今日学习:英语,spark基础实验全部完成,开学准备
spark实验:
第一个实验是安装相关,二到五是本机IDEA写好程序,打成jar包后到虚拟机上运行的,本次博客主要说明一下实验六和实验七中的要点,因为这两项实验花的时间比较长,调试了很多次。
实验六:
安装Flume的过程直接省略,网上有很多详细教程,直接开始介绍实验:
使用 Avro 数据源测试 Flume
Avro 可以发送一个给定的文件给 Flume,Avro 源使用 AVRO RPC 机制。请对 Flume 的相关配置文件进行设置,从而可以实现如下功能:在一个终端中新建一个文件 helloworld.txt(里面包含一行文本“Hello World”),在另外一个终端中启动 Flume 以后, 可以把 helloworld.txt 中的文本内容显示出来。
使用Flume经常需要开启多个终端窗口,因为需要一个终端窗口启动服务,届时这个终端是无法使用的
先配置avro.conf文件
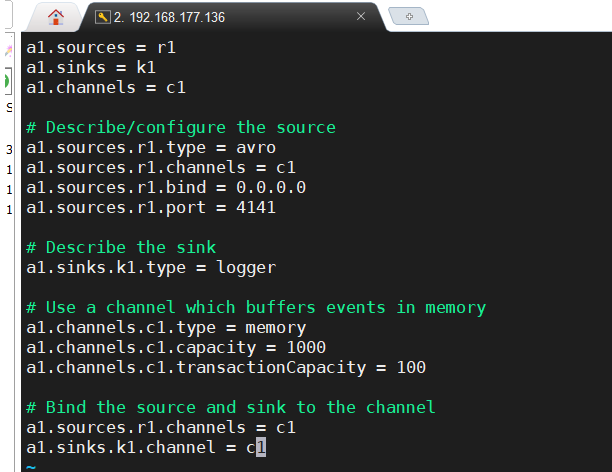
启动flume agent a1
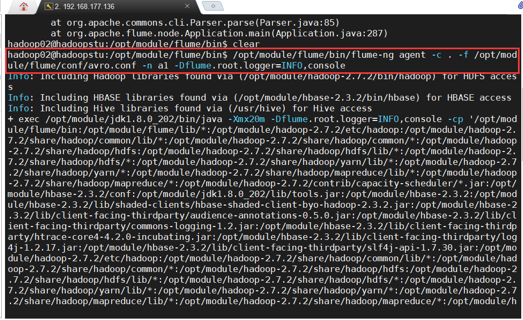

这个时候这个终端无法再输入了,因此需要开启另一个终端
打开另一个终端,开始创建文件:
再打开一个终端,这步好像可以直接在第二个终端下进行,但我还是开了第三个:

此时第一个终端有了结果:
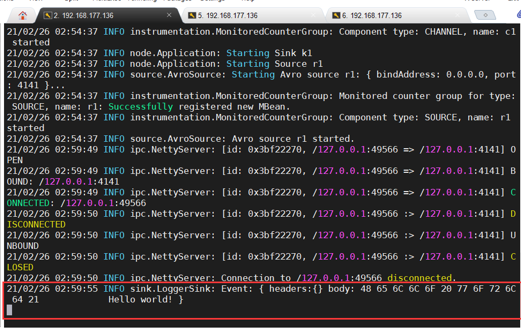
使用 netcat 数据源测试 Flume
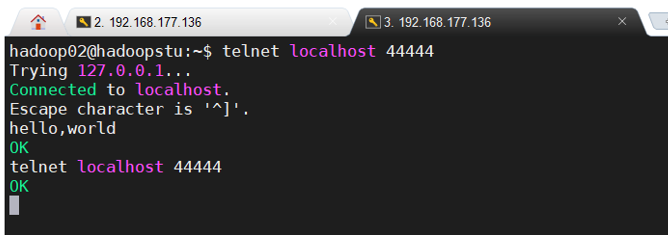
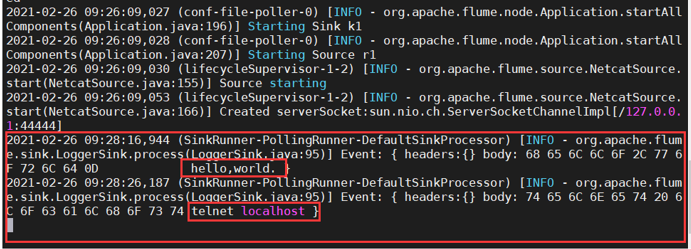
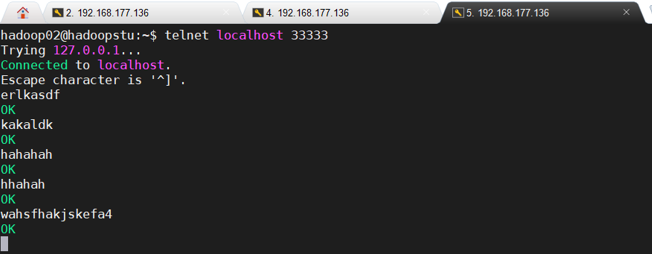
请对 Flume 的相关配置文件进行设置,从而可以实现如下功能:在一个 Linux 终端(这 里称为“Flume 终端”)中,启动 Flume,在另一个终端(这里称为“Telnet 终端”)中, 输入命令“telnet localhost 44444”,然后,在 Telnet 终端中输入任何字符,让这些字符可以 顺利地在 Flume 终端中显示出来。
创建agent配置文件
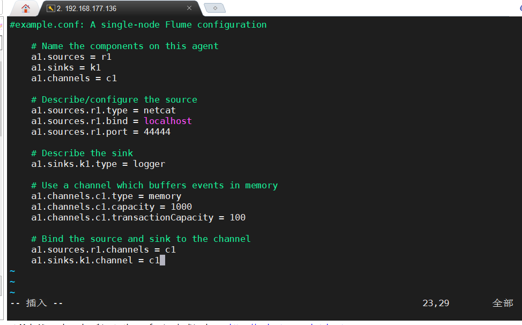
启动agent

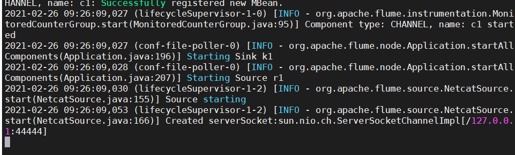
开启第二个终端进行测试:
使用 Flume 作为 Spark Streaming 数据源
Flume 是非常流行的日志采集系统,可以作为 Spark Streaming 的高级数据源。请把 Flume Source 设置为 netcat 类型,从终端上不断给 Flume Source 发送各种消息,Flume 把消息汇集 到 Sink,这里把 Sink 类型设置为 avro,由 Sink 把消息推送给 Spark Streaming,由自己编写 的 Spark Streaming 应用程序对消息进行处理。
这个实验注意将下载好的spark-streaming-flume.jar以及flume/lib下的所有文件全部复制到spark/jars/flume下(flume是新建的文件夹)
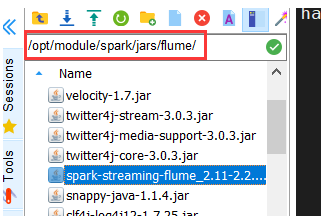
有的教程是将flume/lib下的文件复制到spark/jars文件下就行,个人不建议这么做,因为会存在不同版本的jar包冲突,这个BUG是我在写实验七的时候发生的,切记。
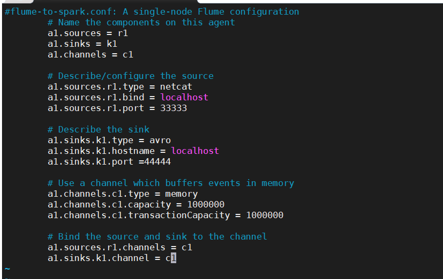
在flume/conf下配置flume-to-spark.conf
在IDEA中编写独立应用程序
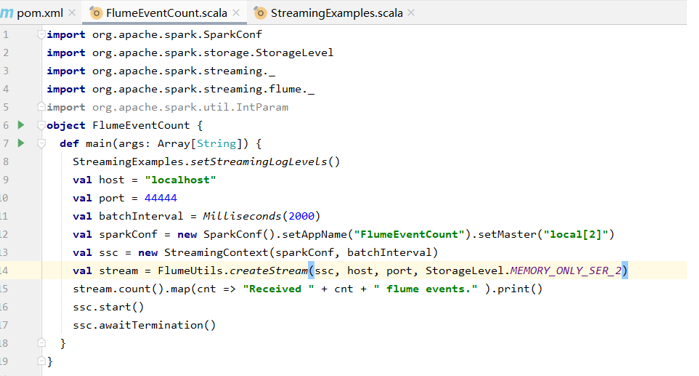

打包上传后运行,主类是FlumeEventCount

该终端运行后效果如下,由于输出的是流数据,因此会不停滚动,这个不是BUG

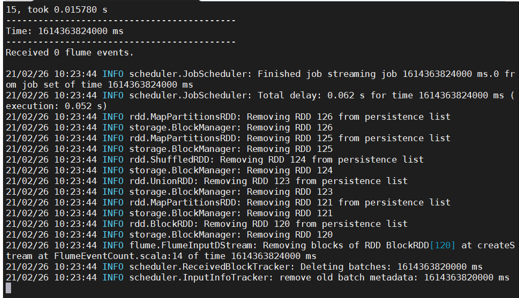
打开第二个终端运行conf


打开第三个终端
实验七
本次实验是Spark MLlib编程实战,使用的数据集是Adult数据集。下载网址:http://archive.ics.uci.edu/ml/datasets/Adult
我这里只下载了adult.data和adult.test。
在开始操作之前先检查一下数据集,正常是每行14个变量,中间用英文逗号+一个空格隔开。但我下载的adult.test中有个小开头,记得把开头去掉,否则程序运行时会出问题。而且下载的两个文件中结尾还有两个空行,保险期间我也一并删掉了。
最后数据集是这样的,我把后缀命名成了txt格式(其实没必要)


开始之前记得排除jar包冲突问题,就是我在实验六中提到的,我当时出现了这个问题,于是我重新解压spark安装包之后把jars文件替换掉了。
1.数据导入
从文件中导入数据,并转化为 DataFrame。
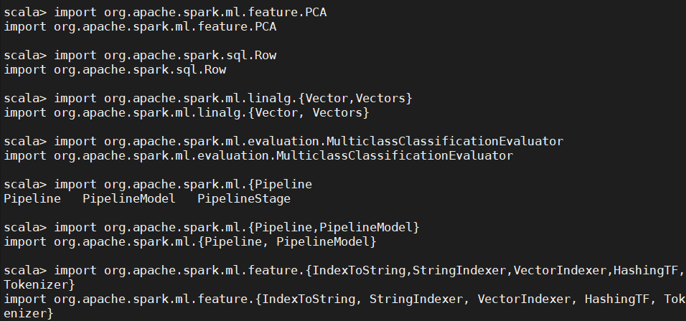
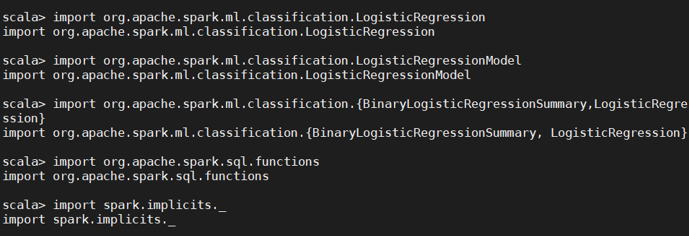
这段import包引入面向的是整个实验过程,不仅仅是DataFrame
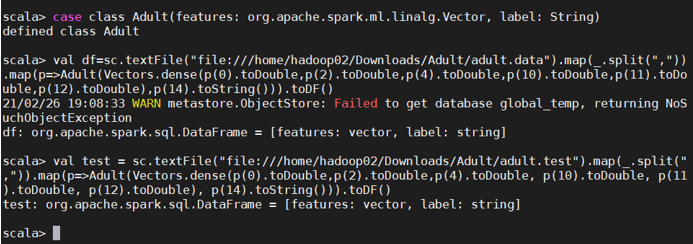
开始数据转换
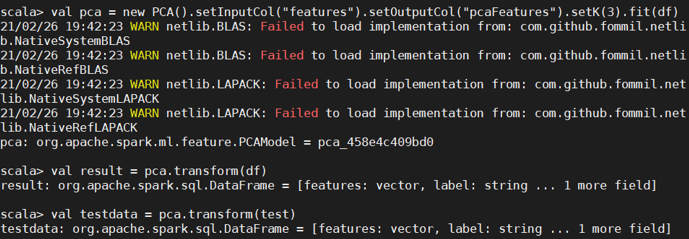
2.进行主成分分析(PCA)
对 6 个连续型的数值型变量进行主成分分析。PCA(主成分分析)是通过正交变换把一 组相关变量的观测值转化成一组线性无关的变量值,即主成分的一种方法。PCA 通过使用 主成分把特征向量投影到低维空间,实现对特征向量的降维。请通过 setK()方法将主成分数 量设置为 3,把连续型的特征向量转化成一个 3 维的主成分。
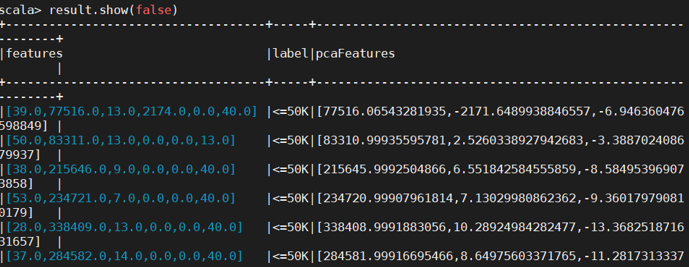
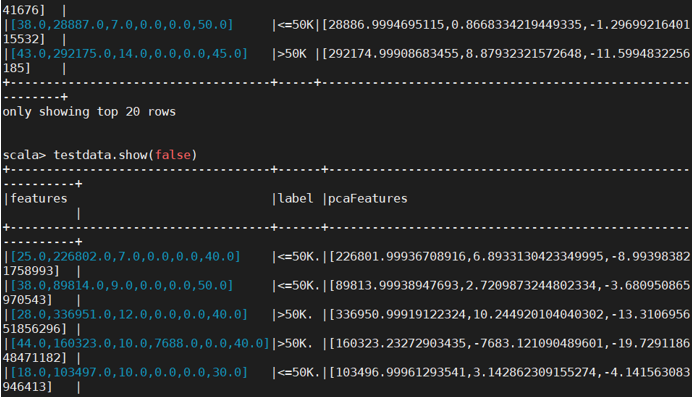
3.训练分类模型并预测居民收入
在主成分分析的基础上,采用逻辑斯蒂回归,或者决策树模型预测居民收入是否超过 50K;对 Test 数据集进行验证。

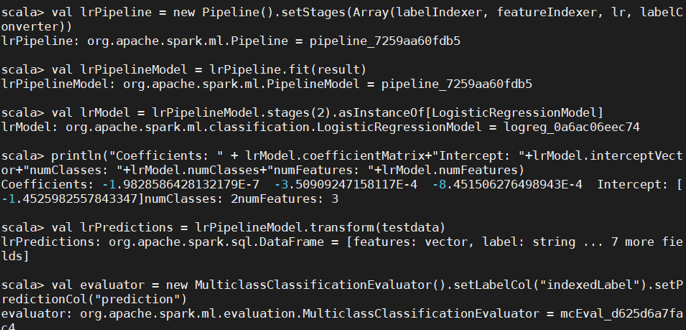
这里在输出准确率时出现了BUG,目前未能排除

4.超参数调优
利用 CrossValidator 确定最优的参数,包括最优主成分 PCA 的维数、分类器自身的参数 等。
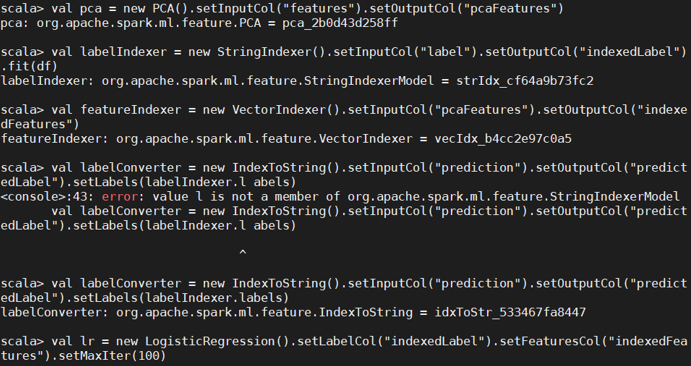
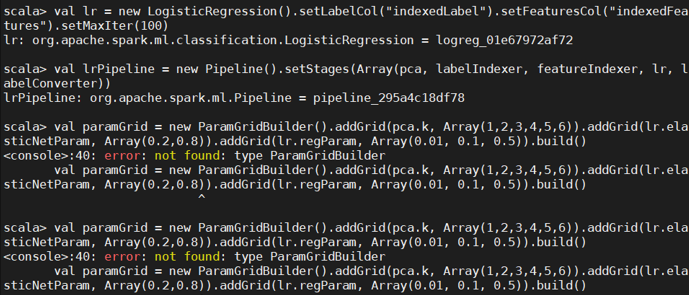
发生的错误是未导入包:

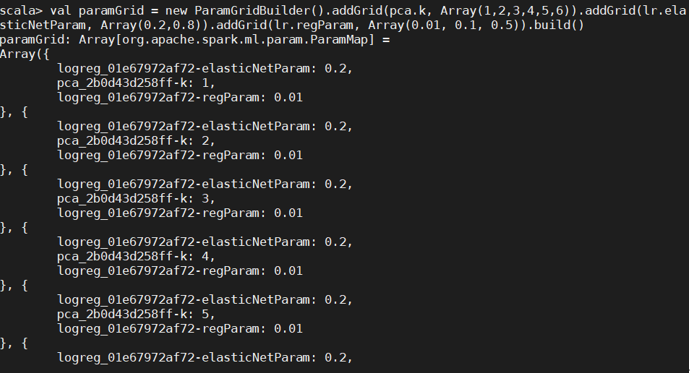
这里又缺包了
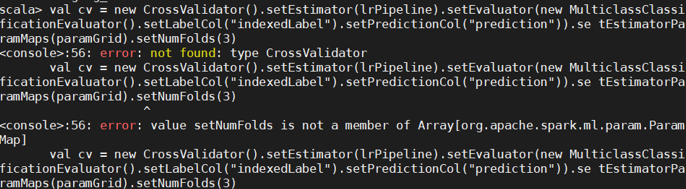
还是第三步的BUG

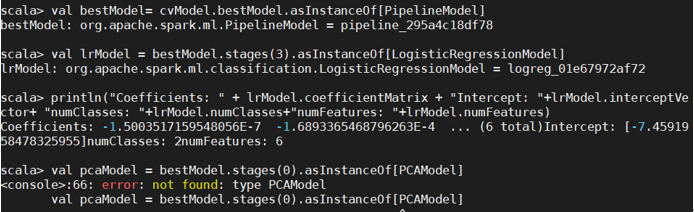
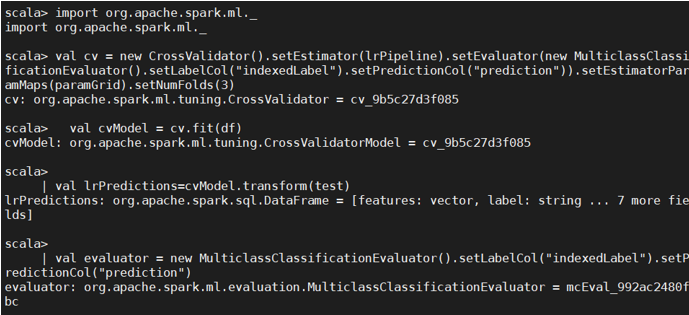
继续引包,但报错了,因为出现了包名冲突
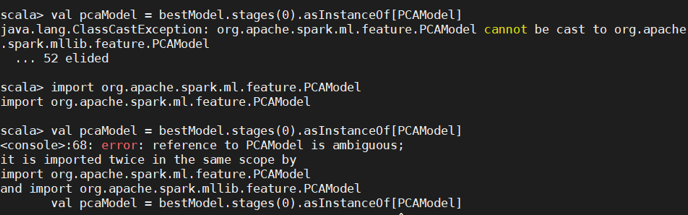
引用时把包名写全:
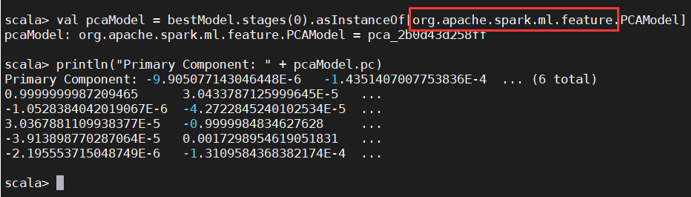
最后附上文字代码:
1.
import org.apache.spark.ml.feature.PCA import org.apache.spark.sql.Row import org.apache.spark.ml.linalg.{Vector,Vectors} import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator import org.apache.spark.ml.{Pipeline,PipelineModel} import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer,HashingTF, Tokenizer} import org.apache.spark.ml.classification.LogisticRegression import org.apache.spark.ml.classification.LogisticRegressionModel import org.apache.spark.ml.classification.{BinaryLogisticRegressionSummary, LogisticRegression} import org.apache.spark.sql.functions import spark.implicits._ case class Adult(features: org.apache.spark.ml.linalg.Vector, label: String) val df=sc.textFile("file:///home/hadoop02/Downloads/adult.data.txt").map(_.split(",")).map(p=>Adult(Vectors.dense(p(0).toDouble,p(2).toDouble,p(4).toDouble,p(10).toDouble,p(11).toDouble,p(12).toDouble),p(14).toString())).toDF() val test = sc.textFile("file:///home/hadoop02/Downloads/adult.test.txt").map(_.split(",")).map(p=>Adult(Vectors.dense(p(0).toDouble,p(2).toDouble,p(4).toDouble, p(10).toDouble, p(11).toDouble, p(12).toDouble), p(14).toString())).toDF()
2.
val pca = new PCA().setInputCol("features").setOutputCol("pcaFeatures").setK(3).fit(df) val result = pca.transform(df) val testdata = pca.transform(test) result.show(false) testdata.show(false)
3.
val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(result) labelIndexer.labels.foreach(println) val featureIndexer = new VectorIndexer().setInputCol("pcaFeatures").setOutputCol("indexedFeatures").fit(result) println(featureIndexer.numFeatures) val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer. labels) val lr = new LogisticRegression().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures").setMaxIter(100) val lrPipeline = new Pipeline().setStages(Array(labelIndexer, featureIndexer, lr, labelConverter)) val lrPipelineModel = lrPipeline.fit(result) val lrModel = lrPipelineModel.stages(2).asInstanceOf[LogisticRegressionModel] println("Coefficients: " + lrModel.coefficientMatrix+"Intercept: "+lrModel.interceptVector+"numClasses: "+lrModel.numClasses+"numFeatures: "+lrModel.numFeatures) val lrPredictions = lrPipelineModel.transform(testdata) val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction") val lrAccuracy = evaluator.evaluate(lrPredictions) println("Test Error = " + (1.0 - lrAccuracy))//由于上一步出BUG了,这步未能实现
4.
val pca = new PCA().setInputCol("features").setOutputCol("pcaFeatures") val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(df) val featureIndexer = new VectorIndexer().setInputCol("pcaFeatures").setOutputCol("indexedFeatures") val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer.labels) val lr = new LogisticRegression().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures").setMaxIter(100) val lrPipeline = new Pipeline().setStages(Array(pca, labelIndexer, featureIndexer, lr, labelConverter)) //引包 //ml.后可以直接写_,代表ml下全引入 import org.apache.spark.ml.tuning.ParamGridBuilder val paramGrid = new ParamGridBuilder().addGrid(pca.k, Array(1,2,3,4,5,6)).addGrid(lr.elasticNetParam, Array(0.2,0.8)).addGrid(lr.regParam, Array(0.01, 0.1, 0.5)).build() //这次是全引入 import org.apache.spark.ml._ val cv = new CrossValidator().setEstimator(lrPipeline).setEvaluator(new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction")).se tEstimatorParamMaps(paramGrid).setNumFolds(3) val cvModel = cv.fit(df) val lrPredictions=cvModel.transform(test) val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction") val lrAccuracy = evaluator.evaluate(lrPredictions)//BUG println("准确率为"+lrAccuracy)//BUG //继续引包,最后发现这里使用的是org.apache.spark.ml.feature.PCAModel //这里不再掩饰上述截图中的错误了,直接引用的包吧 import org.apache.spark.ml.feature.PCAModel val bestModel= cvModel.bestModel.asInstanceOf[PipelineModel] val lrModel = bestModel.stages(3).asInstanceOf[LogisticRegressionModel] println("Coefficients: " + lrModel.coefficientMatrix + "Intercept: "+lrModel.interceptVector+ "numClasses: "+lrModel.numClasses+"numFeatures: "+lrModel.numFeatures) val pcaModel = bestModel.stages(0).asInstanceOf[PCAModel] println("Primary Component: " + pcaModel.pc)