# 20181235 2019-2020-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1812
姓名: 周昱涵
学号:20181235
实验教师:王志强
实验日期:2020年6月3日
必修/选修: 公选课
## 1.实验内容
爬虫实验,通过爬虫技术爬取头像网站的头像图片并将链接保存到txt文档中
## 2. 实验过程及结果
利用爬虫技术进行爬虫练习,调用random,requerts,bs4(BeautifulSoup),lxml(etree),re函数库进行实验,我这次爬取的网站是https://www.woyaogexing.com/
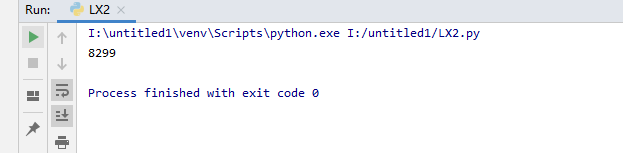
输出结果为抓取的数量和一个创建的txt文档,利用di_url = 'https://www.woyaogexing.com'+str(x)获取最底层url,从最底层url里提取img_url
利用html=requests.get(di_url).content.decode('utf8')从这里找到照片链接
结果如下:
代码
import random import requests from bs4 import BeautifulSoup from lxml import etree import re zhong_url = []#所有中层链接,还没有添加前缀url for page_num in range(2,25): gao_url = 'https://www.woyaogexing.com/touxiang/index_'+str(page_num)+'.html' html = requests.get(gao_url).content.decode('utf8') pat = r'href="(.*?)" class="imgTitle" '#提取链接表达式 link = re.findall(pat,html) zhong_url.append(link) img_url=[]#列表套列表 for link_list in zhong_url: for x in link_list: di_url = 'https://www.woyaogexing.com'+str(x)#最底层url,从最底层url里提取img_url html=requests.get(di_url).content.decode('utf8')#从这里找到照片链接 pat_href = '<a href="(.*?)" class="swipebox">' href = re.findall(pat_href,html) img_url.append(href) all_img_url=[] for i in img_url: for p in i: all_img_url.append(p) print(len(all_img_url)) iiii= ",".join(all_img_url) with open('头像url.text','w') as f: f.write(iiii)
## 其他(感悟、思考等)
爬虫技术十分的高端,还有很多值得我们去学习,这次做的是一个十分简陋的爬虫,希望在暑假可以能够有很大的涨进,还有多学会利用各种函数库进行练习