0.abstract
LDP近年来受到广泛关注。现有的LDP保证的协议中,用户在将数据分享给聚合器之前,在本地对数据进行编码和扰动。然而,由于对于不同问题的不同隐私保护偏好,用户不愿意回答所有的问题。在本论文中,我们提出了一种方法来解决数据扰动的挑战,同时考虑用户的隐私偏好。具体来说,我们首先在LDP的框架上提出了一种双向采样技术值扰动。然后,我们结合双采样机制和用户隐私偏好,以避免丢失数据的扰动。理论分析和一组数据集上的实验证明所提机制的有效性。
1.introduction
LDP已经作为一种解决方法对于隐私保护数据收集和分析,因为他提供了可证明的隐私保护。LDP保证的协议一般可以分为Encode-Perturb-Aggregate范式。用户将数据编码成一种特俗的数据格式,然后出于隐私考虑扰动编码值,最后,所有扰动的值聚合到不信任的收集者。
虽然LDP可以平衡用户的隐私和数据可用性,但是现存的方法认为被调查的用户会遵循收集过程的真实性。然而,在调查过程中,用户可能拒绝吐露一些问题,由于一下担心:1)隐私保护水平不符合预期;2)用户仅仅就是不想告诉。由于扰动机制需要输入,所以用户可能会随机选择答案(或者NO)来进行扰动(我们称其为假答案)。在扰动空间中,假答案会导致回避偏见。在论文中,我们考虑了“提供空值”应用程序去考虑假答案。首次考虑了用户协作对估计精度的理解,首次提出了双采样样本机制并将其用于数值扰动,然后将双向样本推广到空值扰动。
创新点:
- 第一次考虑到并不是所有的用户都会提供真实数据,提出的缺失数据扰动框架为提高数据可用性提供了新的见解。
- 我们提出了一种数据扰动的双向采样机制。可以代替Harmony进行均值估计。此外,扩展了双样本,能够扰动空值数据。
- 提出的框架可以估计在隐私预算下提供真实数据用户的比率,该机制可以研究如何通过聚合器去设置合理的隐私预算。
2.Preliminaries and problem definition
2.1 Local Differentital Privacy(LDP)

LDP的标准解决方法是随机响应RR(randomized response)。特别的是,为了收集用户的敏感信息,例如,用户是HIV携带者,RR被用来扰动真实数据,同时仍可以保证
- i)每个用户的答案提供了可信的可否认性
- ii)聚合者可以得到整个人群的无偏估计
很多前沿的机制使用RR作为中心部分来提供隐私保证,例如[13],[14]和 [8]。为了用任意数量的可能值处理分类数据,提出了K-RR。在传统的RR算法中,每个用户以P概率分享真实值,以1-P概率提供相反的答案,故在LDP中:
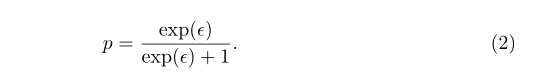
用Fr表示收集者接受到真实答案的概率,在扰动之前概率可以估计为:

f*是f的无偏估计。
近年来,有文献研究了LDP下均值估计的数值扰动问题。我们引进了Harmony和Piecewise机制。
Harmony
Harmony被提出用来收集和分析数据。包含三个步骤:discretization, perturbation and adjusting.离散化用来产生{-1,1}之间的离散值,然后用RR进行扰动,最后,为了输出无偏的值,对扰动的值进行调整。

Piecewise Mechanism(PM)
PM是另一种均值估计的扰动机制。PM的输出值在-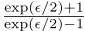 和
和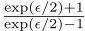 之间。PM被用来收集LDP下的单值属性。
之间。PM被用来收集LDP下的单值属性。
2.2 Problem Definition
Modeling users privacy preferences
- 当
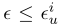 时,用户才会向收集者提供数值
时,用户才会向收集者提供数值 - 当
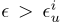 时,用户提供空值,而不是假数据
时,用户提供空值,而不是假数据
经过扰动之后,收集者计算空值率和用户的平均值

用户u的值域为[-1,1]U{T},空值率mr=空值的数量/n,均值=所有v的值的和/不是空值的个数

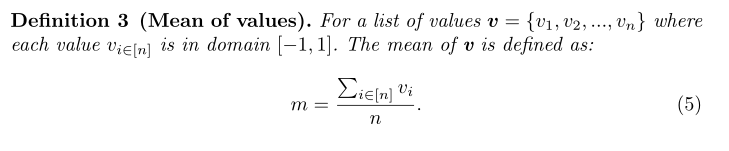
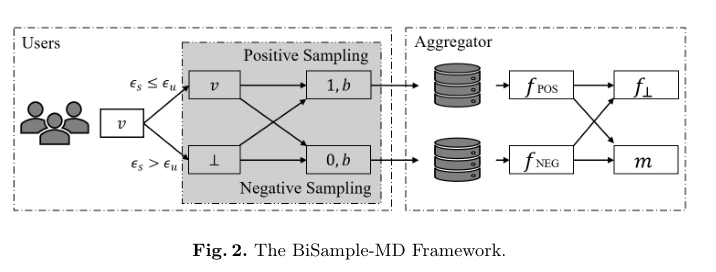
3.BiSample: Bidirectional Sampling Technique
在解决缺失数据扰动的问题之前,我们首先提出一种双向扰动机制。机制将v∈[-1,1]作为输入,输出一个扰动数组<s,b>s代表采样方向,b代表v值的采样结果。采样机制包含两个基本的采样方向:
-
Negative Sampling with LDP负采样用来估计离散化后-1的频率,扰动过程为:
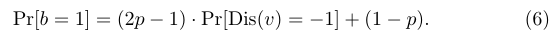
-
Positive Sampling with LDP负采样用来估计离散化后1的频率,扰动过程为:
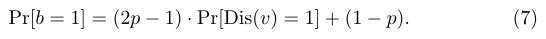
假设输入域为[-1,1],算法2展示了双向采样的伪码。在不丧失一般性前提下,当输入域为[L,U],用户
-
计算
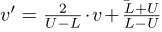
-
使用双采样机制扰动
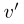
-
向收集者提供
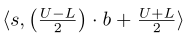

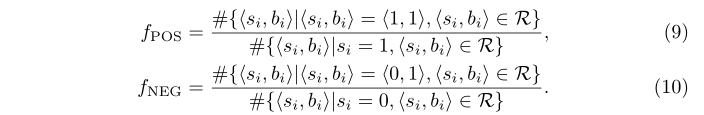
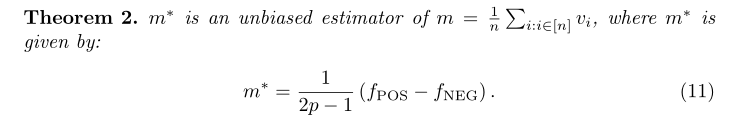
4. Using BiSample for Missing Data Perturbation

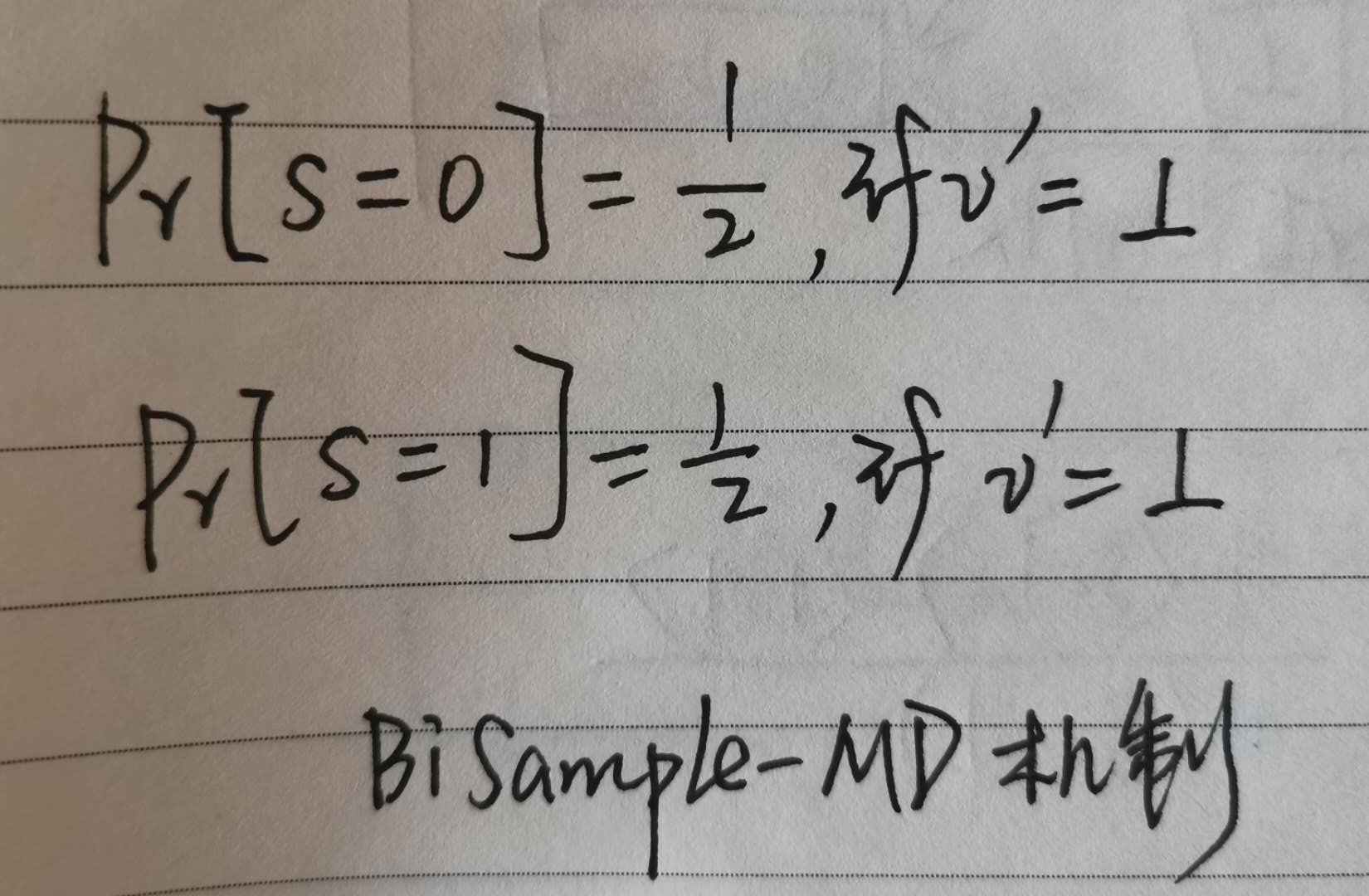
s代表提供真知的和,f代表提供空值的概率
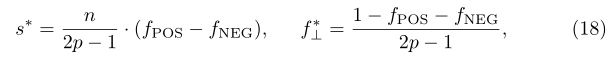
如果没有空值,则无偏估计为:
有空值的情况下,无偏估计为:

问题:
1,<s,b>中的s取0,1的概率都为1/2吗?还是v=-1时,s取0;v=1时,s取1?
2.<0,1><1,1>被用来计算平均值,那么产生的<1,0><0,0>被用来干什么?