透视函数其实就是我们excel中常用的数据透视表相似,先来看个例子。
以下是准备的数据源,数据是电商系统中用户的行为数据(浏览,收藏,加购,成交,评分等),score为统计次数。
对应的字段分别为 租户id,用户id,商品编码Id,行为事件代码,当日统计次数,统计日期。

现在我们要转换成目标的数据是 租户中每个用户的所有行为记录在一行能够展示,直观点看下图。
对应的字段是 租户Id,用户id,商品id,加购,浏览,收藏,评分,成交
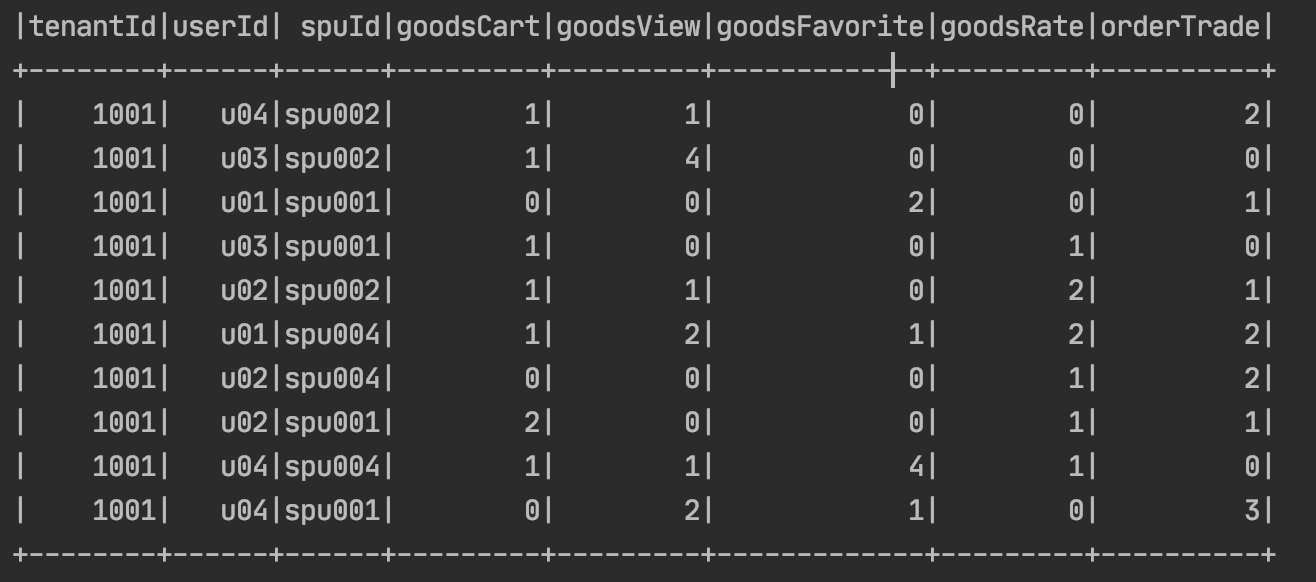
了解了需求以后,我们来看实际的开发如下:
先获取数据源:
val eventRDD = spark.sql("select tenantId,userId,spuId,eventCode,score,dt from dws.dws_user_event_stat")
然后进行转换,以下可以理解为:
groupBy: 对 tenantId,userId,spuId 进行分组
pivot: 对eventCode进行透视,
sum: 对score进行求和,
na.fill(0): 最后对空值进行处理,空值默认填充0.
val userEventScore = eventRDD.groupBy("tenantId","userId","spuId")
.pivot("eventCode")
.sum("score").na.fill(0)
性能优化:
为了使性能达到最优,需要指定透视列对应的不同值,即指定eventCode包含的具体的值有哪些放到一个Seq中。
val userEventScore = eventRDD.groupBy("tenantId","userId","spuId") .pivot("eventCode",Seq("goodsCart","goodsView","goodsFavorite","goodsRate","orderTrade")) .sum("score").na.fill(0)
最后输出的结果如上面截图所示。