1. 产品的架构是数据采集到 kafka,由 flink 读取,送入ES
2. 这个过程中,涉及: kafka分区数,flink并行度,ES 分区数和副本
3. kafka 分区数决定了后面 flink 的并行度,最好是 kafka 的分区数和 flink 的并行度一致,flink的并行度最好和ES的分片数相等,这样能并行写入;
4. 写入 ES 时,需要先决定是按天建立索引还是按月建立索引,我一般是跨度超过1年的离线数据按月建立索引,跨度不超过一个月的数据按天建立索引;另外还需要考察一天或者一个月中的数据量,如果数据量超过几十亿,分片数最好设的大一点,设置成10个以上,可以加快查询
5. 写入ES时,可以将副本数暂时设置为 0,以提高写入速度,写入完成后,可以将副本数动态修改为 1或者2;
6. 使用 kibana 对 ES 性能进行监控,Kinban 对ES的监控非常完善,足以满足需求;
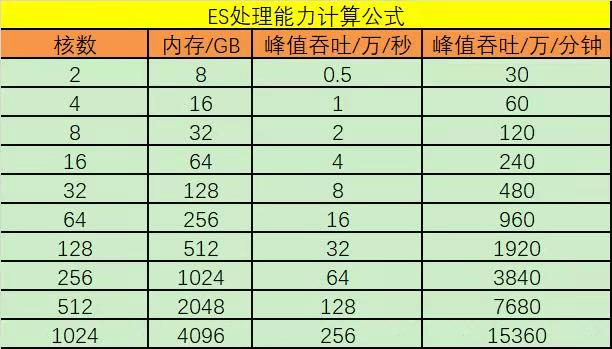
7. 使用 Kibana 监控如果发现 ES 的 index rate 与理论值相差甚远,就要想办法提高速度,主要有两个办法,分别是针对单个任务的提高速度以及建立多个任务提高速度
> 单个任务提高速度可以使用并行写入,主要是 kafka 分区数设置的多一些,flink 任务的并行度与kakfa分区数一致,但是这种方法有时候并不能提高速度,因为写入速度还受到其他因素影响,例如写入数据的复杂度,IO等;
> 如果单个任务不能使 ES 接近理论速度,可以同时跑多个ES写入任务,例如A、B、C三个任务,A任务虽然只有理论值的一半(可能是写入的数据格式比较复杂),但是如果IO没有达到瓶颈,通过通过叠加B、C两个任务来使 ES 接近理论速度;
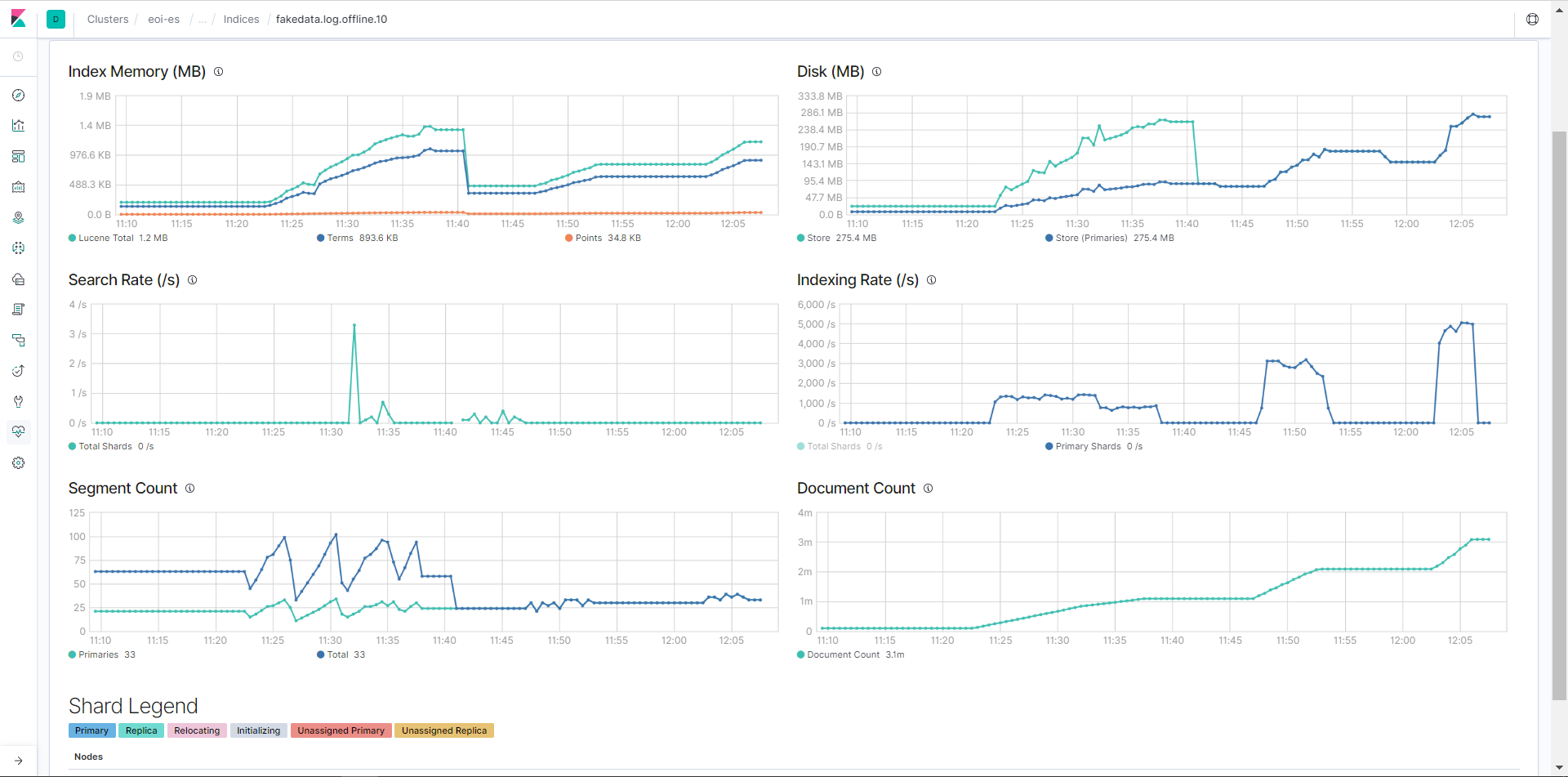
下图是不同参数调价下的ES index 速率和 segment count值
第一个波峰的index rate 在 1200/s 参数为 3 个 shard, 3个 replica, refresh rate = 1s
第二个波峰的 index rate 在 2500/s 参数为 3个 shard, 0 个 replica, refresh rate = 12s
第三个波峰采用 2 个并发写入,index rate 约为 5000/s,参数为 3个 shard, 0个 replica, refresh rate = 12s