问题一 条件码
条件码寄存器中保存着单个位的条件码,由CPU维护,如:
CF:进位标志
ZF:零标志
SF:符号标志
OF:溢出标志
有几类指令能够修改条件码:
算术指令:既改变操作数,也有可能改变条件码。
CMP指令:右操作数减左操作数,只可能改变条件码。
TEST指令:两操作数相与,只可能改变条件码。
条件码寄存器不能直接读取,有三种方法:
set指令:根据条件码,设置一个字节。
jump指令:根据条件码进行跳转,即控制的条件转移。
cmov条件传送指令:根据条件码决定是否进行mov操作。
问题二 RIO包
- RIO,全称 Robust I/O,即健壮的IO包。它提供了与系统I/O类似的函数接口,在读取操作时,RIO包加入了读缓冲区,一定程度上增加了程序的读取效率。
- RIO函数提供了带缓冲的读操作,与无缓冲的写操作
- RIO帮助我们处理了可修复的错误类型:EINTR。考虑read和write在阻塞时被某个信号中断,在中断前它们还未读取/写入任何字节,则这两个系统调用便会返回-1表示错误,并将errno置为EINTR。这个错误是可以修复的,并且应该是对用户透明的,用户无需在意read 和 write有没有被中断,他们只需要直到read 和 write成功读取/写入了多少字节,所以在RIO的rio_read()和rio_write()中便对中断进行了处理。
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
ssize_t rio_readn(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0)
{
if ((nread = read(fd, bufp, nleft)) < 0)
{
if (errno == EINTR)
{
nread = 0;
}
else
{
return -1;
}
}
else if (nread == 0)
{
break;
}
nleft -= nread;
bufp += nread;
}
return (n-nleft);
}
ssize_t rio_writen(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nwritten;
char *bufp = usrbuf;
while (nleft > 0)
{
if ((nwritten = write(fd, bufp, nleft)) <= 0)
{
if (errno == EINTR)
{
nwritten = 0;
}
else
{
return -1;
}
}
nleft -= nwritten;
bufp += nwritten;
}
return n;
}
问题三 套接字接口
应用层通过传输层进行数据通信时,TCP和UDP会遇到同时为多个应用程序进程提供并发服务的问题。多个TCP连接或多个应用程序进程可能需要 通过同一个TCP协议端口传输数据。为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了称为套接字 (Socket)的接口,区分不同应用程序进程间的网络通信和连接。
生成套接字,主要有3个参数:通信的目的IP地址、使用的传输 层协议(TCP或UDP)和使用的端口号。Socket原意是“插座”。通过将这3个参数结合起来,与一个“插座”Socket绑定,应用层就可以和传输 层通过套接字接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
加载套接字库,创建套接字(WSAStartup()/socket());
绑定套接字到一个IP地址和一个端口上(bind());
将套接字设置为监听模式等待连接请求(listen());
请求到来后,接受连接请求,返回一个新的对应于此次连接的套接字(accept());
用返回的套接字和客户端进行通信(send()/recv());
关闭套接字,关闭加载的套接字库(closesocket()/WSACleanup());
加载套接字库,创建套接字(WSAStartup()/socket());
向服务器发出连接请求(connect())
关闭套接字,关闭加载的套接字库(closesocket()/WSACleanup());
问题四 信息=位+上下文
位:位是数据存储的最小单位,位又称为比特(bit),8位=1字节(8bit=1Byte),每个字节表示程序中的某些文本字符。每一位的状态只能是0或1:1bit=0或者1bit=1。字母用一个字节表示进行表示和存储,而一个汉字是两个字节表示和存储。 程序的生命周期是从一个源程序(或者说是源文件)开始的。源程序实际上就是一个由值0和1组成的位序列。
上下文(context)理解:
1.简单的说就是跟当前主题有关的所有内容
2.说到程序的上下文,就是当前这段程序之上和之下的程序段。因为有些变量、函数不一定都定义在一起,而且一个程序段不是一行就能写完,之间有有很多的联系。就像看英语阅读或者小说等都需要前后理解的。
3.“设备上下文”(the device context):是一种包含有关某个设备(如显示器或打印机)的绘制属性信息的Windows数据结构。所有绘制调用都通过设备上下文对象进行,这些对象封装了用于绘制线条、形状和文本的 Windows API。设备上下文允许在 Windows 中进行与设备无关的绘制。设备上下文可用于绘制到屏幕、打印机或者图元文件.
问题五 测量程序运行时间的方法
-
方法一:通过间隔计数(timer)
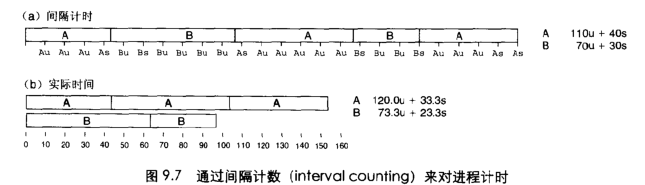
- 缺点:精度不够高,不能用于程序运行持续时间小于100ms的测量。
- 优点:准确性不是十分依赖于系统负载,并且在执行时间大于1s的程序上,与理论值之间的误差很低。
- 调用库函数times来读进程的计时器,时间测量值是以时钟滴答为单位表示的,times返回的是从系统启动开始经过的时钟滴答总数。
-
方法二:周期计数器(counter)
- 缺点:只能用汇编语言读取,不能保证通用性,在系统负载很大的情况下,将极大的影响准确性
- 优点:精度高,并且因为得到的是程序执行期间所经过的时钟周期数,所以可大致估算出在不同硬件平台上程序的执行时间。
- 为了给计时测量提供更高的准确度,很多处理器还包含一个运行在时钟周期级别的计时器,它是一个特殊的寄存器,每个时钟周期它都会自动加1。
- 由于基于counter的测量方法受影响的因素较多,主要是上下文切换和高速缓存操作的影响,所以高精度计时必须设法消除上述两种因素的影响,
-
方法三:基于gettimeofday函数的测量

- gettimeofday是一个库函数,包含在time.h中。它的功能是查询系统时钟,以确定当前的日期和时间。它类似于周期计时,除了测量时间是以秒为单位,而不是时钟周期为单位的。
- 在使用gettimeofday()函数时,第二个参数一般都为空,因为我们一般都只是为了获得当前时间,而不用获得timezone的数值。