssthresh = cwnd/2,并不改写cwnd。
若 cwnd <= ssthresh,则进行慢启动,cwnd按指数更新;否则进行拥塞避免,cwnd按线性方式增长(每次ack增加1/cwnd,一个RTT内最多增加一个报文段,无论期间受到多少个ack)。