原网址:https://news.qq.com/zt2020/page/feiyan.htm?from=timeline&isappinstalled=0
import time import json import csv import requests ExcelName = 'C:/Epidemic-data.csv' #当前日期时间戳 number = format(time.time() * 100, '.0f') url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=&_=%s' % number datas = json.loads(requests.get(url=url).json()['data']) print('更新时间:' + datas['lastUpdateTime']) #写入表头 with open(ExcelName, 'w', encoding='utf-8', newline='') as csvfile: writer = csv.writer(csvfile) writer.writerow(["省份","城市","确诊","死亡","治愈","时间"]) for contry in datas['areaTree']: if contry['name'] == '中国': for province in contry['children']: for city in province['children']: with open(ExcelName, 'a', encoding='utf-8', newline='') as csvfile: writer = csv.writer(csvfile) writer.writerow([province['name'],city['name'], str(city['total']['confirm']),str(city['total']['dead']), str(city['total']['
heal']),datas['lastUpdateTime']])
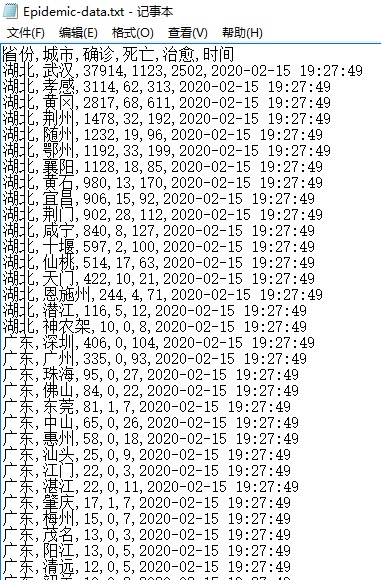
爬取结果: