1、工具说明
写报告的时候为了细致性,要把IP地址对应的地区给整理出来。500多条IP地址找出对应地区复制粘贴到报告里整了一个上午。
为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本。
使用库
-
1)requests
-
- 简介:Requests是一常用的http请求库,它使用python语言编写,可以方便地发送http请求,以及方便地处理响应结果。
-
- 安装方法:pip install requests
-
2)BeautifulSoup
-
- 简介:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档
-
- 安装方法:pip install beautifulsoup4
2、使用方法
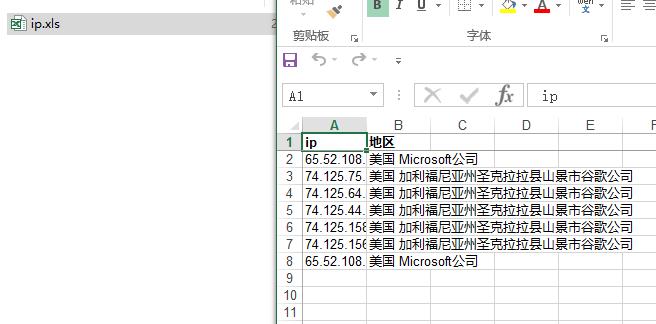
把IP写到.txt文件中就可以了,输出到D:�utCode_ip_domain目录内的IP.xls内。代码注释中已经说明
#-*-coding:utf-8-*-
# 作者:zzzhhh
# 2017-9-19
# 提取站长之家IP批量查询的结果加强版本-写入到XLS中
import sys
import os
import requests
from bs4 import BeautifulSoup
import tablib
path = "D:\0utCode_ip_domain\" # 存放路径
filename = "ip" # 文件名称
dataset1 = tablib.Dataset() # 数据集合
ip_list = [] # IP列表
# 写XLS
def into_els(str,taglocality):
headers = ('ip', '地区') # 首行字段
dataset1.headers = headers
dataset1.append((str,taglocality))
# 域名转换IP
def www_ip(name):
try:
result = socket.getaddrinfo(name,None)
return result[0][4][0]
except:
return 0
#匹配出IP地址函数
def matchIP (str):
url = "http://ip.chinaz.com/"
url = url+str
## 根据传入的IP地址截取出地区
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata, 'lxml')
for tag in soup.find_all('span', class_='Whwtdhalf w50-0'):
tag_extractl = tag.get_text().encode('utf-8')
if tag_extractl.find("IP的物理位置"): #过滤掉【IP的物理位置】这个字符
print str, tag.get_text() #输出IP,地区
into_els(str,tag.get_text()) #写数据到数据集合中
#读取文件函数
def read_file(file_path):
# 判断文件路径是否存在,如果不存在直接退出,否则读取文件内容
if not os.path.exists(file_path):
print 'Please confirm correct filepath !'
sys.exit(0)
else:
with open(file_path, 'r') as source:
for line in source:
ip_list.append(line.rstrip('
').rstrip('
'))
# 遍历IP,通过站长之家查询IP对应地区
for ip in ip_list:
matchIP(ip)
# 写文件到Excel
hFile = open(path + filename + '.xls', "wb")
hFile.write(dataset1.xls)
hFile.close()
if __name__ == '__main__':
file_str=raw_input('Input file IP.txt filepath eg:D:\\test.txt
')
read_file(file_str) #读取文件
3、代码效果