上一节简单的总结了单表查询和多表查询,以下给大家总结了查询语句的结构,如下:
SELECT...FROM...WHERE...GROUP BY...HAVING...ORDER BY...LIMIT...
本节主要总结下常用的条件字段的匹配问题,最常见的是“=”,如select * from student where id=1501001等,除此之外平时也会遇到一些不是"=的情况。
1.掌握in的用法
使用场景:做条件查询的时候,条件字段的取值有多个情况,in(范围),not in(范围)
实例:查询学号id为1501001或1501002或1502001的学生信息。
分析过程:
1.查询涉及到的表:student
2.查询字段信息:没有特定的即用*表示
3.关联条件:只有一个表,不用关联
4.过滤条件:id in(1501001,1501002,1502001)
所以最终得到的sql如下:
SELECT
*
FROM
student
WHERE
id IN(1501001,1501002,1502001)
拓展:除了in,对应的有not in的用法,指条件字段不在某个数据内的情况。
2.掌握模糊查询like的用法
2.1使用%来模糊匹配
使用场景:条件字段不完整时,且没有字符长度限制时,可以用%做模糊匹配。
实例:查询所有姓“胡”的学生信息。
分析过程:
1.查询涉及到的表:student
2.查询字段信息:没有特定的即用*表示
3.关联条件:只有一个表,不用关联
4.过滤条件:name like '胡%'
所以最终得到的sql如下:
SELECT
*
FROM
student
WHERE
name LIKE '胡%'
拓展:以胡开头是 '胡%',以胡结尾是 '%胡',包含胡是 '%胡%'
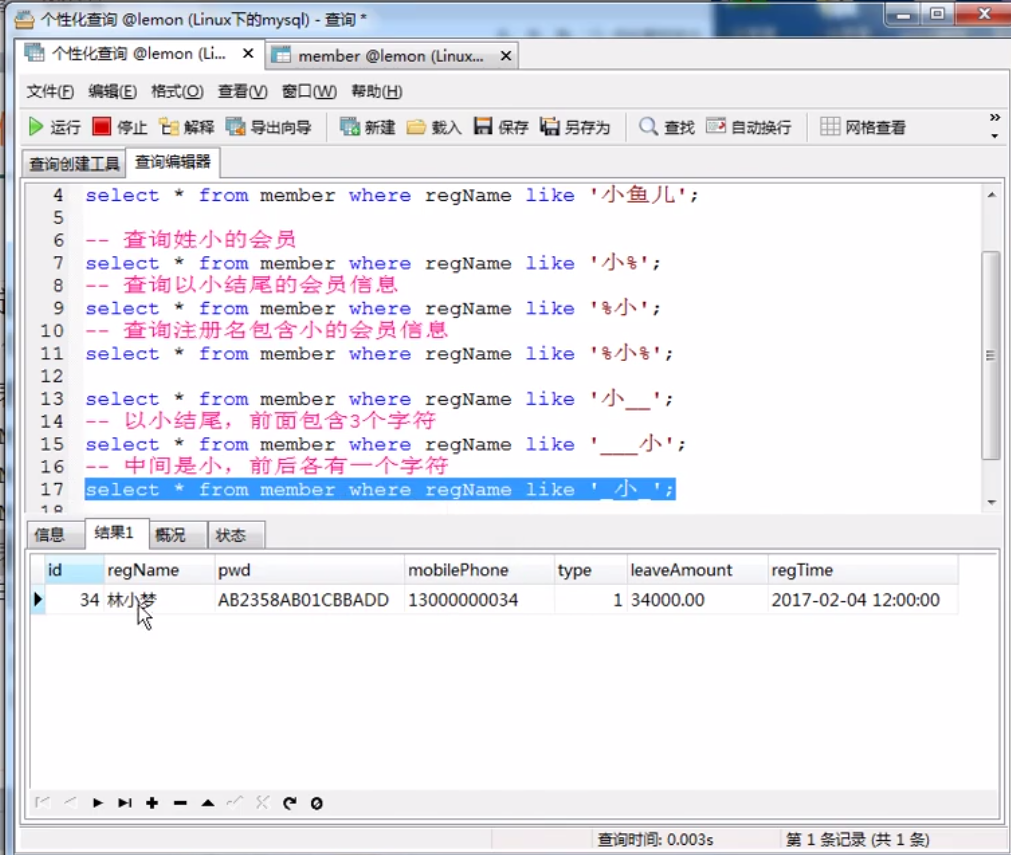
2.3使用_来模糊匹配
_和%区别是,_起到的是一个占位符的作用,一个_只能匹配一个任意的字符,而%可以匹配任意长度的字符。
使用场景:条件字段不完整时,且有字符长度限制时,可以用_做模糊匹配。
实例:查询所有姓“胡”且名字为两个字的学生信息。
分析过程:
1.查询涉及到的表:student
2.查询字段信息:没有特定的即用*表示
3.关联条件:只有一个表,不用关联
4.过滤条件:name like '胡_'
所以最终得到的sql如下:
SELECT
*
FROM
student
WHERE
name LIKE '胡_'
实例:
3.between和not between
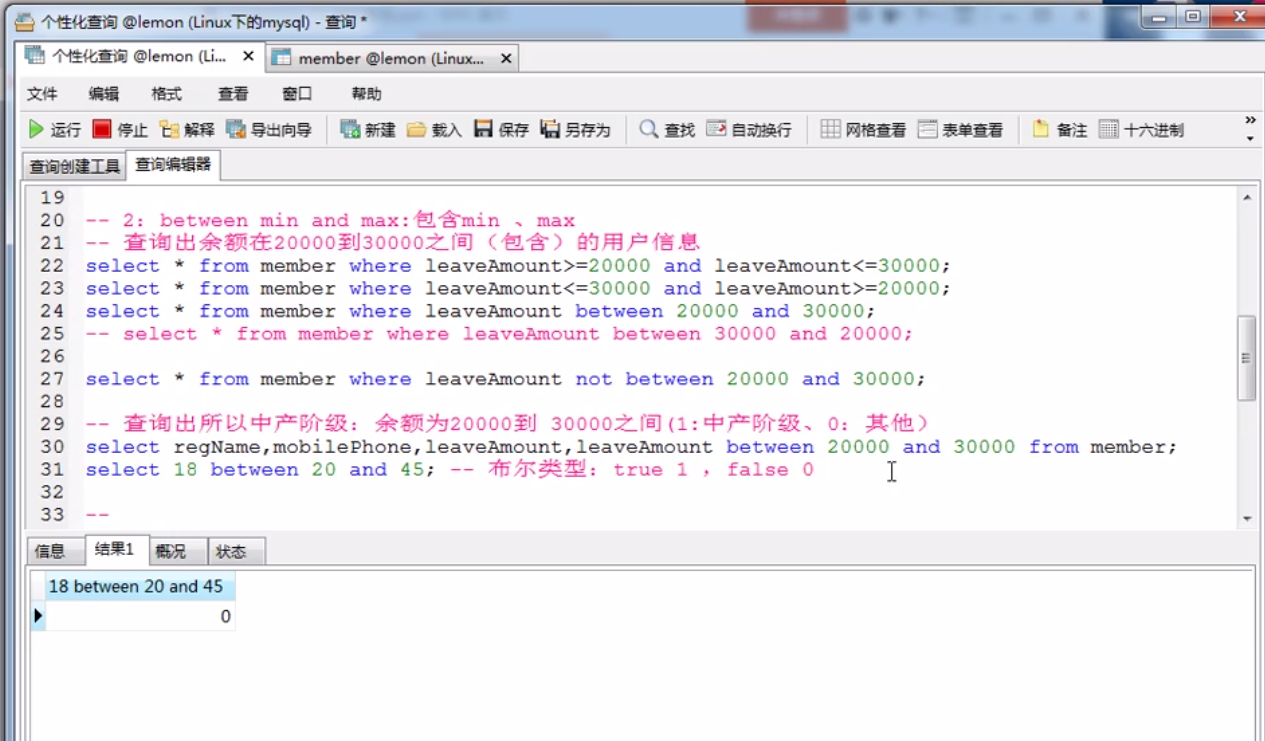
between使用场景:条件字段的值处于(或不处于)两个值之间
语法:SELECT 字段 FROM 表名 WHERE column BETWEEN value1(mix) AND value2(max)
SELECT 字段 FROM 表名 WHERE column NOT BETWEEN value1 AND value2
实例:根据学生的成绩表,查出所有成绩在85-90分的学号,学号不能重复
分析过程:
1.查询涉及到的表:score
2.查询字段信息:distinct id
3.关联条件:只有一个表,不用关联
4.过滤条件:score between 85 and 90
所以最终得到的sql如下:
SELECT
DISTINCT id
FROM
score
WHERE
score BETWEEN 85 AND 90
实例:
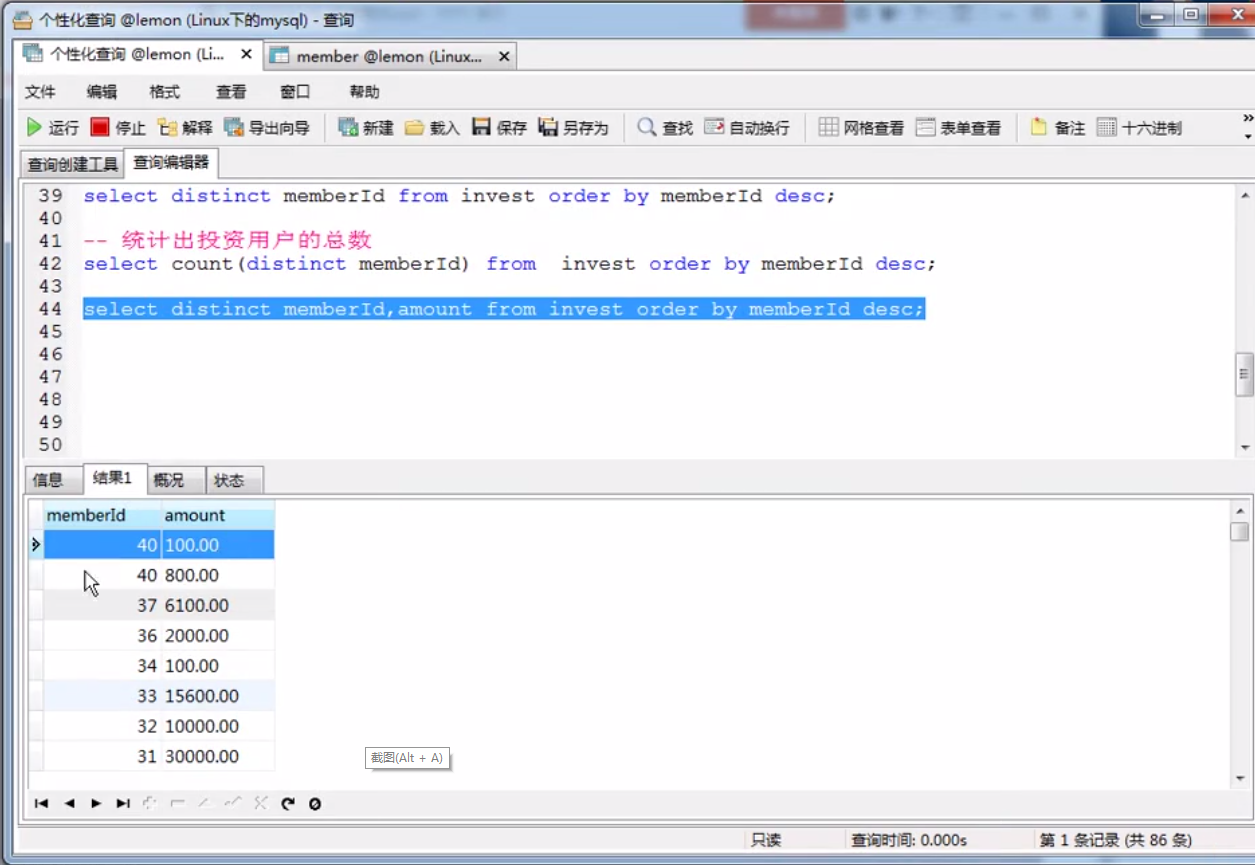
4、DISTINCT去重
distinct使用场景:去除查询结果中的重复数据
去除查询结果中重复数据
SELECT DISTINCT 字段1,字段2... FROM 表名;
实例:
5、GROUP BY分组字句
1、根据一列或多列对结果集进行分组
语法:GROUP BY 字段1,字段2
字段1、字段2相同的为一组,在分组的列上可以使用聚合函数COUNT、SUM、AVG、MAX、MIN
语法:SELECT AVG(字段) FROM S GROUP BY 字段;
实例:
SELECT MemberID 用户id,
min(Amount) 最小投资额,
max(Amount) 最大投资额,
count(1) 投资次数,
avg(Amount) 平均投资额
FROM loan
GROUP BY MemberID;
6、HAVING 分组条件
一般和GROUP BY 联合使用,筛选分组后的数据
与WHERE的区别:where字句在聚合前先筛选记录,作用在GROUP BY和having字句前,而having字句在聚合后对组记录进行筛选
如:SELECT sid,COUNT(1) FROM SC GROUP BY sid HAVING COUNT(1)>2;
实例:

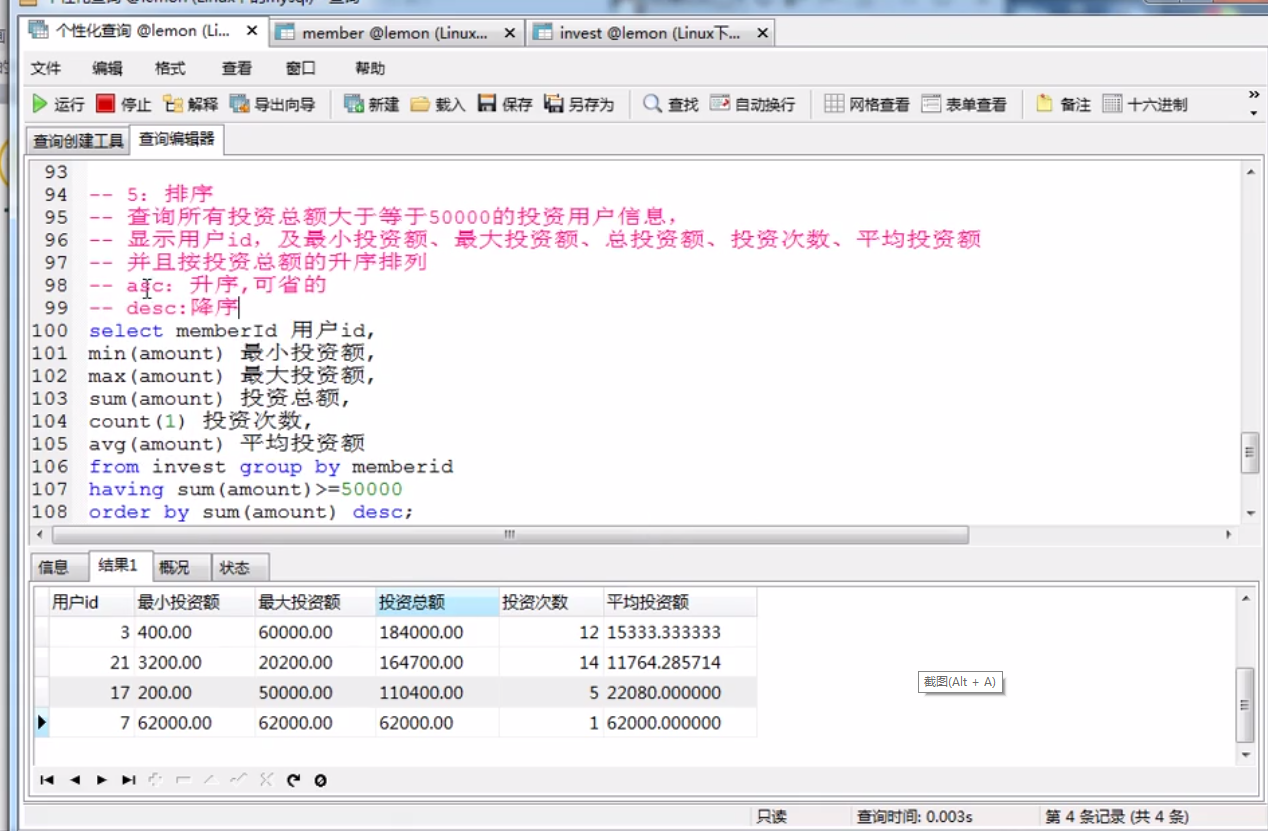
7、ORDER BY排序字句
ORDER BY对结果集排序
ORDER BY field [ASC | DESC]..
ASC表示升序,DESC表示降序
可以使用任意字段作为排序条件
可以指定多个字段进行排序
SELECT * FROM 表名 ORDER BY 字段 ASC;
SELECT * FROM 表名 ORDER BY 字段1(可以为聚合函数) ASC(可省略),字段2(可以为聚合函数) DESC(不可省略);
--先以字段1升序,字段1相同,再以字段2降序
实例:
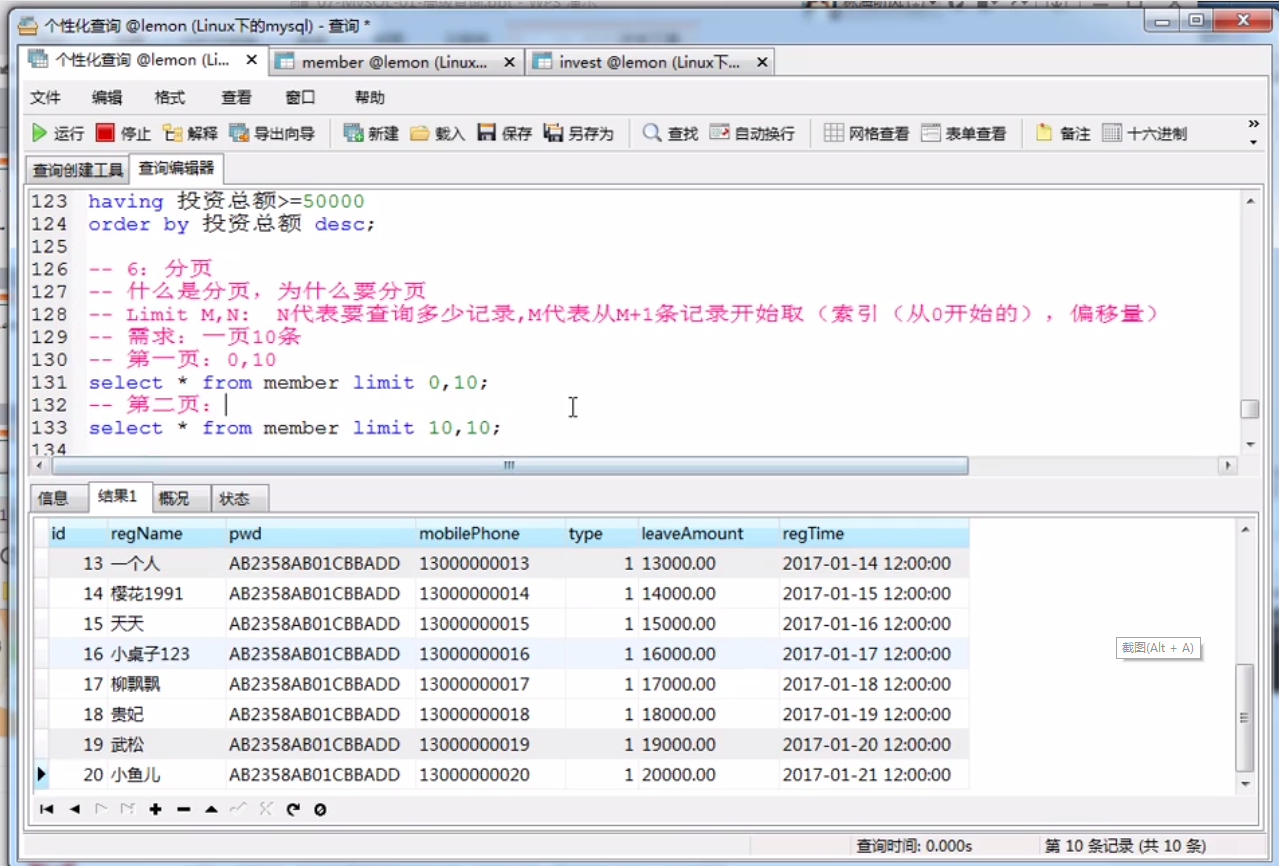
8、LIMIT限制结果集字句
1、分页---LIMIT
LIMIT M,N(M代表从M+1条记录开始取,N代表要查询多少记录)分页---索引从0开始的,偏移量
SELECT * FROM 表名 0,10; -- 表示从第一条数据开始,取前10条数据
SELECT * FROM 表名 10,10; -- 表示从第十一条数据开始,取前10条数据
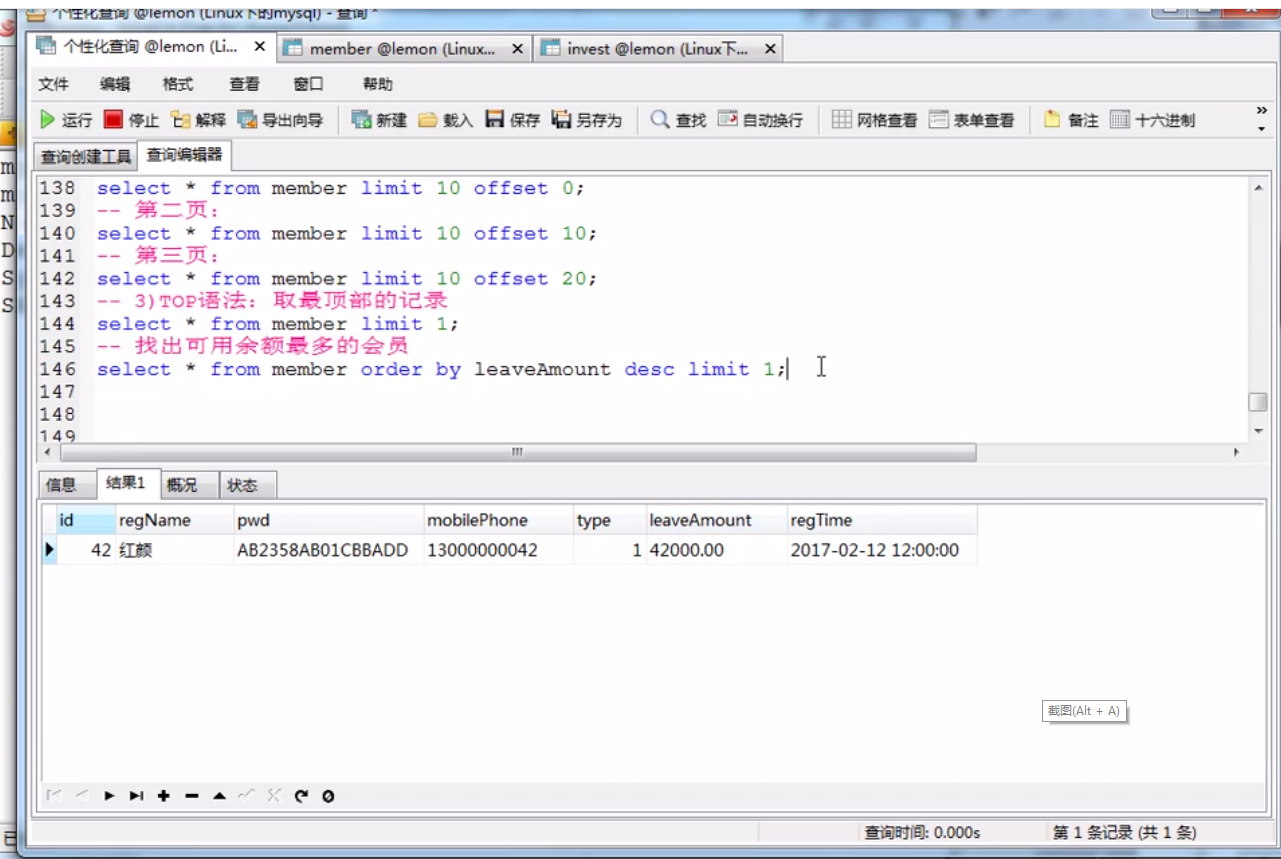
2、OFFSET偏移量
SELECT * FROM 表名 LIMIT 10 OFFSET 0;
SELECT * FROM 表名 LIMIT 10 OFFSET 10;
3、TOP语法
SELECT * FROM 表名 LIMIT 5;
SELECT * FROM 表名 ORDER BY id DESC LIMIT 1;
实例: