数据插入(添加数据)
有3种形式
形式1:
insert into 表名(字段名1,字段名2,....)values (值a1,值a2, .....), (值b1,值b2, .....),...;
形式2:
insert into 表名1(字段名1,字段名2,....)select 字段名1,字段名2,.... from 表名2;
形式3:
insert into 表名 set 字段名1=值1,字段名2=值2, ..... ;
形式1和形式2,可以一次插入多条数据;
2,不管哪种形式,在“字段”和“值”之间,都有“一一对应”关系。
其他类似插入数据的语句:
载入外部“形式整齐”的数据:
load data infile ‘文件完整名(含路径)’ into table 表名;
复制一个表的结构和数据:
create table 表名1 select * from 表名2;
删除数据
delete from 表名 [where条件] [order排序] [limit限定];
类似删除语句truncate:
truncate [table] 表名;用于直接删除整个表(结构)并重新创建该表。
修改数据
基本语法:
update 表名 set 字段名1=值表达式1,字段名2=值表达式2,....[where条件] [order排序] [limit限定];
复制表
复制表方法1:
create table tab2 like tab1; //复制结构了
insert into tab2 select * from tab1; //复制数据
这种方法可以比较完整。
复制表方法2:
create table tab2 select * from tab1; //同时复制结构和数据
这种方法可能会丢一些结构信息,比如:索引,约束,自增长属性
数据查询语言DQL
基本查询
语法形式
select [all | distinct] 字段或表达式列表 [from子句] [where子句] [group by子句] [having子句] [order by子句] [limit子句];
解释说明:
select语句,作用是从“数据源”中,找出(取出)一定的数据,并作为该语句的返回结果(数据集)
数据源:
通常,数据源就是“表”。但:
也可以没有数据源,而是使用“直接数据”(或函数执行结果)。
可以给其加上字段(别)名:
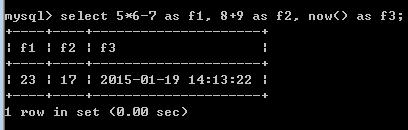
而如果有表(from子句),则对字段同样可以进行“计算”:

还可以对表中的字段和“直接值”(或函数返回值)同时并列“取出”
[all | distinct]
用于设定所select出来的数据是否允许出现重复行(完全相同的数据行)
all:允许出现——默认不写就是All(允许的)。
distinct:不允许出现——就是所谓的“消除重复行”。 写在字段后面
where子句
一个概念:where子句,相当于php或js中的if条件语句:其最终结果就是布尔值(true/false)
php:if($n % 4 == 0 && $n % 100 != 0 || $n % 400 == 0 ){}
则:
where true, where 1; where 1=1; 都表示true
where false, where 0; where 1<>1; 都表示false
where中可用的运算符:
算术运算符: + - * / %
比较运算符: > >= < <= =(等于) <>(不等于)
==(等于,mysql扩展),!=(不等于,mysql扩展)
逻辑运算符: and(与) or(或) not(非)
布尔值的判断方式:
布尔值:本质上,布尔值只是一位整数的“别名”,0表示false,非0表示true。
判断为true: XX is true
判断为fale: XX is false
XX应该是一个字段名,且其类型应该是一个整数。
实际应用中,布尔值判断很少用,因为可以直接使用数学大小。
空值的判断方式:
判断为null: XX is null
判断为非空: XX is not null
XX应该是一个字段名
between语法:
XX between 值1 and 值2;
含义:字段XX的值在值1和值2之间(含),相当于:XX >=值1 and XX<=值2;
in语法:
XX in (值1,值2,.......);
含义: XX等于其中所列出的任何一个值都算成立,相当于:
XX = 值1 or XX = 值2 or XX = 值2
注意:其中的值1通常是“直接值”
like语法(模糊查找):
语法形式: XX like ‘要查找字符’;
说明:
1,like语法(模糊查找)用于对字符类型的字段进行字符匹配查找
2,要查找的字符中,有2个特殊含义的字符:
2.1: % 其含义是:代表任意个数的任意字符
2.2: _ 其含义是:代表1个的任意字符
2.3:这里的字符,都是指现实中可见的一个“符号”,而不是字节。
3,实际应用中的模糊查找,通常都是这样:like ‘%关键字%’;
如果要查找的字符中包含“%”或“_”,“’”,则只要对他们进行转义就可以:
like ‘%ab\%cd%’ //这里要找的是: 包含 ab%cd 字符的字符
like ‘\_ab%’ //这里要找的是: _ab开头的字符
like ‘%ab’cd%’ //这里要找的是: 包含 ab’cd 字符的字符
where子句前面必须有from子句。虽然他们2者都可以省略,但有from可以没有where,而有where必须有from。
group by 分组子句
形式:
group by 字段1 排序方式1,字段2 排序方式2, .....
通常都只进行一个字段的分组。
含义:
什么叫分组?就是将数据以某个字段的值为“依据”,分到不同的“组别”里。
分组的结果通常:
1,数据结果只能是“组”——没有数据本身的个体
2,数据结果就可能“丢失”很多特性,比如没有性别,身高,姓名,等等。
3,实际上,结果中通常只剩下“组”作为整体的信息:
首先是该组的本身依据值,
另外,这几个可能的值:组内成员的个数,组内某些字段的最大值,最小值,平均值,总和值。
其他字段,通常就不能用了。
4,如果是2个字段或以上分组,则其实是相当于对前一分组的组内,再进行后一依据的分组。
上述说明的结果,其实是反映在select语句中,就是select的“取出项”(输出项)就基本只剩下以上信息了。
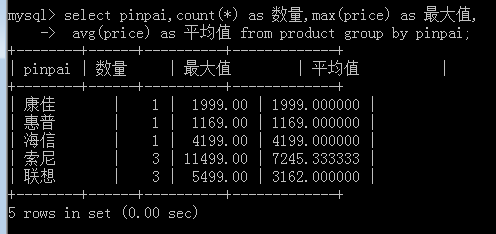
可见,在分组查询中,基本都依赖于一下几个函数(聚合函数,统计函数):
count(*): 统计一组中的数量,通常用“*”做参数
max(字段名):获取该字段中在该组中的最大值。
min(字段名):获取该字段中在该组中的最小值。
sum(字段名):获取该字段中在该组中的总和。
avg(字段名):获取该字段中在该组中的平均值。
Group_concat(字段名): 分组之后把未显示的显示出来
Concat:连接
ASC:正序(默认值)可以省略
DESC: 倒序
再使用逻辑运算符:

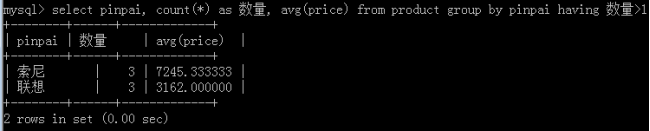
having子句
having子句其实概念跟where子句完全一样:
where是针对表的字段的值进行“条件判断”
having是只针对groupby之后的“组”数据进行条件判断,即
其不能使用:字段名>10
但可以使用:count(字段名)>10, 或 max(price) > 2000, 但如果字段是分组依据,也可以。
当然,通常也可以使用select中的有效的字段别名,比如:
select count(*) as f1 , max(f1) as f2 from tab1 group by f3 having f1 > 5 and f2 < 1000;
再使用逻辑运算符:
