第十一章:EXT2文件系统
什么是EXT2文件系统?
The Second Extended File System ( ext2)文件系统是linux系统中的标准文件系统。对于ext2文件系统,磁盘首先被划分为一个个block,每个block大小是相同的,一般为1kByte或4kByte,这些block被聚在一起分成几个大的block group,每个group中的block数量是固定的。

通过mkfs创建虚拟磁盘
mke2fs [-b blksize -N ninodes] device nblocks
在设备上创建一个带有nblocks个块(每个块大小为blksize字节)和ninodes个索引节点的EXT2文件系统。
虚拟磁盘布局
Block#0:引导块 B0是引导块,文件系统不会使用它。它用来容纳一个引导程序,从磁盘引导操作系统。
超级块
Block#1:超级块(在硬盘区分中字节偏移量为1024)B1是超级块,用于容纳整个文件系统的信息。
truct super_block
struct list_head s_list
用于将超级块挂到全局链表super_blocks中
dev_t s_dev
文件系统所在设备的设备号
unsigned long s_blocksize
文件系统块大小
struct file_system_type *s_type
文件系统类型,比如ext2_fs_type
const struct super_operations *s_op
服装inode的分配inode元数据的同步等等
struct dentry *s_root
文件系统根目录的dentry
struct block_device *s_bdev
文件系统所在块设备对应的block_device
struct hlist_node s_instances
用于挂到链表file_system_type ->fs_supers
void *s_fs_info
指向保存特定文件系统的结构,比如ext2_sb_info
struct list_head s_inodes
文件系统所有打开文件的inode链表
块组描述符
data block 是用来放置文件内容数据地方,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种而已。在格式化时 block 的大小就固定了,且每个 block 都有编号,以方便 inode 的记录。 不过要注意的是,由于 block 大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量并不相同。 因为 block 大小而产生的 Ext2 文件系统限制如下:
| Block 大小 | 1KB | 2KB | 4KB |
| 最大单一文件限制 | 16GB | 256GB | 2TB |
| 最大文件系统总容量 | 2TB | 8TB | 16TB |
- 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
- 每个 block 内最多只能够放置一个文件的数据;
- 承上,如果文件大于 block 的大小,则一个文件会占用多个 block 数量;
- 承上,若文件小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
Block#2:块组描述符块(硬盘上的s_first_data_block+1)Block#8:块位图Block#9:索引节点位图
索引节点
Block#10:索引(开始)节点,每个文件用一个128字节(EXT4中是256字节)的唯一索引节点结构体表示
EXT2文件系统数据结构
-
在linux下,通过mkfs创建虚拟磁盘,输入命令:
mke2fs [-b blksize -N ninodes] device nblocks可创建一个带有nblocks个块(每个块大小为blksize个字节)和ninodes个索引节点的EXT2文件系统 -
虚拟磁盘布局:

struc0t ext2_super_block {
u32 s_inodes_count; // Inodes count
u32 s_blocks_count; // Blocks count
u32 s_r_blocks_count; // Reserved blocks count
u32 s_free_blocks_count; // Free blocks count
u32 s_free_inodes_count; // Free inodes count
u32 s_first_data_block; // First Data Block
u32 s_log_block_size; // Block size
u32 s_log_cluster_size; // Allocation cluster size
u32 s_blocks_per_group; // # Blocks per group
u32 s_clusters_per_group; // # Fragments per group
u32 s_inodes_per_group; // # Inodes per group
u32 s_mtime; // Mount time
u32 s_wtime; // Write time
u32 s_mnt_count; // Mount count
u16 s_max_mnt_count; // Maximal mount count
u16 s_magic; // Magic signature
// more non-essential fields
u16 s_inode_size; // size of inode structure
};
- Block#2块组描述符块(EXT2将磁盘块分成几个组。每个组有8192个块(硬盘上的大小为32K)。每组用一个块组描述符结构体描述):
struct ext2_ group_ desc (
u32
bg_ block_ bi tmap; // Bmap block number
u32 bg inode_ bi tmap; //Imap b1ock number
u32 bg inode_ table; // Indes begin block number
u16 bg_ free_ blocks_ count ; // THESE are OBVIOUS
u16 bg_ free_ inodes_ count ;
u16 bg_ used_ dirs_ count;
u16 bg_ pad; //ignore these
u32 bg_ reserved[3] ;
};
- Block#8:块位图(Bmap)(bg_block_bitmap)位图用来表示某种项的位序列,例如,磁盘块或索引节点。位图用于分配和回收项。在位图中,0位表示对应项处于FREE状态,1位表示对应项处于IN_USE状态。一个软盘有1440块。
- Block#9:索引节点位图(Imap)(bg_inode_bitmap)一个索引节点就是用来代表一个文件的数据结构。EXT2文件系统是使用有限数量的索引节点创建的。各索引节点的状态用B9中Imap中的一个位表示。在EXT2 FS中,前10个索引节点是预留的。
- 索引节点Block#10:索引(开始)节点块(bg_inode_table)每个文件都用一个128字节(EXT4中的是256字节)的独特索引节点结构体表示。


- 直接块:i_block[0]至i_block[11]指向直接磁块盘
- 间接块:i_block[12]指向一个包含256个块编号的磁盘块,每个块编号指向一个磁盘块
- 双重间接块:i_block[13]指向一个指向256个块的块,每个块指向256个磁盘块
- 三重间接块:i_block[14]对于小型EXT2文件可忽略
- 目录条目
EXT2目录条目;目录包含dir_entry_2结构,即:
struct ext2_dir_entry_2 {
u32 inode;
u16 rec_len;
u8 name_len;
u8 file_type;
char name[EXT2_NAME_LEN];
};由于每个 inode 与 block 都有编号,而每个文件都会占用一个 inode ,inode 内则有文件数据放置的 block 号码。 因此,我们可以知道的是,如果能够找到文件的 inode 的话,那么自然就会知道这个文件所放置数据的 block 号码, 当然也就能够读出该文件的实际数据了。这是个比较有效率的作法,因为如此一来我们的磁盘就能够在短时间内读取出全部的数据, 读写的效能比较好。
我们将 inode 与 block 区块用图解来说明一下,如下图所示,文件系统先格式化出 inode 与 block 的区块,假设某一个文件的属性与权限数据是放置到 inode 4 号(下图较小方格内),而这个 inode 记录了文件数据的实际放置点为 2, 7, 13, 15 这四个 block 号码,此时我们的操作系统就能够据此来排列磁盘的阅读顺序,可以一口气将四个 block 内容读出来! 那么数据的读取就如同下图中的箭头所指定的模样了。
这种数据存取的方法我们称为索引式文件系统(indexed allocation)。那有没有其他的惯用文件系统可以比较一下啊? 有的,那就是我们惯用的闪盘(闪存),闪盘使用的文件系统一般为 FAT 格式。FAT 这种格式的文件系统并没有 inode 存在,所以 FAT 没有办法将这个文件的所有 block 在一开始就读取出来。每个 block 号码都记录在前一个 block 当中, 他的读取方式有点像底下这样:
上图中我们假设文件的数据依序写入1->7->4->15号这四个 block 号码中, 但这个文件系统没有办法一口气就知道四个 block 的号码,他得要一个一个的将 block 读出后,才会知道下一个 block 在何处。 如果同一个文件数据写入的 block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的数据, 因此磁盘就会多转好几圈才能完整的读取到这个文件的内容.
我们约略来分析一下 inode / block 与文件大小的关系好了。inode 要记录的数据非常多,但偏偏又只有 128bytes 而已, 而 inode 记录一个 block 号码要花掉 4byte ,假设我一个文件有 400MB 且每个 block 为 4K 时, 那么至少也要十万笔 block 号码的记录。
所谓的间接就是再拿一个 block 来当作记录 block 号码的记录区,如果文件太大时, 就会使用间接的 block 来记录编号。如上图 1.3.2 当中间接只是拿一个 block 来记录额外的号码而已。 同理,如果文件持续长大,那么就会利用所谓的双间接,第一个 block 仅再指出下一个记录编号的 block 在哪里, 实际记录的在第二个 block 当中。依此类推,三间接就是利用第三层 block 来记录编号


遍历EXT2文件系统树
- 遍历算法:1.读取超级块2.读取块组描述符3.读取InodeBegin Block,以获取/的索引节点4.将路径名标记为组件字符串5.从3.中的跟索引节点开始搜索6.使用索引节点号ino来定位相应的索引节点7.重复第5第6步
-
举例来说,如果我想要读取 /etc/passwd 这个文件时,系统是如何读取的呢?
[root@www ~]# ll -di / /etc /etc/passwd 2 drwxr-xr-x 23 root root 4096 Sep 22 12:09 / 1912545 drwxr-xr-x 105 root root 12288 Oct 14 04:02 /etc 1914888 -rw-r--r-- 1 root root 1945 Sep 29 02:21 /etc/passwd/ 的 inode:在系统上面与 /etc/passwd 有关的目录与文件数据如上表所示,该文件的读取流程为(假设读取者身份为 vbird 这个一般身份使用者):
- 透过挂载点的信息找到 /dev/hdc2 的 inode 号码为 2 的根目录 inode,且 inode 规范的权限让我们可以读取该 block 的内容(有 r 与 x) ;
- / 的 block:
经过上个步骤取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码 (1912545); - etc/ 的 inode:
读取 1912545 号 inode 得知 vbird 具有 r 与 x 的权限,因此可以读取 etc/ 的 block 内容; - etc/ 的 block:
经过上个步骤取得 block 号码,并找到该内容有 passwd 文件的 inode 号码 (1914888); - passwd 的 inode:
读取 1914888 号 inode 得知 vbird 具有 r 的权限,因此可以读取 passwd 的 block 内容; - passwd 的 block:
最后将该 block 内容的数据读出来。
- 透过挂载点的信息找到 /dev/hdc2 的 inode 号码为 2 的根目录 inode,且 inode 规范的权限让我们可以读取该 block 的内容(有 r 与 x) ;
文件系统结构:
- 共三个级别:第一级别实现基本文件系统树,第二级别实现文件读/写函数,第三级别实现系统的挂载,卸载和文件保护
(1)1级文件函数
mkdir_creat.c : make directory, create regular file ls_cd_pwd.c : list directory, change directory, get CWD path rmdir.c : remove directory link_unlink.c : hard link and unlink files symlink_readlink.c : symbolic link files stat.c : return file information misc1.c : access,chmod, chown, utime, etc.1)mkdir算法 mkdir pathname 创建一个带路径名的新目录 2)creat算法 创建一个空的普通文件 3)rmdir算法 rmdir实现 link命令:link old_file new_file 4)unlink算法 symlink命令:symlink old_file new_file(2)2级文件函数
open_close_lseek.c : open file for RBAD | WRITE|APPEND,close file and lseek read.c : read from file descriptor of an opened regular file write.c : write to file descriptor of an opened regular file opendir_readdir.c : open and read directory1)open算法 2)lseek 3)close算法(3)3级文件函数
mount__umount.c : mount/umount file systems file_protection : access permission checking file-locking : lock/unlock files1)挂载算法 挂载操作命令: 2)卸载算法
基本文件系统
- type.h文件:包含ext2文件系统的数据结构类型
- global.c文件:这类文件包含文件系统的全局变量
- 实用程序函数util.c file:该文件包含文件系统常用的实用程序函数
get_block/put_block 将虚拟磁盘块读/写到内存的缓冲区中
iget(dev,ino) 返回一个指针,指向包含INODE(dev,ino)的内存minode
The put(INODE *mip) 释放一个mip指向用完的minode
getino() 实现文件系统树遍历算法
- mkdir命令:创建一个带目录名的新路径
- rmdir命令:可删除目录
- 2级文件系统由open,close,lseek,read,write,opendir和readdir组成
- 挂载操作命令: mount filesys mount_point 允许文件系统包含其他文件系统作为现有文件系统一部分
实践
-
dd命令的解释
dd:用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。注意:指定数字的地方若以下列字符结尾,则乘以相应的数字:b=512;c=1;k=1024;w=2参数注释:1. if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file >2. of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >3. ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。bs=bytes:同时设置读入/输出的块大小为bytes个字节。4. cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。5. skip=blocks:从输入文件开头跳过blocks个块后再开始复制。6. seek=blocks:从输出文件开头跳过blocks个块后再开始复制。注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。7. count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。8. conv=conversion:用指定的参数转换文件。ascii:转换ebcdic为asciiebcdic:转换ascii为ebcdicibm:转换ascii为alternate ebcdicblock:把每一行转换为长度为cbs,不足部分用空格填充unblock:使每一行的长度都为cbs,不足部分用空格填充lcase:把大写字符转换为小写字符ucase:把小写字符转换为大写字符swab:交换输入的每对字节noerror:出错时不停止notrunc:不截短输出文件sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。 -
1、mke2fs命令
在Linux系统下,mke2fs命令可用于创建磁盘分区上的”ext2/ext3”文件系统。
(1)语法
mke2fs(选项)(参数)
(2)常用选项
-b<区块大小>:指定区块大小,单位为字节。
-c:检查是否有损坏的区块。
-f<不连续区段大小>:指定不连续区段的大小,单位为字节。
-F:不管指定的设备为何,强制执行mke2fs。
-i<字节>:指定”字节/inode”的比例。
-N<inode数>:指定要建立的inode数目。
-l<文件>:从指定的文件中,读取文件中损坏区块的信息。
-L<标签>:设置文件系统的标签名称。
-m<百分比值>:指定给管理员保留区块的比例,预设为5%。
-M:记录最后一次挂入的目录。
-q:执行时不显示任何信息。
-r:指定要建立的ext2文件系统版本。
-R=<区块数>:设置磁盘阵列参数。
-S:仅写入superblock与group descriptors,而不更改inode able inode bitmap以及bitmap。
-v:执行时显示详细信息。
-V:显示版本信息。
(3)参数
设备文件:指定要创建的文件系统的分区设备文件名。
块数:指定要创建的文件系统的磁盘块数量。
(4)实例
创建指定的ext2文件系统:
$ sudo mke2fs –q /dev/hda1 -
2、mkfs命令
在Linux系统下,mkfs命令用于在设备上(通常为硬盘)创建Linux文件系统,mkfs命令本身并不执行建立文件系统的工作,而是去调用相关的程序来执行。
(1)语法
mkfs(选项)(参数)
(2)常用选项说明
-t<文件系统类型>:指定要建立的文件系统类型。
-v:显示版本信息与详细的使用方法。
-V:显示简要的使用方法。
-c:在制作档案系统前,检查该partition是否有坏轨。
(3)参数
文件系统:指定要创建的文件系统对应的设备文件名。
块数:指定文件系统的磁盘块数。
(4)实例
在/dev/hda5上建立一个msdos的档案系统,同时检查是否有坏轨存在,并且过程详细列出:
$ sudo mke2fs –q /dev/hda1将/dev/sda6格式化为ext3格式,/dev/sda7格式化为ext2格式:
$ sudo mkfs –t ext3 /dev/sda6 $ sudo mkfs –t ext2 /dev/sda7
-
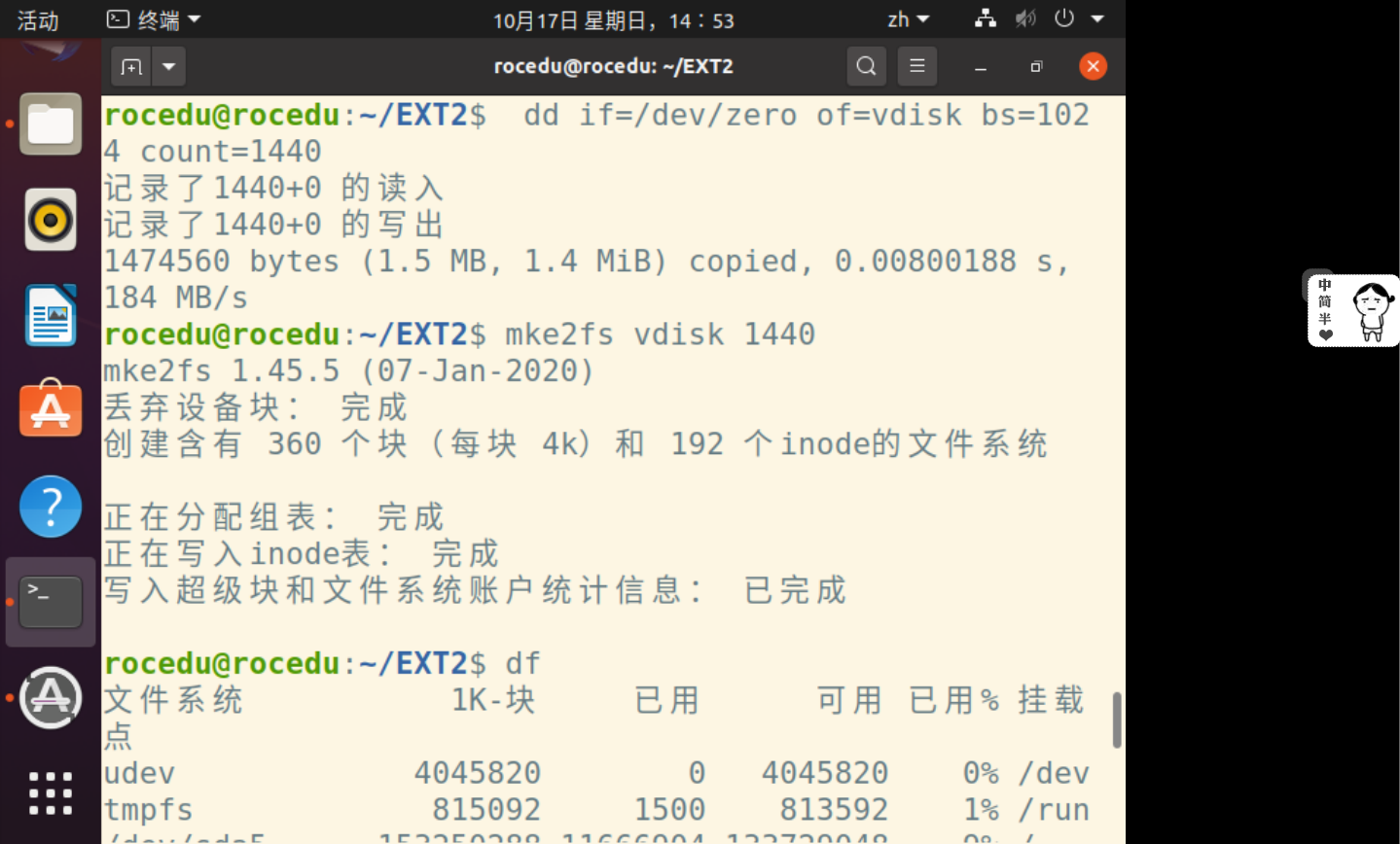
创建虚拟磁盘
在名为vdisk的虚拟磁盘文件上创建一个EXT2文件系统,有1440个大小为1KB的块。dd if=/dev/zero of=vdisk bs=1024 count=1440 mke2fs vdisk 1440