降维
数学知识
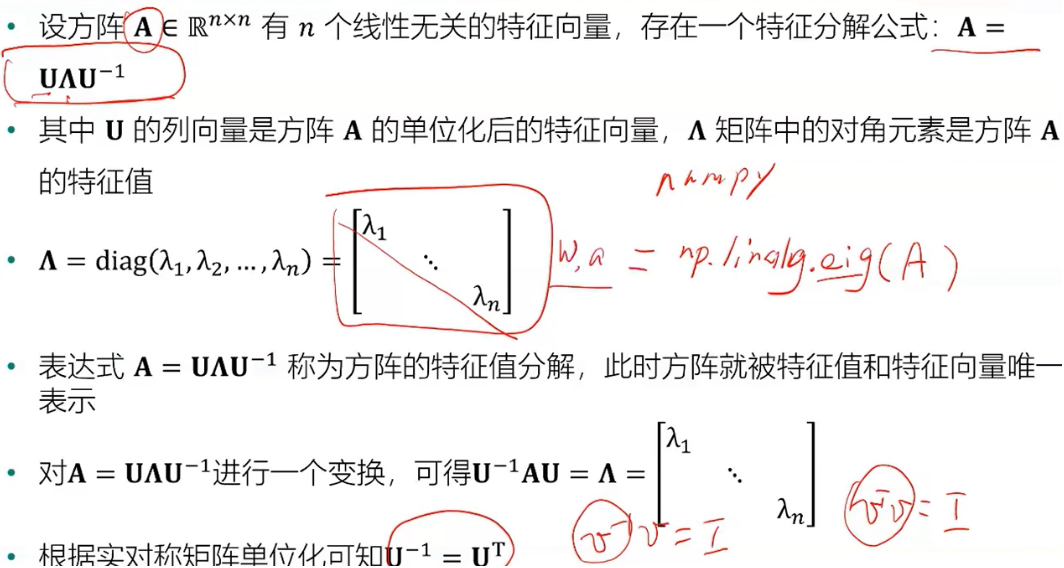
- 特征向量: 设A是n阶方阵,如果有常数λ和n维非零列向量α的关系式Aα=λα成立,则称λ为方阵A的特征值,非零向量α称为方阵A的对应于特征值λ的特征向量
- 特征值分解
降维

主成分分析

模型求解

- 方差最大化

- 算法流程

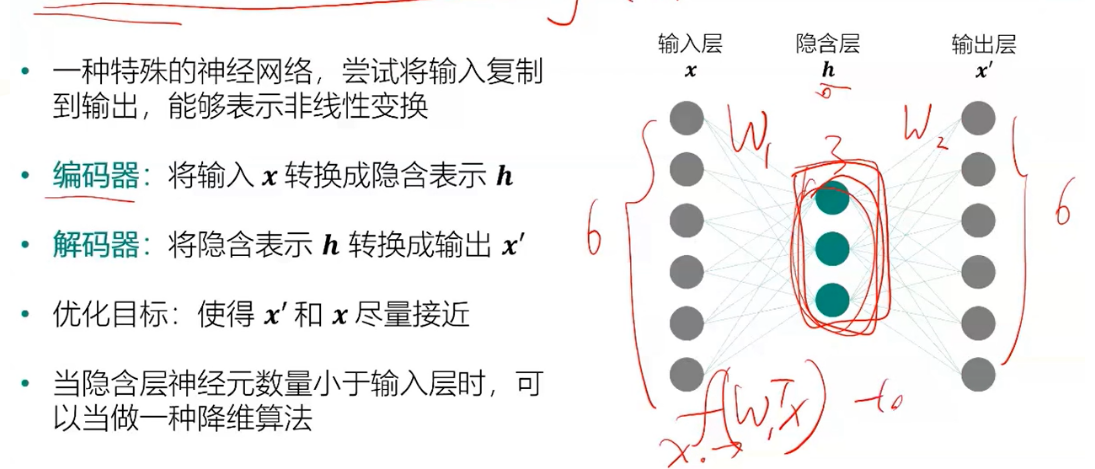
自编码器
深层自编码器

python实现PCA算法
1234567891011121314151617181920212223import numpy as np
#PCA算法
def principal_component_analysis(X, l):
X = X - np.mean(X, axis=0)#对原始数据进行中心化处理
sigma = X.T.dot(X)/(len(X)-1) # 计算协方差矩阵
a,w = np.linalg.eig(sigma) # 计算协方差矩阵的特征值和特征向量
sorted_indx = np.argsort(-a) # 将特征向量按照特征值进行排序
X_new = X.dot(w[:,sorted_indx[0:l]])#对数据进行降维****Y=XW
return X_new,w[:,sorted_indx[0:l]],a[sorted_indx[0:l]] #返回降维后的数据、主成分、对应特征值
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline
#使用make_regression生成用于线性回归的数据集
x, y = datasets.make_regression(n_samples=200,n_features=1,noise=10,bias=20,random_state=111)
##将自变量和标签进行合并,组成一份二维数据集。同时对两个维度均进行归一化。
x = (x - x.mean())/(x.max()-x.min())
y = (y - y.mean())/(y.max()-y.min())
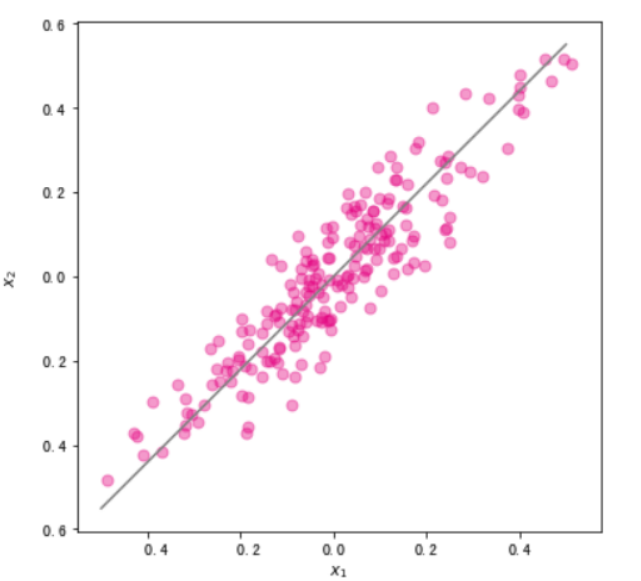
###可视化展示
fig, ax = plt.subplots(figsize=(6, 6)) #设置图片大小
ax.scatter(x,y,color="#E4007F",s=50,alpha=0.4)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
1234567891011121314151617181920212223242526272829303132333435363738394041#调用刚才写好的PCA算法对数据进行降维
import pandas as pd
X = pd.DataFrame(x,columns=["x1"])
X["x2"] = y
X_new,w,a = principal_component_analysis(X,1)
#直线的斜率为w[1,0]/w[0,0]。将主成分方向在散点图中绘制出来
import numpy as np
x1 = np.linspace(-.5, .5, 50)
x2 = (w[1,0]/w[0,0])*x1
fig, ax = plt.subplots(figsize=(6, 6)) #设置图片大小
X = pd.DataFrame(x,columns=["x1"])
X["x2"] = y
ax.scatter(X["x1"],X["x2"],color="#E4007F",s=50,alpha=0.4)
ax.plot(x1,x2,c="gray") # 画出第一主成分直线
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
#使用散点图绘制降维后的数据集
import numpy as np
fig, ax = plt.subplots(figsize=(6, 2)) #设置图片大小
ax.scatter(X_new,np.zeros_like(X_new),color="#E4007F",s=50,alpha=0.4)
plt.xlabel("First principal component")
#导入olivettifaces人脸数据集
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces()
faces.data.shape
#随机排列
rndperm = np.random.permutation(len(faces.data))
plt.gray()
fig = plt.figure(figsize=(9,4) )
#取18个
for i in range(0,18):
ax = fig.add_subplot(3,6,i+1 )
ax.matshow(faces.data[rndperm[i],:].reshape((64,64)))
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
plt.show()

1234567891011121314#将人脸数据从之前的4096维降低到20维
%time faces_reduced,W,lambdas = principal_component_analysis(faces.data,20)
#将降维后得到的20个特征向量表示出来
fig = plt.figure( figsize=(18,4))
plt.gray()
for i in range(0,20):
ax = fig.add_subplot(2,10,i+1 )
#将降维后的W每一列都提出,从4096长度向量变成64×64的图像
ax.matshow(W[:,i].reshape((64,64)))
plt.title("Face(" + str(i) + ")")
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
plt.show()

使用PCA对新闻进行降维和可视化
1234567891011121314151617181920212223#引入数据,因为是中文所以要设置encoding参数为utf8,sep参数为
import pandas as pd
news = pd.read_csv("./input/chinese_news_cutted_train_utf8.csv",sep=" ",encoding="utf8")
#加载停用词
stop_words = []
file = open("./input/stopwords.txt")
for line in file:
stop_words.append(line.strip())
file.close()
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words=stop_words,min_df=0.01,max_df=0.5,max_features=500)
news_vectors = vectorizer.fit_transform(news["分词文章"])
news_df = pd.DataFrame(news_vectors.todense())
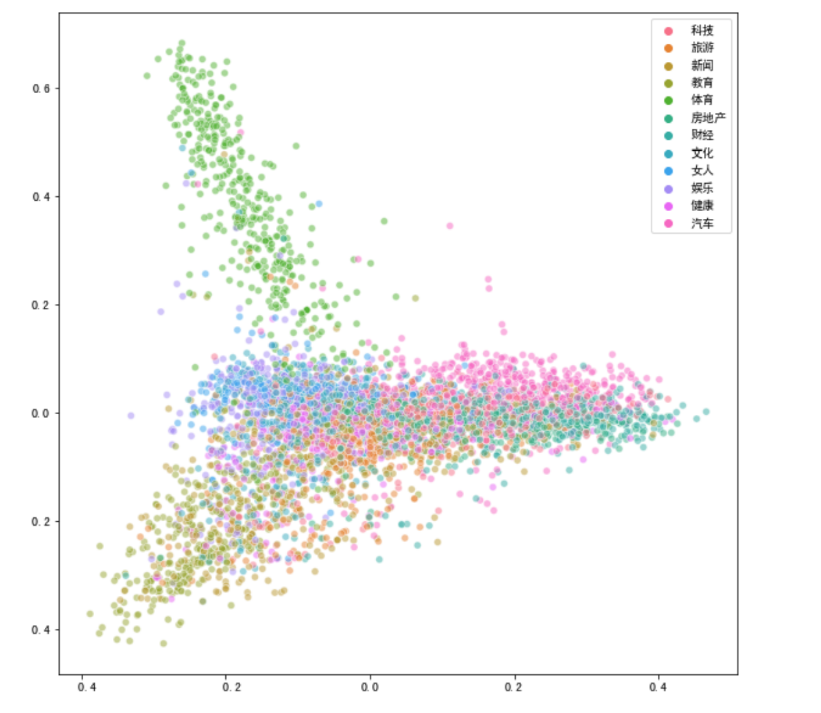
#使用PCA将数据降维至二维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
news_pca = pca.fit_transform(news_df)
#可视化
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
sns.scatterplot(news_pca[:,0], news_pca[:,1],hue = news["分类"].values,alpha=0.5)
123456789101112#采用t-SNE降维方法
from sklearn.manifold import TSNE
#先降到20维
pca10 = PCA(n_components=20)
news_pca10 = pca10.fit_transform(news_df)
#再降到2维
tsne_news = TSNE(n_components=2, verbose=1)
#输出运行时间
%time tsne_news_results = tsne_news.fit_transform(news_pca10)
#可视化
plt.figure(figsize=(10,10))
sns.scatterplot(tsne_news_results[:,0], tsne_news_results[:,1],hue = news["分类"].values,alpha=0.5)
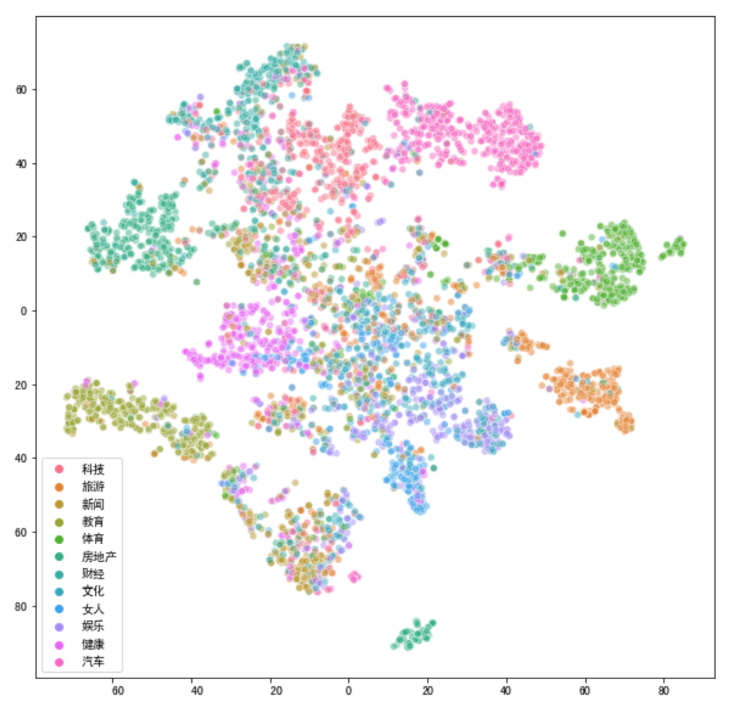
由上面结果得出,t-SNE降维方法效果更好些