分段函数常用于分箱中,统计分组在指定的区间中的占比。
比如有如下例子:统计某个班级中考试分数在各个阶段的占比。
准备的数据如下:
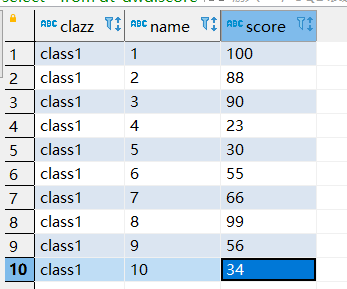
使用如下文件在hive中建表。
class1,1,100 class1,2,88 class1,3,90 class1,4,23 class1,5,30 class1,6,55 class1,7,66 class1,8,99 class1,9,56 class1,10,34
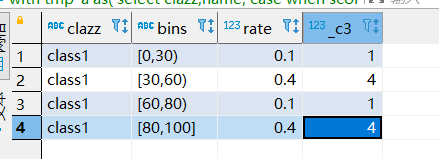
这时候使用case when来计算每行记录分别在哪个区间如下:
with tmp_a as( select clazz,name, case when score <30 then '[0,30)' when score <60 then '[30,60)' when score < 80 then '[60,80)' when score <= 100 then '[80,100]' else 'none' end bins from dt_dwd.score ) select clazz,bins,count(1)/sum(count(1)) over (partition by clazz) as rate,count(1) from tmp_a group by clazz,bins;
最后是统计结果如下:
上述就是通常的分箱占比操作例子。
现在我有多组标签需要监控,每次写case when的,这里面的分段非常多,于是想到用hive udf来简化写法。
先看已经完成的自定义函数default.piecewise的sql写法如下:
select clazz,name,default.piecewise('[0,30)|[30,60)|[60,80)|[80,100]',score) as bins
from dt_dwd.score
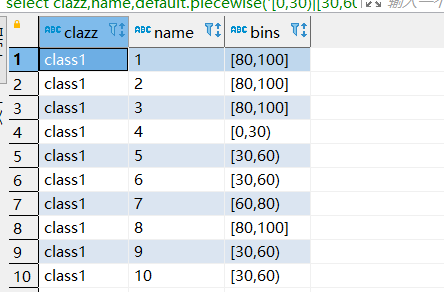
完整的sql如下:
with tmp_a as(
select
clazz,name,default.piecewise('[0,30)|[30,60)|[60,80)|[80,100]',score) as bins
from dt_dwd.score
)
select clazz,bins,count(1)/sum(count(1)) over (partition by clazz) as rate,count(1)
from tmp_a group by clazz,bins;
这样我们可以将分箱抽象到变量中,在当做参数传入,就不要每次写很大段的case when了。
default.piecewise的完整写法如下:
package com.demo.udf; import org.apache.hadoop.hive.ql.exec.Description; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.udf.generic.GenericUDF; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaConstantStringObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector; import org.apache.hadoop.io.Text; import java.util.Objects; /** * @Author: KingWang * @Date: 2021/9/21 * @Desc: 自定义分段函数 * 传入参数1:none|[0,30]|(30,60]|(60,90]|(90,+] * 传入参数2:值 * 返回:根据参数2的值,判断在参数1的区间,返回参数1的区间值 * 如: 参数2:45, 则返回(30,60] **/ @Description(name = "default.piecewise", value = "_FUNC_(piecewise, value) - Returns piecewise if the value mapped.", extended = "Example: > SELECT _FUNC_('[0,30)|[30,60)|(60,100]', 88) FROM table limit 1; '(60,100]'") public class Piecewise extends GenericUDF { private transient StringObjectInspector piecewiseOI; private transient StringObjectInspector valOI; @Override public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException { if (arguments.length != 2) { throw new UDFArgumentException("The function piecewiseUDF accepts 2 arguments."); } if(null == arguments[0]){ throw new UDFArgumentException("first arguments can not be null."); } this.piecewiseOI = (StringObjectInspector) arguments[0]; this.valOI = (StringObjectInspector) (null == arguments[1] ? new JavaConstantStringObjectInspector("") : arguments[1]); return PrimitiveObjectInspectorFactory.writableStringObjectInspector; } @Override public Object evaluate(DeferredObject[] deferredObjects) throws HiveException { String piecewise = piecewiseOI.getPrimitiveJavaObject(deferredObjects[0].get()); String val = valOI.getPrimitiveJavaObject(null != deferredObjects[1] ? deferredObjects[1].get():""); String[] list = piecewise.split("\|"); if(Objects.isNull(val)||"".equals(val)){ return new Text("none"); } boolean match = false; for(String str:list){ if(str.indexOf(",")>0){ try{ double value = Double.valueOf(val); if(str.startsWith("(-,") || str.startsWith("[-,")){ match = minusAndValue(str,value); }else if(str.endsWith(",+)") || str.endsWith(",+]")){ match = valueAndPlus(str,value); }else{ match = valueAndValue(str,value); } }catch (NumberFormatException e){ } } else { if(str.equalsIgnoreCase(val)){ match = true; } } if(match) return new Text(str); } //未匹配上的返回到ERROR分组中 return new Text("ERROR"); } @Override public String getDisplayString(String[] strings) { return strings[0]; } /** * 表达式类似于(-,60)或者[-,60)或者(-,60]或者[-,60] * @param express * @return */ public static boolean minusAndValue(String express,Double value){ boolean is_match = false; String endStr = express.split(",")[1]; double end = Double.valueOf(endStr.substring(0,endStr.length()-1)); if(express.endsWith(")")){ if( value < end ){ is_match = true; } }else if(express.endsWith("]")){ if( value <= end){ is_match = true; } } return is_match; } /** * 表达式类似于(80,+)或者[80,+)或者(80,+]或者[80,+] * @param express * @return */ public static boolean valueAndPlus(String express,Double value){ boolean is_match = false; String beginStr = express.split(",")[0]; double begin = Double.valueOf(beginStr.substring(1)); if(express.startsWith("(")){ if( value > begin ){ is_match = true; } }else if(express.startsWith("[")){ if(value >= begin){ is_match = true; } } return is_match; } /** * 表达式类似于(60,80)或者(60,80]或者[60,80)或者[60,80] * @param express * @return */ public static boolean valueAndValue(String express,Double value){ boolean is_match = false; String beginStr = express.split(",")[0]; String endStr = express.split(",")[1]; double begin = Double.valueOf(beginStr.substring(1)); double end = Double.valueOf(endStr.substring(0,endStr.length()-1)); if(express.startsWith("(") && express.endsWith(")")){ if( value> begin && value < end){ is_match = true; } }else if(express.startsWith("[") && express.endsWith("]")){ if(value >= begin && value <= end){ is_match = true; } }else if(express.startsWith("(") && express.endsWith("]")){ if(value > begin && value <= end){ is_match = true; } }else if(express.startsWith("[") && express.endsWith(")")){ if(value >= begin && value < end){ is_match = true; } } return is_match; } }
实际使用中,shell脚本中定义分箱变量,通过参数传递给scrip.sql脚本

使用注意事项:
当传入的值为null时,会报异常,需要使用nvl(nullfileld,'') 或者nvl(nulllfiled,'none')来处理,其结果将默认分配在none分段中。
然后在script.sql脚本中可以接收传入的分箱变量来灵活使用。
2021.09.26 优化:
将未匹配的行,使用ERROR分箱表示,因为执行程序过程中如果发现有不在给定的分箱里面的,会报错,到时候排错特别困难。
这样直接给个带ERROR的分箱组,可以很直接的在结果数据中可以观察到。