期中总结
前半学期的主要学习内容是学习mooc课程《Linux内核分析》以及课本《Linux内核设计与实现》。
所涉及知识点总结如下:
1. Linux内核启动的过程——以MenuOS为例
1.1 计算机的启动过程
- CPU启动后,BIOS程序开始执行,检测硬件,然后加载引导程序BootLoader和硬盘的第一个扇区MBR。
- BootLoader会将操作系统初始化,启动操作系统。
Linux内核的启动有三个参数:
- kernel
- initrd
- root所在目录、分区。
内核会首先生成0号进程idle,然后0号进程产生1号进程init,1号进程是所有用户态进程的祖先,0号进程是所有内核线程的祖先。
1号进程是Linux启动后所执行的第一个进程;
0号进程是当没有进程可以执行时,会执行0号进程。
1.2 进程的描述
进程的描述依靠进程描述符task_struct数据结构,部分定义如下:
struct task_struct {
volatile long state; /* 进程状态 */
void *stack; /* 进程的内核堆栈 */
atomic_t usage;
unsigned int flags; /* 每个进程的标识符 */
unsigned int ptrace;
/ #ifdef CONFIG_SMP // 条件编译,SMP多处理器相关
……
int on_rq // 运行队列相关,下面几行是进程队列和调度相关。
……
struct list_head tasks // 进程链表
……
next_task
prev_task // 对进程链表的管理
tty_struct // 控制台
fs_struct // 文件系统
struct files_struct *files; // 打开的文件描述符列表
file_struct // 打开的文件描述符
mm_struct // 内存管理描述
struct mm_struct *mm, *active_mm; // 地址空间,内存管理。
signal_struct // 进程间通信、信号描述
struct list_head ptraced // 调试用
utime
stime // 进程时间相关
}
进程的唯一标示是pid。
1.3 进程的创建
创建进程,其本质是调用fork函数创建一个子进程,从1号进程开始,都是使用的这种方法。
Linux通过clone()系统调用实现fork()。
创建进程的大概步骤如下:
- fork()、vfork()、__clone()都根据各自需要的参数标志调用clone()。
- 由clone()去调用do_fork()。
- do_fork()调用copy_process()函数,然后让进程开始运行。
- 返回do_fork()函数,如果copy_process()函数成功返回,新创建的子进程被唤醒并让其投入运行。
部分代码示意如下:
/* 复制一个PCB */
err = arch_dup_task_struct(tsk, orig);
/* 要给新进程分配一个新的内核堆栈 */
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
/* 要修改复制过来的进程数据,比如pid、进程链表等 */
*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = 0; //eax设置为0,所以子进程返回值为0.
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
dup_task_struct // 复制pcb
alloc_thread_info_node // 创建了一个页面,其实就是实际分配内核堆栈空间的效果。
setup_thread_stack // 把thread_info的东西复制过来
也就是说,子进程的创建绝大部分内容是直接复制了父进程的进程描述符,这是它们有共同的地址空间,堆栈,和进程上下文,当写时复制的时候才会区分开。
最开始学习fork的时候提到,fork是“一次调用,两次返回”,父进程返回子进程的pid,子进程返回0,这是因为子进程复制父进程相关数据的时候,将eax设置为0。
除此之外,还有特殊设置的是sp和ip,sp指向调度到子进程时的内核栈顶,ip指向ret_from_fork,子进程就是从这条指令开始执行的。
1.4 进程调度
Linux采用的是CFS调度算法,有四个组成部分:
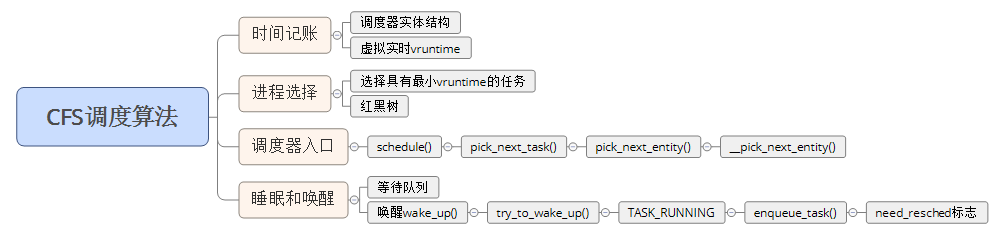
Linux的调度基于分时和优先级。
- Linux的进程根据优先级排队
- 根据特定的算法计算出进程的优先级,用一个值表示
- 这个值表示把进程如何适当的分配给CPU
- Linux进程中的优先级是动态的
- 调度程序会根据进程的行为周期性地调整进程的优先级
- 例如:
- 较长时间为被分配到cpu——↑
- 已经在cpu上运行了较长时间——↓
常见的一些函数:
nice
getpriority/setpriority 设置优先级
sched_getschedduler/sched_setscheduler
sched_getparam/sched_setparam
sched_yield
sched_get_priority_min/sched_get_priority_max
sched_rr_get_interval
进程调度的时机
- 中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();主动调度。
- 用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。用户态进程只能被动调度。
- 内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程既可以主动调度,也可以被动调度;
内核线程是只有内核态没有用户态的特殊进程
1.5 抢占和上下文切换
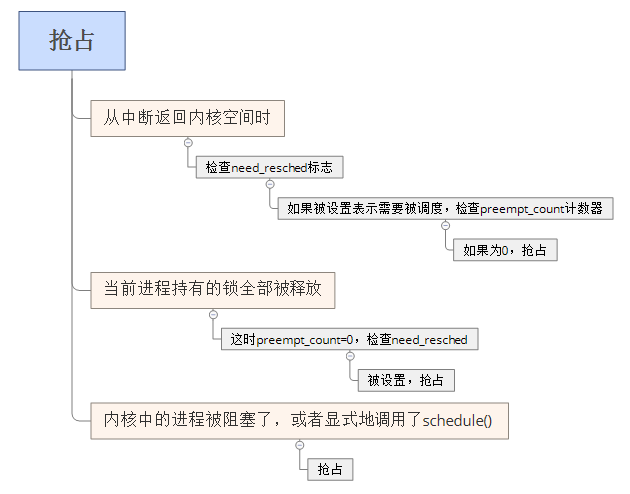
need_resched标志:
内核用这个标志来表明是否需要重新执行一次调度。
- 当某个进程应该被抢占时,scheduler_tick()会设置这个标志。
- 当一个优先级高的进程进入可执行状态时,try_to_wake_up()会设置这个标志。
- 内核检查这个标志确认其被设置,调用schedule()来切换到一个新的进程。
- 该标志对于内核来说是一个信息,表示youqitajinc应当被运行了,要尽快调用调度程序。
- 再返回用户空间以及从中断返回时,内核也会检查标志。
- 每个进程都包含一个need_resched标志,因为访问进程描述符里的数值比访问一个全局变量要快。
锁是非抢占区域的标志。实现如下:
为每个进程的thread_info中加入preempt_count计数器,初值为0,使用锁+1,释放锁-1,数值为0时,可以执行抢占。

- 挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行,但是是同一个进程,而进程上下文的切换是两个进程在切换。
- 进程上下文包含了进程执行需要的所有信息
- 用户地址空间:包括程序代码,数据,用户堆栈等
- 控制信息:进程描述符,内核堆栈等
- 硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
- schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换。
2.可执行程序的装载
2.1 预处理、编译、链接和目标文件的格式


查看一个可执行文件头部内容:
readelf -h
头部后是代码和数据,等等。
可执行程序加载的主要工作:
当创建或者增加一个进程映像的时候,系统在理论上将拷贝一个文件的段到一个虚拟的内存段
静态链接的ELF可执行文件和进程的地址空间
32位x86进程地址空间共4G,1G是内核空间。
如何加载到内存?
默认从0x8048000开始加载,然后头部需要占用一定空间,程序的实际入口可以在0x8048100等地方,即可执行文件加载到内存中开始执行的第一行代码的入口处。
一般静态链接会把所有代码放在一个代码段,
动态链接会有多个代码段。
2.2 可执行程序的装载
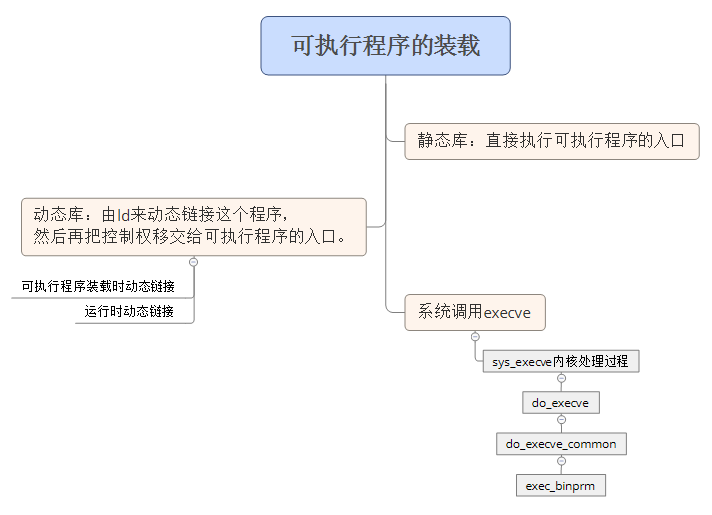
2.2.1 sys_execve的内部处理过程
1604 SYSCALL_DEFINE3(execve,
1605 const char __user *, filename,
1606 const char __user *const __user *, argv,
1607 const char __user *const __user *, envp)
1608 {
1609 return do_execve(getname(filename), argv, envp);
1610 }
1611 #ifdef CONFIG_COMPAT
1612 COMPAT_SYSCALL_DEFINE3(execve, const char __user *, filename,
1613 const compat_uptr_t __user *, argv,
1614 const compat_uptr_t __user *, envp)
1615 {
1616 return compat_do_execve(getname(filename), argv, envp);
1617 }
1618 #endif
sys_execve函数中返回了一个do_execve:
1549 int do_execve(struct filename *filename,
1550 const char __user *const __user *__argv,
1551 const char __user *const __user *__envp)
1552 {
1553 struct user_arg_ptr argv = { .ptr.native = __argv };
1554 struct user_arg_ptr envp = { .ptr.native = __envp };
1555 return do_execve_common(filename, argv, envp);
1556 }
最后一句中do_execve_common把文件名,参数和环境转换了一下。
该函数do_execve_common打开如下:
1474 file = do_open_exec(filename);
打开了一个要加载的可执行文件,然后会加载一下它的头部,建立一个结构体,把命令行参数和环境变量拷贝到结构体中;
1513 retval = exec_binprm(bprm);
对这个可执行文件的处理过程。
打开exec_binprm这个函数,可以找到一句重要代码:
1416 ret = search_binary_handler(bprm);
寻找这个我们打开的可执行文件的处理函数。
打开search_binary_handler,找到list_for_each_entry如下:
1369 list_for_each_entry(fmt, &formats, lh) {
1370 if (!try_module_get(fmt->module))
1371 continue;
1372 read_unlock(&binfmt_lock);
1373 bprm->recursion_depth++;
1374 retval = fmt->load_binary(bprm);
1375 read_lock(&binfmt_lock);
1376 put_binfmt(fmt);
1377 bprm->recursion_depth--;
1378 if (retval < 0 && !bprm->mm) {
1379 /* we got to flush_old_exec() and failed after it */
1380 read_unlock(&binfmt_lock);
1381 force_sigsegv(SIGSEGV, current);
1382 return retval;
1383 }
1384 if (retval != -ENOEXEC || !bprm->file) {
1385 read_unlock(&binfmt_lock);
1386 return retval;
1387 }
1388 }
在这个循环里寻找能够解析这个当前可执行文件的代码模块。
retval = fmt->load_binary(bprm); // 这一句中的load_binary,加载处理函数。这一句是函数指针,实际上是调用的load_elf_binary。
2.2.2 load_elf_binary的赋值和注册
/* 全局变量elf_format,把函数指针load_elf_binary**赋值**给了.load_binary */
82 static struct linux_binfmt elf_format = {
83 .module = THIS_MODULE,
84 .load_binary = load_elf_binary,
85 .load_shlib = load_elf_library,
86 .core_dump = elf_core_dump,
87 .min_coredump = ELF_EXEC_PAGESIZE,
88 };
/* 把变量elf_format**注册**进了format链表里,就可以在链表里对应elf模式中找到对应模块 */
2198 static int __init init_elf_binfmt(void)
2199 {
2200 register_binfmt(&elf_format);
2201 return 0;
2202 }
在load_elf_binary中调用了start_thread这个函数:
198 start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)/* pt_regs 是内核堆栈栈底的函数,*/
199 {
200 set_user_gs(regs, 0);
201 regs->fs = 0;
202 regs->ds = __USER_DS;
203 regs->es = __USER_DS;
204 regs->ss = __USER_DS;
205 regs->cs = __USER_CS;
206 regs->ip = new_ip; //起点位置
207 regs->sp = new_sp;
208 regs->flags = X86_EFLAGS_IF;
209 /*
210 * force it to the iret return path by making it look as if there was
211 * some work pending.
212 */
213 set_thread_flag(TIF_NOTIFY_RESUME);
214 }
215 EXPORT_SYMBOL_GPL(start_thread);
2.2.3 动态链接与静态链接
动态链接库的执行过程:
887 if (elf_interpreter) {
888 unsigned long interp_map_addr = 0;
889
890 elf_entry = load_elf_interp(&loc->interp_elf_ex,
891 interpreter,
892 &interp_map_addr,
893 load_bias);
需要加载连接器
静态链接的执行过程:
912 else {
913 elf_entry = loc->elf_ex.e_entry;
直接把elf文件的entry地址赋给elf_entry。
但是在start_thread中是直接用的elf_entry:
start_thread(regs,elf_entry, bprm->p);
1.如果是一个静态连接的文件,elf_entry就是指的main函数开始的位置
2.如果是一个需要依赖动态链接库的文件,elf_entry指向的是动态链接器的起点,将cpu控制权交给ld来加载依赖库并完成动态链。
3. 系统调用
3.1 用户态和内核态
用户通过库函数与系统调用联系起来。
- 内核态
在高执行级别下,代码可以执行特权指令,访问任意的物理地址。 - 用户态:
代码的掌控范围受到限制。
intel x86 CPU有四个权限分级,0-3。Linux只取两种,0是内核态,3是用户态
区分权限级别使得系统更加稳定。
如何区分用户态与内核态?
cs:eip。[代码段选择寄存器:偏移量寄存器]
通过cs寄存器的最低两位,表示当前代码的特权级:
【针对逻辑地址】
0xc0000000以上的空间只能在内核态下访问
0x00000000-0xbfffffff两种状态下都可以访问
如何进行切换?
中断。
3.2 中断处理过程
中断处理是从用户态进入内核态的主要方式。
- 寄存器上下文
从用户态切换到内核态时,必须保存用户态的寄存器上下文到内核堆栈中,同时会把当前内核态的一些信息加载,例如cs:eip指向中断处理程序入口。 - 中断发生后的第一件事就是保存现场 - SAVE_ALL
中断处理结束前最后一件事是恢复现场 - RESTORE_ALL
3.3 系统调用的“三张皮”

3.4 系统调用在内核代码中的处理过程
以system_call为例:
trap_init里面有一个set_system_trap_gate函数,函数定义中有系统调用的中断向量SYSCALL_VECTOR****和汇编代码入口system_call。
一旦执行int 0x80,系统直接跳转到system_call来执行。
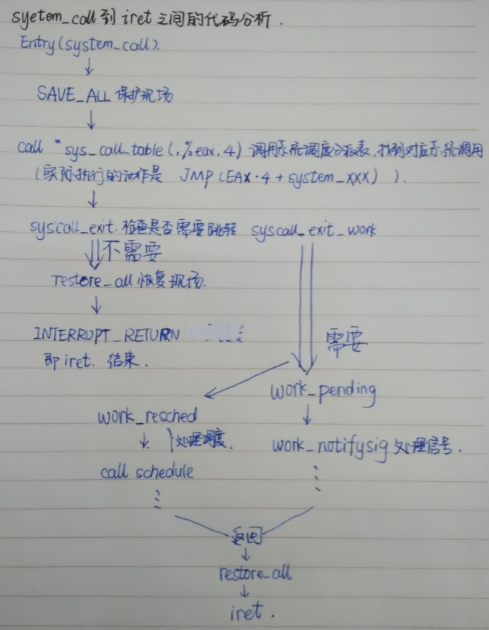
从以上可以看出:
- 在系统调用返回之前,可能发生进程调度,进程调度里就会出现进程上下文的切换
- 进程间通信可能有信号需要处理
基本的知识点简略总结如上。
总而言之,这半个学期以来,我们学习了有关Linux内核的相关知识,尽管有视频和书的双重工具,但是其实我们的学习还是比较浅显的,对于内核的理解还有很多的不足,需要在下半学期的学习和实践中不断补足。
学习《Linux内核分析》课程中最大的收获:
最大的收获是转变了学习方式,通过反转课堂、mooc的方式锻炼了自己的学习能力。并且,之前我对Linux并不是很熟悉,而这个课程过后我有了一个比较基本的全面的认识,这为我之后的学习提供了很多帮助。
学习完《Linux内核分析》课程后您最大的遗憾:
学习的内容还是比较浅显,调试的时候动作也比较简单,只能说是基本完成了学习任务,但却还有很多需要提升的地方,所以我需要在之后的学习过程中更加严格要求自己,继续学习研究Linux相关。
附录:学习笔记链接总结
闫佳歆 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程 http://mooc.study.163.com/course/USTC-1000029000