今天所要分享的的是数据类型的那些是可变类型哪些是不可变类型。
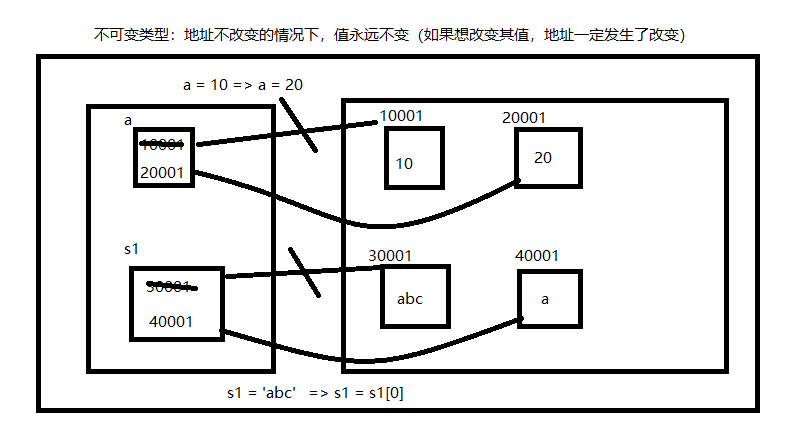
根据图中所画的可以看出,当数字的数值一旦发生改变,id也会跟着发生改变。当id也发生改变的时候,
就可以表示数字类型是属于不可变的。
列表类型和字符串类型属于可变类型及当字符串和列表中的值发生改变,id不会发生改变。
下边开始介绍各数据类型:
数字类型分为:
1. 整型例如:
num = -1000000000000000000000000000000000000000000000000
print(num, type(num))
通过type可以查询得知整型是由python的int功能所创造出来的。
num = 3.14
print(num, type(num))
通过查询type可以得知浮点类型是由float功能创造出来的
res = True
print(res, type(res), isinstance(res, int))
print(3.14 + True)
得出的数值为4.14
通过这个程序可以看出布尔类型就是数字类型,
数字类型很重要的一点就是数字类型之间可以互相转换
例如:
a = 10
b = 3.74
c = True
a b c分别表示整型 浮点型和布尔类型,如果要将其他两种类型转化为整型可以在int()中输入b c然后
输出 :print(int(a), int(b), int(c))
同理可得转化为浮点型并输出:print(float(a), float(b), float(c))
转化为布尔型并输出:print(bool(a), bool(b), bool(c))
s1 = "你是"好学生""
print(s1)
其中的/表示转义的意思
也可以采用单引号嵌套双引号的方式来进行输出:
s2 = '你是"好学生"'
print(s2)
s1 = '123abc呵呵'
print(id(s1))
print(s1[0], id(s1[0]))
t_s = '1'
print(id(t_s))
print(s1[5], s1[-3])
字符串拼接
当两个字符串拼接在一起时会形成一个新的字符串,会保留原来两个字符串。
例如:
s2 = '你好'
s22 = '帅'
ss2 = s2 + s22
print(ss2, id(s2), id(s22), id(ss2))
拼接其他类型的字符串
a = 10
b = "20"
c = True
有两种方法来进行拼接
方法一:使用万能占位符来进行占位
res = "%s%s%s" % (a, b, c)
print(res)
方法二:将其他两种类型转化为字符串形式再进行拼接
res = str(a) + b + str(c)
print(res)
3. 字符串长度
使用len 功能来查询字符串的长度:
s3 = '12345'
ln1 = s3.__len__()
print(ln1)
ln2 = len(s3)
print(ln2)
4. 字符串切片
通过[::]来取出子字符串
s4 = '123abc呵呵'
sub_s = s4[0:6:]#表示从索引值的位取到第五位,步长默认为一位
print(sub_s) # 123abc
sub_s = s4[0:6:2]#表示从索引值的位取到第五位,步长为两位
print(sub_s) # 13b
sub_s = s4[::-1]#步长为负值时表示取反,
print(sub_s) # 呵呵cba321
sub_s = s4[-1:-6:-1]#表示从后往前进行取值,从最后一位取到第五位步长为一。
print(sub_s) # 呵呵cba
5. 成员运算
是用来判断某字符串是否在另一个字符串内中
s5 = '123abc呵呵'
ss5 = '12a'
print(ss5 in s5) # False在另一个字符串中应为连续的字符,不可中断
print(ss5 not in s5) # True当条件不成立取反时,表示成立
6.字符串循环(遍历)
s6 = '123abc呵呵'
for v in s5:
print(v)
# 1.索引(目标字符串的索引位置)
s1 = '123abc呵呵'
print(s1.index('b'))
# 2.去留白(默认去两端留白,也可以去指定字符)
s2 = '***好 * 的 ***'
print(s2.strip('*'))
# 3.计算子字符串个数
s3 = '12312312'
print(s3.count('123'))
# 4.判断字符串是否是数字:只能判断正整数
s4 = '123'
print(s4.isdigit())
# 5.大小写转换
s5 = "AbC def"
print(s5.upper()) # 全大写
print(s5.lower()) # 全小写
# 了了解
print(s5.capitalize()) # 首字母大写
print(s5.title()) # 每个单词首字母大写
# 6.以某某开头或结尾
s6 = 'https://www.baidu.com'
r1 = s6.startswith('https:')
r2 = s6.startswith('http:')
r3 = s6.endswith('com')
r4 = s6.endswith('cn')
if (r1 or r2) and (r3 or r4):
print('合法的链接')
else:
print('非合法的链接')
# 7.替换
s7 = 'egon say: he is da shuai b,egon!egon!egon!'
new_s7 = s7.replace('egon', 'Liu某') # 默认替换所有
print(new_s7)
new_s7 = s7.replace('egon', 'Liu某', 1) # 替换一次
print(new_s7)
# 8.格式化
s8 = 'name:{},age:{}'
print(s8.format('Owen', 18)) # 默认按位置
print('name:{1},age:{1}, height:{1}'.format('Owen', 18)) # 标注位置,一个值可以多次利用
print('name:{n},age:{a}, height:{a}'.format(a=18, n="Zero")) # 指名道姓
1. find | rfind:查找子字符串索引,无结果返回-1
2. lstrip:去左留白
3. rstrip:去右留白
4. center | ljust | rjust | zfill:按位填充
语法:center(所占位数, '填充符号')
5. expandtabs:规定 所占空格数
6. captialize | title | swapcase:首字母大写 | 单词首字母大写 | 大小写反转
7. isdigit | isdecimal | isnumeric:数字判断
8. isalnum | isalpha:是否由字母数字组成 | 由字母组成
9. isidentifier:是否是合法标识符
10. islower | isupper:是否全小 | 大写
11. isspace:是否是空白字符
12. istitle:是否为单词首字母大写格式
# 定义:
# 1.list中可以存放多个值,可以存放所有类型的数据
# 2.list中有序的,可以通过索引取值
# 1.索引取值: 列表名[index]
s1 = [1, 3, 2]
print(s1[0])
print(s1[-1])
# 2.列表运算: 得到的是新list
s2 = [1, 2, 3]
print(s2 + s2)
print(s2 * 2)
print(s2)
# 3.list的长度
s3 = [3, 4, 1, 2, 5]
print(len(s3))
# 4.切片:[start_index:end_index:step]
s4 = [3, 4, 1, 2, 5]
new_s4 = s4[::-1]
print(new_s4)
new_s4 = s4[1:4:]
print(new_s4)
new_s4 = s4[-2:-5:-1]
print(new_s4)
# 5.成员运算:in
s5 = [3, 4, '1', 2, 5]
print('1' in s5)
print(1 in s5)
print(5 not in s5)
# 6.循环
for v in s5:
print(v, type(v))
# 只打印数字类型的数据
for v in s5:
if isinstance(v, int):
print(v, end=' ')
# 1.列表的增删改查
ls = [1, 2, 3]
# 查
print(ls)
print(ls[1])
# 增
ls.append(0) # 末尾增
print(ls)
ls.insert(1, 666) # 任意index前增
print(ls)
ls.insert(len(ls), 888) # insert实行末尾增
print(ls)
# 改
ls[1] = 66666
print(ls)
# 删
ls.remove(888)
print(ls)
res = ls.pop() # 默认从末尾删,并返还删除的值
print(res)
res = ls.pop(1) # 从指定索引删除,并返还删除的值
print(res, ls)
# 了了解
del ls[2]
print(res, ls)
# 清空
ls.clear()
print(ls
# 1)排序: 针对于同类型
ls = ['3', '1', '2']
ls.sort() # 默认正向排序
print(ls)
ls.sort(reverse=True) # 正向排序结果上翻转,形成倒序
print(ls)
# 2)翻转
ls = ['3', '1', '2']
ls.reverse() # 按存储的顺序进行翻转
print(ls)
# 3)计算值的个数 => 列表中可以存放重复数据
ls = [1, 2, 1, 2, 3, 1]
print(ls.count(1)) # 对象1存在的次数
# 1)整体增加,添加到末尾
ls = [1, 2, 3]
ls.extend('123')
print(ls)
ls.extend([0, 1, 2])
print(ls)
# 2) 目标的索引位置,可以规定查找区间
ls = [1, 2, 1, 2, 3, 1]
# 找对象1,在索引3开始往后找到索引6之前
ind = ls.index(1, 3, 6)
print(ind)