该程序脱胎于嵩天老师的爬取中国大学排名实例程序,但由于网页的变动,嵩天老师的程序在运行中出现了一些问题,这爬取程序主要是在源程序的基础上进行了一些修改,使得程序正确运行,以及一些问题的处理
爬取地址:https://www.shanghairanking.cn/rankings/bcur/2020
修改后的源代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def get_html_text(url): 6 try: 7 r = requests.get(url, timeout=40) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 return "" 13 14 15 def fill_univ_list(ulist, html): 16 soup = BeautifulSoup(html, "html.parser") 17 for tr in soup.find('tbody').children: 18 if isinstance(tr, bs4.element.Tag): 19 tds = tr('td') 20 ulist.append([tds[0].text.strip(),tds[1].text.strip(),tds[2].text.strip(),tds[4].text.strip(),tds[5].text.strip()]) 21 22 def print_univ_list(ulist, num): 23 print("{:^10} {:^6} {:^10} {:^10} {:^10}".format("排名","学校","省市","得分","教学层次",chr(12288))) 24 for i in range(num): 25 u = ulist[i] 26 print("{:^10} {:^10} {:^10} {:^12} {:^12}".format(u[0],u[1],u[2],u[3],u[4],chr(12288))) 27 28 def main(): 29 uinfo = [] 30 url = 'https://www.shanghairanking.cn/rankings/bcur/2020' 31 html = get_html_text(url) 32 fill_univ_list(uinfo,html) 33 print_univ_list(uinfo,20) 34 main()
运行结果:
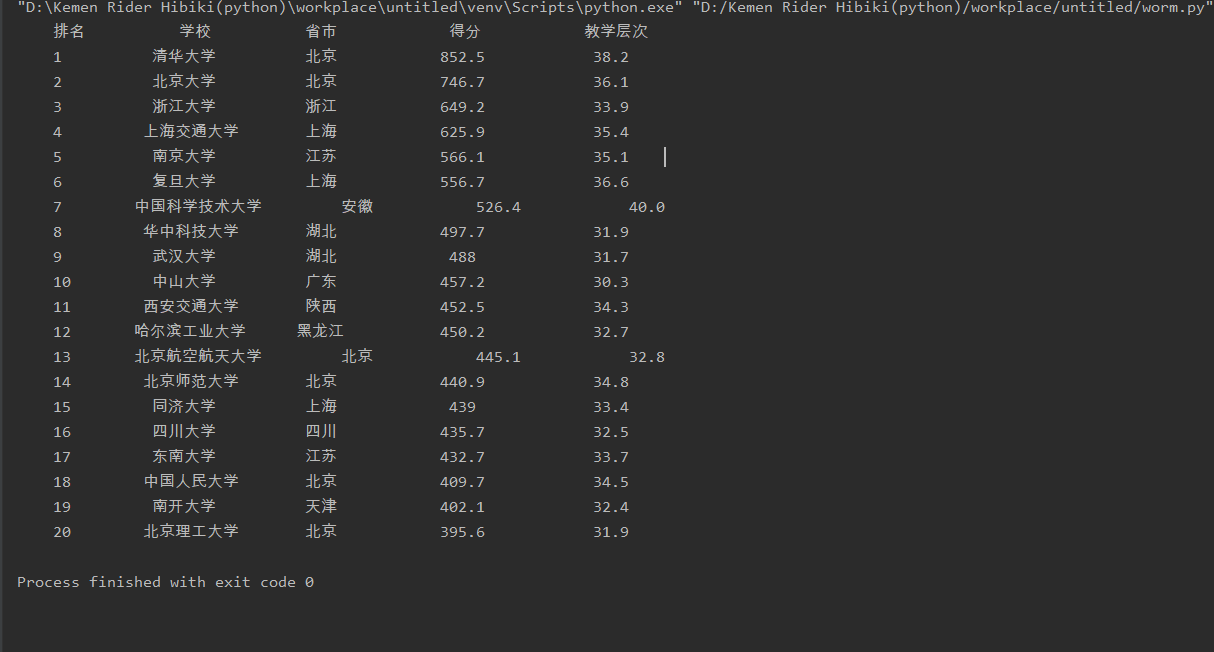
问题处理:
嵩天老师源程序:
1 import requests 2 3 from bs4 import BeautifulSoup 4 5 import bs4 def getHTMLText(url): 6 7 try: 8 9 r = requests.get(url, timeout=30) 10 11 r.raise_for_status() 12 13 r.encoding = r.apparent_encoding 14 15 return r.text 16 17 except: 18 19 return "" 20 21 22 23 def fillUnivList(ulist, html): 24 25 soup = BeautifulSoup(html, "html.parser") 26 27 for tr in soup.find('tbody').children: 28 29 if isinstance(tr, bs4.element.Tag): 30 31 tds = tr('td') 32 33 ulist.append([tds[0].string, tds[1].string, tds[3].string]) 34 35 36 37 def printUnivList(ulist, num): 38 39 tplt = "{0:^10} {1:{3}^10} {2:^10}" 40 41 print(tplt.format("排名","学校名称","总分",chr(12288))) 42 43 for i in range(num): 44 45 u=ulist[i] 46 47 print(tplt.format(u[0],u[1],u[2],chr(12288))) 48 49 50 51 def main(): 52 53 uinfo = [] 54 55 url = 'https://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' 56 57 html = getHTMLText(url) 58 59 fillUnivList(uinfo, html) 60 61 printUnivList(uinfo, 20) # 20 univs 62 63 main()
直接运行报错如下:
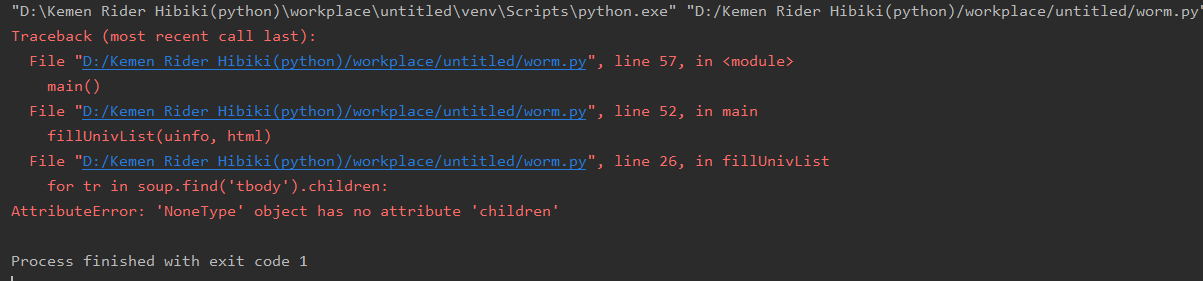
解决方式:将原来代码中的网页url链接更换为https://www.shanghairanking.cn/rankings/bcur/2020(目前最新可用)
更换url后运行报错运行如下:
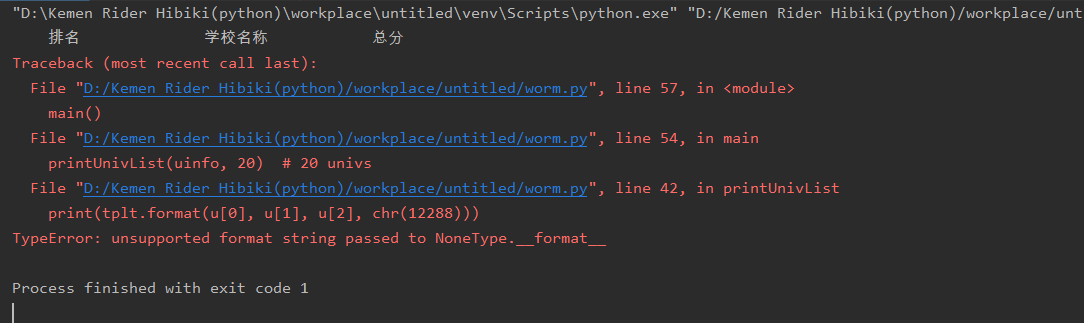
解决方式:
没有想到很好的解决方法,尝试了几个,最后都失败了,于是就干脆一点,将代码中的:
ulist.append([tds[0].string, tds[1].string, tds[3].string])
换成:
ulist.append([tds[0].text, tds[1].text, tds[2].text])
即可成功出结果,运行截图:
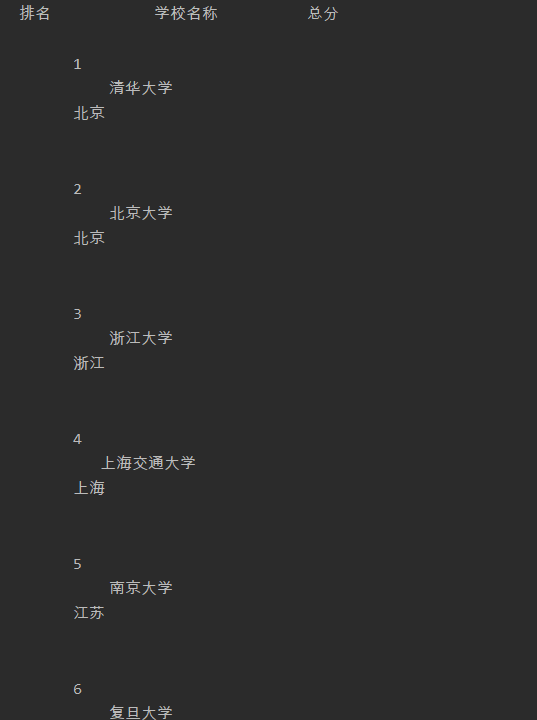
注:本文主要侧重点为问题的解决,爬取内容和格式可以自行决定,如有不对之处,请大家指正