1、名词解释:
CUDA:NVIDIA公司提出了一种通用的并行计算平台和编程模型。
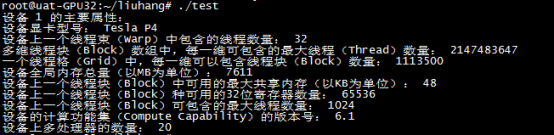
2、GPU性能
3、分治思想:
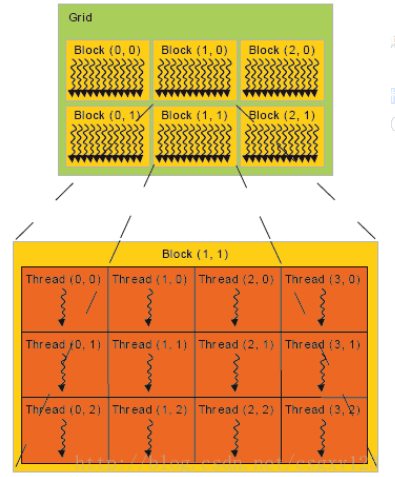
线程格grid :
线程格可以是一维、二维或者三维的,线程格的尺寸一般根据待处理数据的规模或者处理器的数量来指定。
一次 kernel 的 launch (就是一次 <<< >>>)生成一张 grid。
同一个 grid 中采用多个 block,再在一个 block 中分多个 thread,但是在单次kernel 调用中,grid 就是最大的单位了,而且只有一个。
共享 global memory。
4、一维线程格
kerneladd<<<10, 1000>>>(dev_arr); //将线程格分成10个block 每个block1000个线程
指定特殊线程做特殊的事情,在线程网络中,blockId.x和threadId.x就是对应的block编号和thread编号
5、二维线程格
二维数组
用于线程索引计算的CUDA运行时库提供的变量
gridDim.x —— 线程网格X维度上线程块的数量
gridDim.y —— 线程网格Y维度上线程块的数量
blockDim.x —— 一个线程块X维度上的线程数量
blockDim.y —— 一个线程块Y维度上的线程数量
threadIdx.x —— 线程块X维度上的线程索引
threadIdx.y —— 线程块Y维度上的线程索引
二维线程网格模型下计算当前线程索引:
idx = (blockIdx.x * blockDim.x) + threadIdx.x;
idy = (blockIdx.y * blockDim.y) + threadIdx.y;
threadIdx = idx + idy * blockDim.x * gridDim.x;
dim3 dimBlock(16,16);
dim3 dimGrid(8,8);
myhistKernel<<<dimGrid,dimBlock>>>();
6、三维线程格
以此类推 多个Z轴
7、GPU内存
数组拷贝到CPU是全局内存
支持图像高速传输采用纹理内存
详见demo picture.cu
函数:
cudaThreadSynchronize()
主机是单个线程的应用,一般不用加sync。要理解cudaThreadSynchronize的意义(不是sync_threads!!),它是阻塞cpu直到gpu kernel执行完毕。
__syncthreads()
block内部用于线程同步
就是同一block内所有线程执行至__syncthreads()处等待全部线程执行完毕后再继续