Web框架本质及第一个Django实例
Web框架本质
我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端。 这样我们就可以自己实现Web框架了。
半成品自定义web框架
mport socket sk = socket.socket() sk.bind(("127.0.0.1", 80)) sk.listen() while True: conn, addr = sk.accept() data = conn.recv(8096) conn.send(b"OK") conn.close()
可以说Web服务本质上都是在这十几行代码基础上扩展出来的。这段代码就是它们的祖宗。
用户的浏览器一输入网址,会给服务端发送数据,那浏览器会发送什么数据?怎么发?这个谁来定? 你这个网站是这个规定,他那个网站按照他那个规定,这互联网还能玩么?
所以,必须有一个统一的规则,让大家发送消息、接收消息的时候有个格式依据,不能随便写。
这个规则就是HTTP协议,以后浏览器发送请求信息也好,服务器回复响应信息也罢,都要按照这个规则来。
HTTP协议主要规定了客户端和服务器之间的通信格式,那HTTP协议是怎么规定消息格式的呢?
让我们首先打印下我们在服务端接收到的消息是什么。
import socket sk = socket.socket() sk.bind(("127.0.0.1", 80)) sk.listen() while True: conn, addr = sk.accept() data = conn.recv(8096) print(data) # 将浏览器发来的消息打印出来 conn.send(b"OK") conn.close()
输出:
b'GET / HTTP/1.1 Host: 127.0.0.1:8080 Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 DNT: 1 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: csrftoken=RKBXh1d3M97iz03Rpbojx1bR6mhHudhyX5PszUxxG3bOEwh1lxFpGOgWN93ZH3zv '
然后我们再看一下我们访问博客园官网时浏览器收到的响应信息是什么。
响应相关信息可以在浏览器调试窗口的network标签页中看到。
HTTP协议对收发消息的格式要求
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。 HTTP响应的Header中有一个 Content-Type表明响应的内容格式。如 text/html表示HTML网页。
HTTP GET请求的格式:
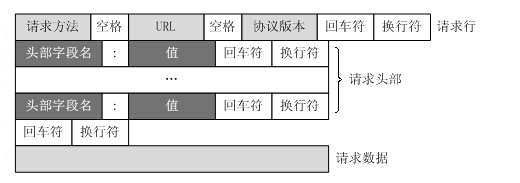
HTTP响应的格式:
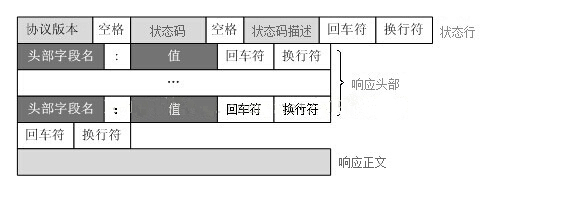
处理版自定义web框架
经过上面的补充学习,我们知道了要想让我们自己写的web server端正经起来,必须要让我们的Web server在给客户端回复消息的时候按照HTTP协议的规则加上响应状态行,这样我们就实现了一个正经的Web框架了
import socket sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind(('127.0.0.1', 8000)) sock.listen() while True: conn, addr = sock.accept() data = conn.recv(8096) # 给回复的消息加上响应状态行 conn.send(b"HTTP/1.1 200 OK ") conn.send(b"OK") conn.close()
我们通过十几行代码简单地演示了web 框架的本质。
接下来就让我们继续完善我们的自定义web框架吧!
根据不同的路径返回不同的内容
可以从请求相关数据里面拿到请求URL的路径,然后拿路径做一个判断。
""" 根据URL中不同的路径返回不同的内容 """ import socket sk = socket.socket() sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口 sk.listen() # 监听 while 1: # 等待连接 conn, add = sk.accept() data = conn.recv(8096) # 接收客户端发来的消息 # 从data中取到路径 data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串 # 按 分割 data1 = data.split(" ")[0] url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径 conn.send(b'HTTP/1.1 200 OK ') # 因为要遵循HTTP协议,所以回复的消息也要加状态行 # 根据不同的路径返回不同内容 if url == "/index/": response = b"index" elif url == "/home/": response = b"home" else: response = b"404 not found!" conn.send(response) conn.close()
根据不同的路径返回不同的内容--函数半
""" 根据URL中不同的路径返回不同的内容--函数版 """ import socket sk = socket.socket() sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口 sk.listen() # 监听 # 将返回不同的内容部分封装成函数 def index(url): s = "这是{}页面!".format(url) return bytes(s, encoding="utf8") def home(url): s = "这是{}页面!".format(url) return bytes(s, encoding="utf8") while 1: # 等待连接 conn, add = sk.accept() data = conn.recv(8096) # 接收客户端发来的消息 # 从data中取到路径 data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串 # 按 分割 data1 = data.split(" ")[0] url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径 conn.send(b'HTTP/1.1 200 OK ') # 因为要遵循HTTP协议,所以回复的消息也要加状态行 # 根据不同的路径返回不同内容,response是具体的响应体 if url == "/index/": response = index(url) elif url == "/home/": response = home(url) else: response = b"404 not found!" conn.send(response) conn.close()
根据不同的路径返回不同的内容--函数进阶版
""" 根据URL中不同的路径返回不同的内容--函数进阶版 """ import socket sk = socket.socket() sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口 sk.listen() # 监听 # 将返回不同的内容部分封装成函数 def index(url): s = "这是{}页面!".format(url) return bytes(s, encoding="utf8") def home(url): s = "这是{}页面!".format(url) return bytes(s, encoding="utf8") # 定义一个url和实际要执行的函数的对应关系 list1 = [ ("/index/", index), ("/home/", home), ] while 1: # 等待连接 conn, add = sk.accept() data = conn.recv(8096) # 接收客户端发来的消息 # 从data中取到路径 data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串 # 按 分割 data1 = data.split(" ")[0] url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径 conn.send(b'HTTP/1.1 200 OK ') # 因为要遵循HTTP协议,所以回复的消息也要加状态行 # 根据不同的路径返回不同内容 func = None # 定义一个保存将要执行的函数名的变量 for i in list1: if i[0] == url: func = i[1] break if func: response = func(url) else: response = b"404 not found!" # 返回具体的响应消息 conn.send(response) conn.close()
返回具体的HTML文件
""" 根据URL中不同的路径返回不同的内容--函数进阶版 返回独立的HTML页面 """ import socket sk = socket.socket() sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口 sk.listen() # 监听 # 将返回不同的内容部分封装成函数 def index(url): # 读取index.html页面的内容 with open("index.html", "r", encoding="utf8") as f: s = f.read() # 返回字节数据 return bytes(s, encoding="utf8") def home(url): with open("home.html", "r", encoding="utf8") as f: s = f.read() return bytes(s, encoding="utf8") # 定义一个url和实际要执行的函数的对应关系 list1 = [ ("/index/", index), ("/home/", home), ] while 1: # 等待连接 conn, add = sk.accept() data = conn.recv(8096) # 接收客户端发来的消息 # 从data中取到路径 data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串 # 按 分割 data1 = data.split(" ")[0] url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径 conn.send(b'HTTP/1.1 200 OK ') # 因为要遵循HTTP协议,所以回复的消息也要加状态行 # 根据不同的路径返回不同内容 func = None # 定义一个保存将要执行的函数名的变量 for i in list1: if i[0] == url: func = i[1] break if func: response = func(url) else: response = b"404 not found!" # 返回具体的响应消息 conn.send(response) conn.close()
让网页动态起来
""" 根据URL中不同的路径返回不同的内容--函数进阶版 返回HTML页面 让网页动态起来 """ import socket import time sk = socket.socket() sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口 sk.listen() # 监听 # 将返回不同的内容部分封装成函数 def index(url): with open("index.html", "r", encoding="utf8") as f: s = f.read() now = str(time.time()) s = s.replace("@@oo@@", now) # 在网页中定义好特殊符号,用动态的数据去替换提前定义好的特殊符号 return bytes(s, encoding="utf8") def home(url): with open("home.html", "r", encoding="utf8") as f: s = f.read() return bytes(s, encoding="utf8") # 定义一个url和实际要执行的函数的对应关系 list1 = [ ("/index/", index), ("/home/", home), ] while 1: # 等待连接 conn, add = sk.accept() data = conn.recv(8096) # 接收客户端发来的消息 # 从data中取到路径 data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串 # 按 分割 data1 = data.split(" ")[0] url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径 conn.send(b'HTTP/1.1 200 OK ') # 因为要遵循HTTP协议,所以回复的消息也要加状态行 # 根据不同的路径返回不同内容 func = None # 定义一个保存将要执行的函数名的变量 for i in list1: if i[0] == url: func = i[1] break if func: response = func(url) else: response = b"404 not found!" # 返回具体的响应消息 conn.send(response) conn.close()
服务器程序和应用程序
对于真实开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。
服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理。
应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。
这样,服务器程序就需要为不同的框架提供不同的支持。这样混乱的局面无论对于服务器还是框架,都是不好的。对服务器来说,需要支持各种不同框架,对框架来说,只有支持它的服务器才能被开发出的应用使用。
这时候,标准化就变得尤为重要。我们可以设立一个标准,只要服务器程序支持这个标准,框架也支持这个标准,那么他们就可以配合使用。一旦标准确定,双方各自实现。这样,服务器可以支持更多支持标准的框架,框架也可以使用更多支持标准的服务器。
WSGI(Web Server Gateway Interface)就是一种规范,它定义了使用Python编写的web应用程序与web服务器程序之间的接口格式,实现web应用程序与web服务器程序间的解耦。
常用的WSGI服务器有uwsgi、Gunicorn。而Python标准库提供的独立WSGI服务器叫wsgiref,Django开发环境用的就是这个模块来做服务器。
wsgiref
我们利用wsgiref模块来替换我们自己写的web框架的socket server部分:
""" 根据URL中不同的路径返回不同的内容--函数进阶版 返回HTML页面 让网页动态起来 wsgiref模块版 """ import time from wsgiref.simple_server import make_server # 将返回不同的内容部分封装成函数 def index(url): with open("index.html", "r", encoding="utf8") as f: s = f.read() now = str(time.time()) s = s.replace("@@oo@@", now) return bytes(s, encoding="utf8") def home(url): with open("home.html", "r", encoding="utf8") as f: s = f.read() return bytes(s, encoding="utf8") # 定义一个url和实际要执行的函数的对应关系 list1 = [ ("/index/", index), ("/home/", home), ] def run_server(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息 url = environ['PATH_INFO'] # 取到用户输入的url func = None for i in list1: if i[0] == url: func = i[1] break if func: response = func(url) else: response = b"404 not found!" return [response, ] if __name__ == '__main__': httpd = make_server('127.0.0.1', 8090, run_server) print("我在8090等你哦...") httpd.serve_forever()
jinja2
上面的代码实现了一个简单的动态,我完全可以从数据库中查询数据,然后去替换我html中的对应内容,然后再发送给浏览器完成渲染。 这个过程就相当于HTML模板渲染数据。 本质上就是HTML内容中利用一些特殊的符号来替换要展示的数据。 我这里用的特殊符号是我定义的,其实模板渲染有个现成的工具: jinja2