-
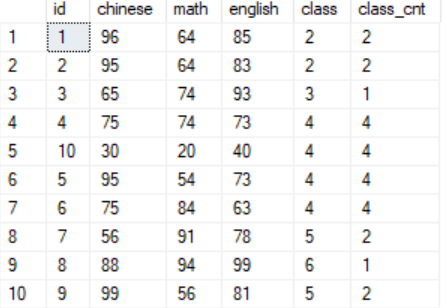
1 select * from scores

- 使用TOP限制结果集,WITH TIES作用-包括最后一行取值并列的结果
1 --查询english最高的前3名 2 select top 3 with ties id,chinese,math,english 3 from scores 4 order by english desc

1 --查询出现次数最多的chinese分数值 2 select top 1 with ties chinese, count(*) as 次数 --COUNT()需要和group by一起使用 3 from scores 4 group by chinese 5 order by count(*) desc

1 --查询总成绩前20%学生成绩 2 select top 20 percent with ties id, chinese, math, english, chinese+math+english as total 3 from scores 4 order by chinese+math+english desc

-
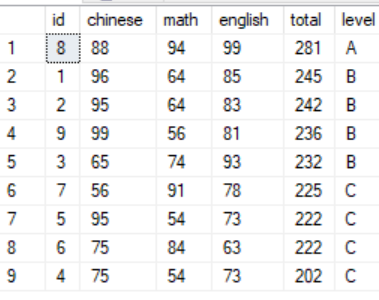
1 select id, chinese, math, english, chinese+math+english as total, level = 2 case 3 when chinese+math+english > 270 then 'A' 4 when chinese+math+english > 230 then 'B' 5 else 'C' 6 end 7 from scores 8 order by chinese+math+english desc
-
1 --将查询结果保存到新表中 2 --使用'#'将新表标识临时表,生存期与创建此局部临时表的用户的连接生存期相同,只在当前连接中使用 3 --使用'##'将新表标识全局临时表,生存期与创建此局部临时表的用户的连接生存期相同,可被所有的连接使用 4 --将上一步查询的结果存入新表 5 select id, chinese, math, english, chinese+math+english as total, level = 6 case 7 when chinese+math+english > 270 then 'A' 8 when chinese+math+english > 230 then 'B' 9 else 'C' 10 end 11 into global_scores --全局新表 12 from scores 13 order by chinese+math+english desc 14 go 15 select * from global_scores

1 --在永久表中查询level为B的学生 2 select * from global_scores 3 where level = 'B'
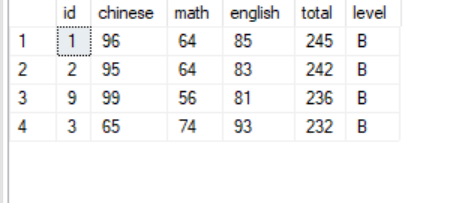
1 --将查询结果保存到新表中 2 --使用'#'将新表标识临时表,生存期与创建此局部临时表的用户的连接生存期相同,只在当前连接中使用 3 --使用'##'将新表标识全局临时表,生存期与创建此局部临时表的用户的连接生存期相同,可被所有的连接使用 4 --将上一步查询的结果存入新表 5 select id, chinese, math, english, chinese+math+english as total, level = 6 case 7 when chinese+math+english > 270 then 'A' 8 when chinese+math+english > 230 then 'B' 9 else 'C' 10 end 11 into #temp_scores --临时表 12 from scores 13 order by chinese+math+english desc 14 go 15 select * from #temp_scores --可像永久表一样查询 16 where level = 'B'
- 并运算UNION
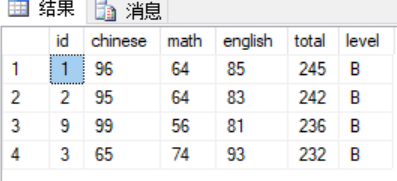
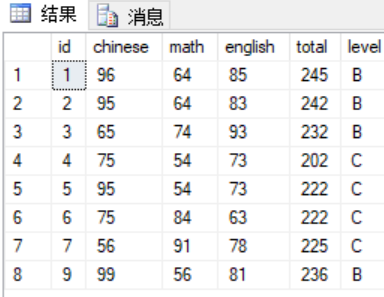
1 select * from global_scores 2 where level = 'B' 3 union 4 select * from global_scores 5 where level = '
- 交运算INTERSECT
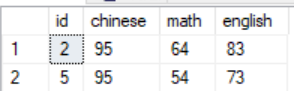
1 select * from scores where chinese = 95 2 intersect 3 select * from scores where math = 64

- 差运算EXCEPT
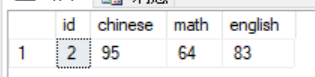
select * from scores where chinese = 95
1 select * from scores where chinese = 95 2 intersect 3 select * from scores where math = 64
- 使用子查询进行基于集合的测试
1 --子查询,查询与id为2的学生chinese成绩相同的学生 2 select * from scores 3 where chinese in 4 ( 5 select chinese from scores where id = 2 6 ) 7 and id != 2

- 使用子查询进行比较测试
-
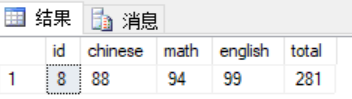
1 --查询成绩最高的 2 select *, chinese+math+english as total 3 from scores where chinese+math+english = 4 ( 5 select MAX(chinese+math+english) from scores 6 )
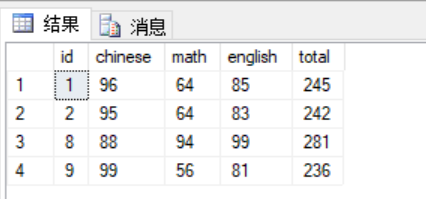
1 --查询成绩高与平均分的学生 2 select *, chinese +math + english as total from scores 3 where chinese + math + english > 4 ( 5 select AVG(chinese +math + english) from scores 6 )
-
使用子查询进行存在性测试
1 select * from info

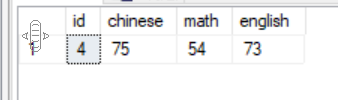
1 --查询名字为'd'的学生成绩 2 select * from scores 3 where exists 4 ( 5 select * from info where scores.id = info.id and info.name = 'd' 6 )
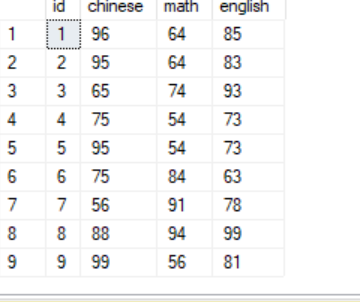
以下情况起不到选择作用,会返回所有结果1 select * from scores 2 where exists 3 ( 4 select * from scores where chinese > 80 5 )
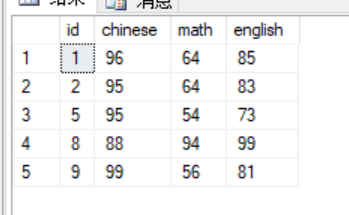
改成这样则可以,可能因为子查询只查一个表的时候,会导致exists返回的值总是true或总是false的情况(对于每一层外查询,exists内执行的子查询是一样的),而与外查询中的表连接后,因为每一层外查询对应的值不同,所以每一次执行的子查询结果都不同,exists会有true或false,达到选择的目的
如上面一个查询语句中的select * from scores where chinese > 80,该语句总是true,因为一直存在>80的数据,而对于下面这一查询语句,因为外查询是一行一行查的,对于每一行外查询,它的id值都是不同的(依次为1,2,3,4……),所以子查询中的select * from scores b where a.id = b.id and chinese > 80,条件:a.id = b.id并没有一直成立,所以可能返回true或false1 select * from scores a 2 where exists 3 ( 4 select * from scores b where a.id = b.id and chinese > 80 5 )
以下数据库数据借用:https://blog.csdn.net/mrbcy/article/details/68965271 -
替代表达式的子查询
1 --替代表达式的子查询是指在SELECT语句的选择列表中嵌入一个只返回一个标量值的SELECT语句,这个查询语句通常是通过一个聚合函数来返回一个单值 2 --以下查询名为李军的学生所选课程数目 3 select sno, sname, 4 ( 5 select COUNT(*) from students 6 join scores on students.sno = scores.sno 7 where students.sname = '李军' 8 )as course_cnt 9 from students 10 where students.sname = '李军'
- 派生表
1 --派生表(内联视图)是将子查询作为一个表来处理,这个由子查询产生的新表就被称为“派生表”,类似于临时表 2 --一下查询同时操作系统和计算机导论的学生 3 select students.sno,students.sname 4 from 5 ( 6 select * from scores
7 where scores.cno = (select cno from courses where courses.cname = '操作系统') 8 )as t1 9 join 10 ( 11 select * from scores 12 where scores.cno = (select cno from courses where courses.cname = '计算机导论') 13 )as t2 14 on t1.sno = t2.sno 15 join students on t1.sno = students.sno
当然也可用以下查询实现
1 select sno,sname from students where sno in ( 2 select sno from scores where cno = (select cno from courses where courses.cname = '计算机导论')) 3 and sno in ( 4 select sno from scores where cno = (select cno from courses where courses.cname = '操作系统'))
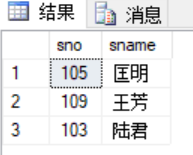
返回结果是相同的
- 开窗函数
一组行被称为一个窗口,开窗函数是指可以用于“分区”或“分组”计算的函数,这些函数结核OVER字句对组内的数据进行编号,并进行求和、计算平均值等统计。
如SUM、AVG等函数
- 将OVER字句与聚合函数结合使用
-
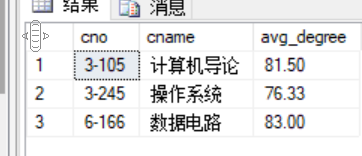
1 --查询每门课的平均分,over作用:按课号分好组,然后求平均分 2 select distinct courses.cno, cname,CAST( 1.0*AVG(degree)over(partition by scores.cno)as decimal(5,2)) as avg_degree 3 from courses join scores on courses.cno = scores.cno 4 5 --大小为5,保留两位小数 6 --as decimal(5,2) 7 8 --cast(xxx as decimal)
-
- 将OVER字句与排名函数一起使用
- 排名函数为分区中的每一行返回一个排名值,根据所用函数的不同,某些行可能与其他行具有相同的排名值,排名函数具有不确定性。
- RANK()函数:相同的值会有相同排名
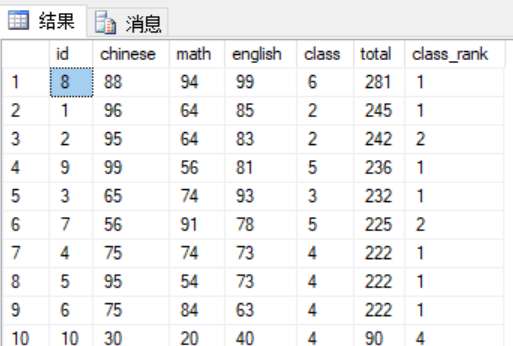
1 --查询各学生的总分班级排名 2 select *, chinese+math+english as total, 3 RANK() over 4 (partition by class order by chinese+math+english desc) as class_rank 5 from scores 6 order by chinese+math+english desc
- DENSE_RANK():用法同RANK(),但排名的取值是连续的
1 --DENSE_RANK查询各学生的总分班级排名 2 select *, chinese+math+english as total, 3 DENSE_RANK() over 4 (partition by class order by chinese+math+english desc) as class_rank 5 from scores 6 order by chinese+math+english desc
注意最后一个学生的名次,与RANK比较

- NTILE():分组
1 --NTILE:将学生按成绩划分到3个组中 2 select *, chinese+math+english as total, 3 NTILE(3) over 4 (order by chinese+math+english desc) as ngroup 5 from scores

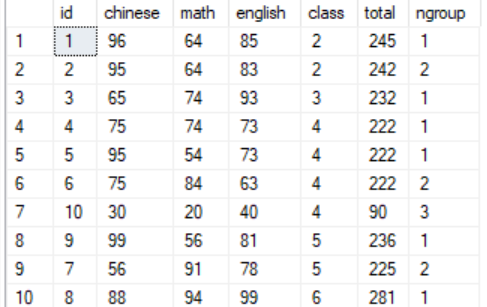
1 --NTILE:将学生以班级为单位按成绩划分到3个组中 2 select *, chinese+math+english as total, 3 NTILE(3) over 4 (partition by class order by chinese+math+english desc) as ngroup 5 from scores
- ROW_NUMBER:返回结果集中每个分区内行的序列号
1 select *, chinese+math+english as total, 2 ROW_NUMBER() over 3 (PARTITION BY class order by chinese+math+english desc) as ngroup 4 from scores

- RANK()函数:相同的值会有相同排名
- 排名函数为分区中的每一行返回一个排名值,根据所用函数的不同,某些行可能与其他行具有相同的排名值,排名函数具有不确定性。
- 将OVER字句与聚合函数结合使用
-
公用表表达式
将查询语句产生的结果集指定一个临时命名的名字,这些命名的结果集就称为公用表表达式1 --查询时显示学生所在班级人数 2 with class_cnt(class, cnt) as 3 ( 4 select class,count(*) from scores 5 group by class) 6 select scores.*,class_cnt.cnt as class_cnt from scores 7 join class_cnt on scores.class = class_cnt.class