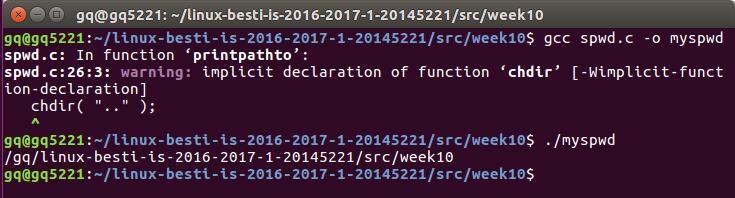
Linux下C语言编程实现spwd函数
介绍
- spwd函数
- 功能:显示当前目录路径
- 实现:通过编译执行该代码,可在终端中输出当前路径
代码实现
代码链接
- 代码托管链接:spwd.c
所需结构体、函数、系统调用等查询(前期准备)
st_ino
- 执行指令查看stat:
man 2 stat-

-
其中用红框标注的引起了我的注意:
ino_t st_ino /* inode number */ -
而这一个结构体的成员表示,文件的索引信息(进入点),“number”告诉我们它是一个数字表示,而不是一个确切的路径,这就好比我们有时候用文件描述符来操作文件,而不用字符数组(文件名)来操作。
-
也就是说,我们想要找到文件的路径,
st_ino这个信息试关键。
-
opendir
- 要读取路径,必定要先打开路径,路径如何打开可以用指令查询一下:
man -k dir | grep open - 根据查询结果接着输入指令:
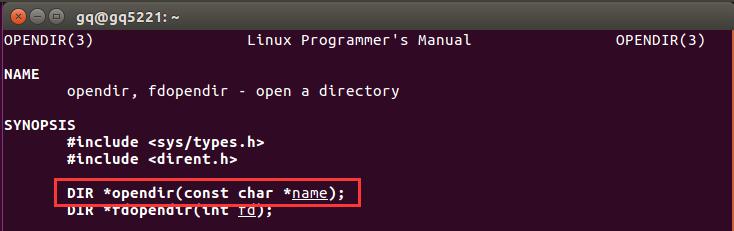
man 3 opendir查看详细信息-
-
也就是说输入参数为一个文件(目录)名,才能打开该目录,并返回为DIR类型
-
- 而我们知道,当前目录的目录名为
.,父级目录的目录名为..,知道目录名就好办了。
readdir
-
st_ino只能表示该文件的索引信息,那如何将它的各个父目录读取出来呢?肯定跟读取有关(read) -
所以我们用指令搜索查询一下:
man -k dir | grep read -
找到相关项后输入指令:
man 3 readdir-

-
根据上述可观察到,该函数属于库<dirent.h>中,readdir函数的返回类型为一个
dirent结构体,结构体的各个成员变量在截图中有明显标出 -
可以容易发现,其中有
d_ino和d_name[256],这两者应该是一一对应的,也就是说我只要取得了其索引号,就可以将其翻译为文件名了。
-

代码介绍
- 代码由4个函数组成,分别是:
main函数:主函数get_inode函数:取某个文件的索引信息(进入点)printpathto函数:打印路径inum_to_name函数:将长整型的索引信息转化为字符串的形式
整体编写思路(算法)
- Step1:调用
get_inode函数,来取得当前目录文件的st_ino值; - Step2:进入父目录后,打开当前目录文件,并读取该目录的
dirent结构体; - Step3:判断此时打开的目录文件的索引节点号是否与正确的子目录(进入该目录之前的那个目录)的节点号相同。若相同,输出相应
dirent结构体中的d_name[256]变量;反之,继续打开后一个该目录文件的后一个位置。(此处有点像打开某个具体的文本文件,会有一个文件指针不停地向后移动,直到EOF); - Step4:重复Step3,直到“父目录的索引节点”等于“该目录的索引节点”(意为到达了根目录);
- Step5:输出结果,程序完毕
- 补充:分析上述流程不难发现,大致的思路是从当前文件夹下一直
cd到根文件夹下,实现目录搜索;而我们人习惯的阅读方式则是先看根文件夹再看到当前文件夹下,加上关键的函数又是可以重复调用的,所以此处我们可以采取递归函数的特性,来实现这一点。
get_inode函数
ino_t get_inode( char *fname )
{
struct stat info;
if ( stat( fname , &info ) == -1 ){
fprintf(stderr, "Cannot stat ");
perror(fname);
exit(1);
}
return info.st_ino;
}
- 说明:该函数为取某个文件的“索引节点”信息,相关函数都已经不陌生了,在课本上以及之前博客中都有介绍,不再赘述。
printpathto函数
void printpathto( ino_t this_inode )
{
ino_t my_inode ;
char its_name[BUFSIZ];
if ( get_inode("..") != this_inode )
{
chdir( ".." );
inum_to_name(this_inode,its_name,BUFSIZ);
my_inode = get_inode( "." );
printpathto( my_inode );
printf("/%s", its_name );
}
}
- 说明:
- 该部分函数实现了递归调用,先不看其中的
inum_to_name函数,结构还是很清晰的 - 传入一个索引节点,并求得父目录的索引节点,判断两者是否相等,相等则说明已经到了根文件夹下,可以终止递归调用
- 如若不相等,则进入父目录,然后通过
inum_to_name函数功能,将之前的目录名拷贝到its_name字符数组中,准备输出打印 - 紧接着将进入后的父目录当作当前目录,反复执行操作,指导“第2点”中说的终止条件
- 该部分函数实现了递归调用,先不看其中的
inum_to_name函数
void inum_to_name(ino_t inode_to_find , char *namebuf, int buflen)
{
DIR *dir_ptr;
struct dirent *direntp;
dir_ptr = opendir( "." );
if ( dir_ptr == NULL ){
perror( "." );
exit(1);
}
while ( ( direntp = readdir( dir_ptr ) ) != NULL )
if ( direntp->d_ino == inode_to_find )
{
strncpy( namebuf, direntp->d_name, buflen);
namebuf[buflen-1] = '�';
closedir( dir_ptr );
return;
}
fprintf(stderr, "error looking for inum %d
", (int) inode_to_find);
exit(1);
}
- 说明:
- 该部分是整个代码的关键,起着将索引节点转化为相应的文件名的过程
- 首先我们得打开一个目录(opendir),只有打开目录后才能正常读取目录(readdir),才能获取到
dirent结构体,才能将索引节点转化为相应的文件名 - 读取的部分很有意思,类似于我们读取文件一样。
- 要注意的是我们已经在该函数的父函数中进入了之前目录的父目录,可是现在该目录下有这么多目录,怎样才能找到进之前的目录呢?
- 为了能正确找到之前的目录,我们将一个个读取的目录的
ino信息与传参进来的ino信息做比对,如果相同,则说明找到了正确目录,把文件名拷贝到字符数组就行;如果比对结果不相同,则继续读取下一个目录。