1、CAP原理和BASE思想
Consistency(一致性),数据一致更新,所有数据变动都是同步的。
Availability(可用性),好的响应性能。比如上锁的时间小就叫做高可用性。
Partition tolerance(分区容忍性),可靠性。即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
定理:任何分布式系统只可同时满足两点,没法三者兼顾。
CAP权衡
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。
对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。貌似这几年国内银行业发生了不下10起事故,但影响面不大,报到也不多,广大群众知道的少。还有一种是保证CP,舍弃A。例如网络故障事只读不写。
BASE 理论
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
BASE是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)
其中:
基本可用:基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
软状态:软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
最终一致性:指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
BASE模型是传统ACID模型的反面,不同与ACID,BASE强调牺牲高一致性,从而获得可用性,数据允许在一段时间内的不一致,只要保证最终一致就可以了。
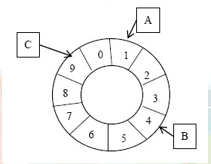
优点:可扩展性极好,能够任意动态添加、删除节点,只影响相邻节点;缺点:元信息:大而且复杂,随机分布节点容易造成不均匀,动态增加节点后只能缓解相邻节点,一个节点异常时压力会全转移到相邻节点。

paxos 协议:多个节点直接通过操作日志同步数据,如果只有一个节点成为主节点,就很容易在多个节点之间维护数据一致性。然后主节点可能出现故障,那么就需要选出主节点。Paxos协议就是用于解决多个节点之间的一致性问题。