一.文件读写的读书笔记
1.文件类型:文本文件,二进制文件
2.文件的打开与关闭
文件可通过open()函数打开,open()有两个参数:文件名和打开模式。open()函数格式如下:<变量名>=open(<文件名>,<打开模式>)
文件的打开模式
| 模式 | 含义 |
|---|---|
| r | 只读 |
| r+ | 读写 |
| w | 写入,先删除原文件,再重新创建并写入,若文件不存在则创建 |
| w+ | 读写,先删除原文件,再重新创建并写入,若文件不存在则创建 |
| a | 写入,在文件末尾追加新内容,若文件不存在则创建 |
| a+ | 读写,在文件末尾追加新内容,若文件不存在则创建 |
| b | 打开二进制文件,可与r,w,a,+结合使用,如:wb+ |
| U | 支持所有换行符:
,
,
,可与r,w,a,+结合,但必须以r开头,如'rUa+', 'rUw+' |
注:以'w'、'a'模式打开文件,只支持写入,不支持读。
2. 读文件
|
读文件方法 |
说明 |
|
<file>.read(size=-1) |
从文件中读入所有内容,若有参数,则读入前size长度的字符串或字节流 |
|
<file>.readline(size=-1) |
从文件中读入一行内容,若有参数,则读入改行前size长度的字符串或字节流 |
|
<file>.readlines(hint=-1) |
从文件中读入所有行,以每行为元素形成列表,若有参数,则读入hint行 |
3. 写文件
|
写文件方法 |
说明 |
|
<file>.write(s) |
向文件中写入一个字符串或字节流 |
|
<file>.writelines(lines) |
将一个全为字符串的列表写入文件 |
|
<file>.seek(offset) |
改变当前文件操作指针的位置(offset值) |
遍历文件:
df = input(“请输入要打开的文件名:”) fo = open(df,“r”) for line in fo: print(line) fo.colse()
二.把exce文件存为csv格式
实现转化的代码如下:
# -*- coding: utf-8 -*- """ @Editor:豆芽运气 This is a that can change excel into csv. """ import pandas as pd import numpy as np import matplotlib.pyplot as plt #提供数据绘图功能的第三方库 #df.to_excel('C:/Users/Asus/Desktop/1.xlsx',sheet_name='dfg') df=pd.read_excel('C:/Users/Administrator/Desktop/Python_1.xlsx.xlsx',index_col=None,na_values=['NA']) print(df) for i in range(len(df.index)): # print(df.iloc[i,1]) for j in range(0,len(df.columns)): if df.iloc[i,j]=='优秀': df.iat[i,j]=90 elif df.iloc[i,j]=='良好': df.iat[i,j]=80 elif df.iloc[i,j]=='合格': df.iat[i,j]=60 elif df.iloc[i,j]=='不合格': df.iat[i,j]=1 else: df.iat[i,j]=0 df.to_csv('C:/Users/Administrator/Desktop/Python_1.csv') print(df)
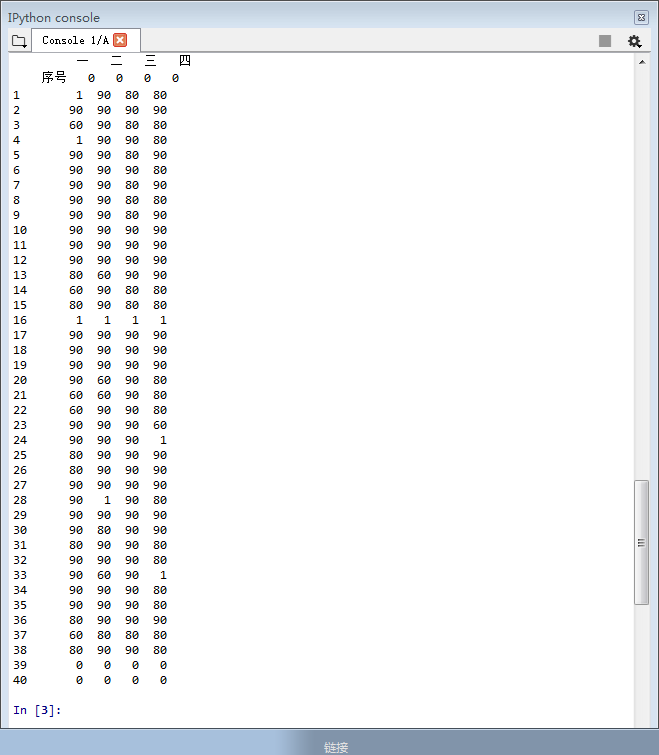
转换的前后对比如下图:

# -*- coding:utf-8
'''
This is a programe that can change csv into html.
@author:
'''
# -*- coding:utf-8
'''
This is a programe that can change excel into csv.
@author:豆芽运气
'''
def fill_data(excel, length=4):
'''
函数功能:填充表格的一行数据,返回html格式的字符串text
excel: 表格中的一行数据
length: 表格中需要填充的数据个数(即列数),默认为4个
由于生成csv文件时自动增加了1列数据,因此在format()函数从1开始
'''
text = '<tr>'
for i in range(length):
tmp = '<td align="center">{}</td>'.format(excel[i+1])
text += tmp
text += "</tr>
"
return text
def GetCsv(csvFile):
'''
函数功能:打开csv文件并获取数据,返回文件数据
csvFile: csv文件的路径和名称
'''
ls = []
csv = open(csvFile, 'r', encoding="utf-8")
for line in csv:
line = line.replace('
', '')
ls.append(line.split(','))
return ls
def CsvToHtml(csvFile, HTMLFILE, thNum):
'''
函数功能:将csv格式文件转换为html格式文件
csvFile: 需要打开和读取数据的csv文件路径
HTMLFILE: 保存的html文件路径
thNum: csv文件的列数,需注意其中是否包括csv文件第1列无意义的数据,
此处包含因此在调用时需要增加1
'''
# HTML1 HTML2 分别为html文件的首部和尾部
HTML1 = '''
<!DOCTYPE HTML>
<html>
<body>
<meta charset=gbk2313>
<h1 align=center>Python成绩表</h2>
<table border='blue'>
'''
HTML2 = "</table>
</body>
</html>"
csv_list = GetCsv(csvFile) # 获得csv文件数据
hF = open(HTMLFILE, 'w') # 创建html文件
hF.write(HTML1) # 写入html文件首部
for i in range(1, thNum+1): # 写入表格的表头(即第1行)
hF.write('<th width="20%">{}</th>
'.format(csv_list[0][i]))
hF.write("</tr>
")
for i in range(1, len(csv_list)): # 写入表格的数据,从第2行开始为数据
hF.write(fill_data(csv_list[i], 5))
hF.write(HTML2) # 写入html文件尾部
hF.close() # 关闭html文件
CsvToHtml("C:/Users/Administrator/Desktop/Python_1.csv", "C:/Users/Administrator/Desktop/Python_1.html",5)
执行效果如下:

四。