前几个月进行的大数据架构的升级:
原来的大数据集群的状况如下:
1)主从模式,从多个日志源采集后,
2)接收端只用了1个flume接收,存储到hdfs上。
3)并不支持实时的数据清洗。
4)存储到hive系统的数据归类不合理,数据没有明显的层级关系,全部从多个源表直接计算输出结果。
另外,原来的同事在保存hdfs时,习惯自己去指定location的方式存储数据,导致后来我们检查某个表的数据存放在哪个路径时,需要查询到partition对应的路径。
5)使用oozie调度
经过改造后的变化如下:
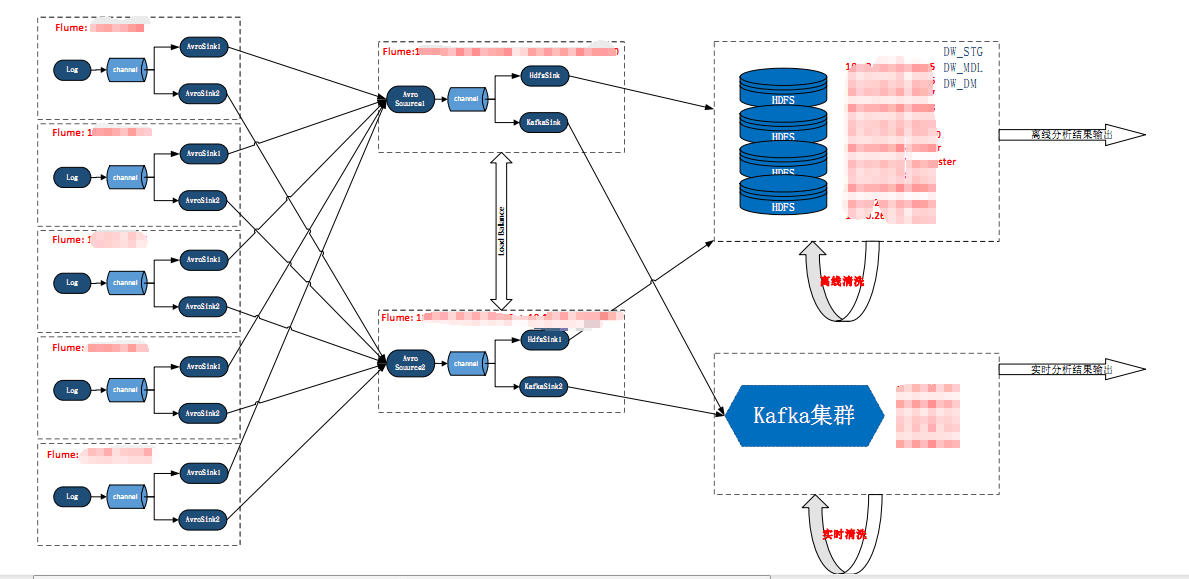
主从模式 -> HA模式
单点flume接收-> load balance
离线数据存储 -> 实时+离线
单库的大表的存储模式 -> 多库多表的仓库模式,hive中的存储由原来的单个default数据库变更为dw_stg,dw_mdl,dw_dm分别对应数据仓库的三层结构。
dw_stg作为数据源收集层,dw_mdl作为清洗层及宽表层,dw_dm作为汇总层.
并且规定,所有数据的存储使用hive仓库的默认路径,如果自己指定location,需要保持与hive表的路径一直。
oozie的调度 -> 增加了oozie调度的监控,每日以邮件方式发送oozie中任务的执行情况。
实时程序监控 -> 通过增加钉钉机器人来实时报警出错信息。对于实时计算的程序,如果出现异常,通过钉钉机器人来实时报警。
以下为整个大数据的架构图: