前言
前一篇简单的介绍了一下mysql的相关知识,说到mysql就不得不说一下mybatis框架,这一篇主要讲一讲mybatis的应用和面试的问题。总体来说,mybatis更多的可以理解为一个工具,面试中问到的问题相对较少,大家也可以了解一下hibernate,在面试过程中可以给面试官一种知识丰富的感觉。
mybatis的架构
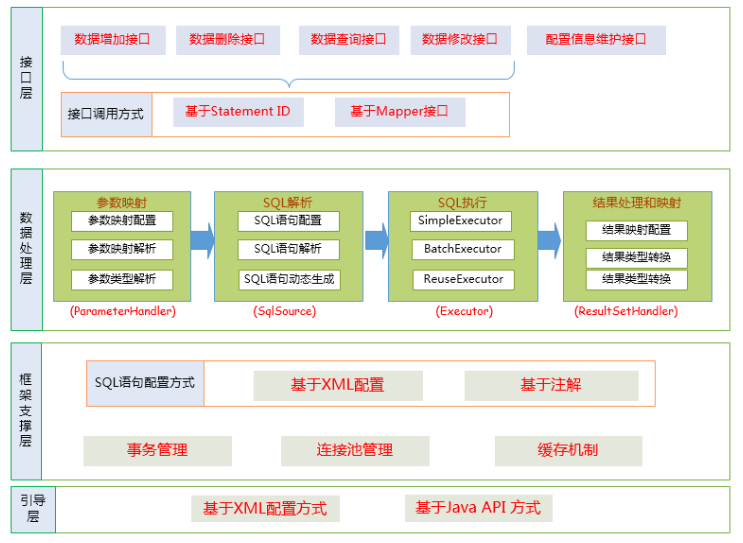
mybatis和数据库交互的方式有两种,一种是传统的根据statementId调用API,另一种是基于Mapper接口实现的,这里我们主要说一说Mapper接口的方式。通过Mapper接口来访问数据库的好处,个人总结有两点,一是符合面向对象编程的依赖接口而不是依赖于实现类,二是通过实现接口可以满足java的动态代理。所以这里也引申出一个问题,mybatis使用的设计模式是什么——代理模式。

通过上图可以知道每个Mapper接口对应着一个Mapper.xml配置文件,其中xml中的每个节点(select、insert、update、delete)的id值对应Mapper接口中的方法名,mybatis会将Mapper.xml中的每个节点转成一个statement对象,放在configuration中,每次在通过接口调用方法时,根据方法名,也就是statement对象的statementId去查找对应的statement对象,进而进行动态生成sql,调用jdbc执行sql等一系列操作,说到这,我们将Mapper接口和Mapper.xml连接到了一起。mybatis也支持注解的方式将方法和sql整合,可以在接口的方法上直接编写sql,如下:
1 @Select("select * from debate") 2 List<Debate> selectDebate(Row row);
这里再说一说关于入参的配置,也就是parameterType和parameterMap,两者的区别很简单,一个参数和多个参数而已,了解即可,parameterMap通常为java.lang.HashMap,通过key-value的形式传参。sql中获取参数的方式有两种#{}和${},对于同一个sql两者的解析结果是不同的,如下:
1 select * from tableName where id = #{id}
当我们传递id=1时,最终的sql是
1 select * from tableName where id = '1'
而当我们使用${id}时,最终的sql是
1 select * from tableName where id = 1
两者的区别就是单引号这个地方,所以说使用#{}可以防止sql注入,而${}不能,关于sql注入这个地方可以稍作了解,举个简单的例子,依然使用上面的sql,假设id的类型是String,当我们将id的值传为"1 or 1 = 1"时,最终的sql为
1 select * from tableName where id = 1 or 1 = 1
因为1 = 1恒成立,所以会将所有的数据都查询出来,对于用户个人信息之类的数据,这样是很不安全的,更可怕的是下面这种情况,当我们将id的值传为"1;delete from tableName",最终的sql为
1 select * from tableName where id = 1;delete from tableName
查询一次数据之后,数据库被清空了,你就哭去吧!
那有人说,既然${}不能防止sql注入,那我们还用它干嘛,存在就一定有价值的,假如我们需要动态传入表名时,就必须使用${},因为#{}会为参数加上单引号
1 select * from 'tableName' where id = 1
很显然,这是一个错误的sql。
再说一说resultMap和resultClass两个属性。通常resultClass指定的是java中定义的model类,将返回结果resultSet映射到实体类上。但是由于命名规则的原因,对于数据库字段,我们通常使用"_"来分割,如用户名:user_name,而对于model实体类,我们通常使用驼峰的方式来命名:userName。当两处的名称不一样时,使用resultClass是没办法自动映射的,这时候就需要使用resultMap来实现。
1 <resultMap type="User" id="UserMapper"> 2 <id property="id" column="id"/> 3 <!-- 只需要修改不一致的字段 --> 4 <result property="sex" column="user_sex"/> 5 </resultMap> 6 7 <!-- 查询学生,根据id --> 8 <select id="getById" parameterType="int" resultType="User"> 9 <![CDATA[ 10 SELECT * from sys_user 11 WHERE id = #{id} 12 ]]> 13 </select>
这里我只写了不一样的列,名字相同的会自动映射,不过个人建议写全,看着更加直观,有利于后期维护。
讲到这顺便提一下关于一对一、一对多和多对多的映射关系,虽然面试的时候没有被问过,算是作为一个知识点的扩展。这里有一篇博客,有兴趣的同学可以看看《mybatis一对一,一对多,多对一,多对多的理解》。到此sql的查询结果resultSet和我们的model也关联到了一起,下面再说一说Mapper接口如何使用的。
我们在使用mybatis时,通常将我们的Mapper接口注入到具体的dao类中,那么spring是如何管理这些Mapper接口的呢?在spring的配置中添加如下配置:
1 <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> 2 <property name="basePackage" value="test.mapper"></property> 3 <property name="sqlSessionFactory" ref="sqlSessionFactory"></property> 4 </bean>
org.mybatis.spring.mapper.MapperScannerConfigurer类会自动扫描test.mapper包下的所有Mapper接口,并使用代理模式为每个Mapper接口生成一个代理类,所以说实际上注入到dao类中的是代理类,这点千万要记住!至此mybatis就可以使用了,下面再说一说mybatis的组成和sql执行的整体流程。

这里只需要了解每一个对象的作用即可,大致的流程就是SqlSession负责调用API,将请求方法名作为statementId从Configuration对象中查找对应的MappedStatement对象,Configuration对象是一个以statementId为key,MappedStatement为value的键值对。MappedStatement对象就是xml配置中的一个个节点(select、insert、update、delete),之后SqlSession将请求委派给了Executors来执行,Executor负责动态sql语句的生成和查询缓存的维护,最终生成一个StatementHandler对象,而StatementHandler对象负责java.sql.Statement参数的入参,调用JDBC查询数据库并将结果java.sql.ResultSet转成list。可能乍一看有点乱,对于这些名词有点生疏,这里有一篇文章推荐给大家《MyBatis原理深入解析》,看完之后再回来看这段话就会感觉清晰了很多。
讲实话,mybatis其实也没有太多可以说的地方,作为一个对JDBC封装的框架来说,内部结构非常简单,使用起来也很顺手,要说弊端就是sql必须程序猿自己手写,不过作为一个合格的开发人员,sql应该是必备技能。还有一点就是关于数据库切换,这种情况我在开发中遇到的不多,由于手写sql的原因,不同数据库对于sql的支持也不一样,可能需要修改sql语句,而hibernate则没有这种问题(如oracle和mysql的分页就是不一样的)。mybatis的总结大概这么多吧,以后想到了再补充!
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
原文链接:http://www.cnblogs.com/1ning/p/6727416.html