===关系映射===
参考文档复习:1对1,1对多,多对多
1.映射(多)对一、(一)对一的关联关系
1).使用列的别名
①.若不关联数据表,则可以得到关联对象的id属性
②.若还希望得到关联对象的其它属性。则必须关联其它的数据表
1.创建表:
员工表:
DROP TABLE IF EXISTS `tbl_employee`;
CREATE TABLE `tbl_employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_name` varchar(255) DEFAULT NULL,
`gender` char(1) DEFAULT NULL,
`email` varchar(255) DEFAULT NULL,
`d_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_emp_dept` (`d_id`),
CONSTRAINT `fk_emp_dept` FOREIGN KEY (`d_id`) REFERENCES `tbl_dept` (`id`))
ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
部门表:
CREATE TABLE tbl_dept(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(255) )

2.创建相应的实体类和Mapper接口!


3.写关联的SQL语句
SELECT e.`id` id , e.`user_name` user_name, e.`gender` gender,e.`d_id` d_id,d.`id` did,d.`dept_name` dept_name
FROM `tbl_employee` e, tbl_dept d
WHERE e.`d_id` = d.`id` AND e.id = 1

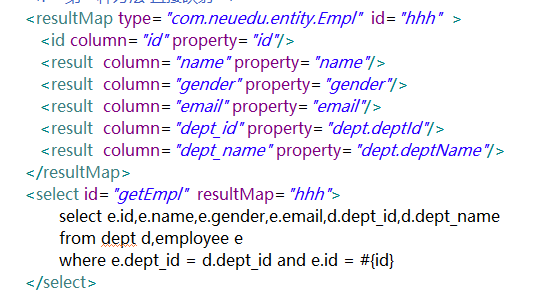
4.在sql映射文件中写映射sql语句【联合查询:级联属性封装结果集】
<!-- 联合查询:级联属性封装结果集 -->
<resultMap type="com.neuedu.entity.Employee" id="getEmployeeAndDeptMap">
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<result column="did" property="depart.id"/>
<result column="dept_name" property="depart.deptName"/>
</resultMap>
<!-- public Employee getEmployeeAndDept(Integer id); -->
<select id="getEmployeeAndDept" resultMap="getEmployeeAndDeptMap">
SELECT e.`id` id , e.`user_name` user_name, e.`gender` gender,e.`email` email,e.`d_id` d_id,d.`id` did,d.`dept_name` dept_name
FROM `tbl_employee` e, tbl_dept d
WHERE e.`d_id` = d.`id` AND e.id = #{id}
</select>
注意:即使使用resultMap来映射,对于“对一”关联关系可以不使用association
5.编写测试用例

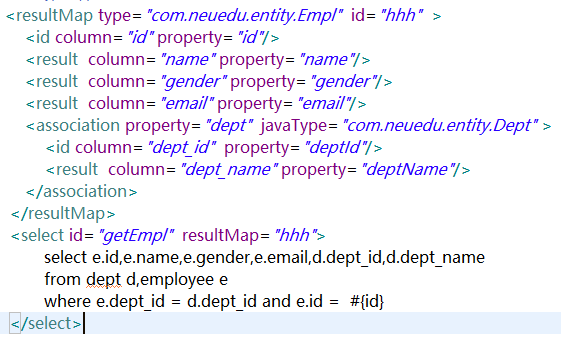
方法二:【使用association来定义关联对象的规则,[比较正规的,推荐的方式]】
<!-- 联合查询:使用association封装结果集 -->
<resultMap type="com.neuedu.entity.Employee" id="getEmployeeAndDeptMap">
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<!-- association可以指定联合的javaBean对象 property="depart":指定哪个属性是联合的对象 javaType:指定这个属性对象的类型【不能省略】 -->
<association property="depart" javaType="com.neuedu.entity.Department">
<id column="did" property="id"/>
<result column="dept_name" property="deptName"/>
</association>
</resultMap>
<!-- public Employee getEmployeeAndDept(Integer id); -->
<select id="getEmployeeAndDept" resultMap="getEmployeeAndDeptMap">
SELECT e.`id` id , e.`user_name` user_name, e.`gender` gender,e.`email` email,e.`d_id` d_id,d.`id` did,d.`dept_name` dept_name
FROM `tbl_employee` e, tbl_dept d
WHERE e.`d_id` = d.`id` AND e.id = #{id}
</select>
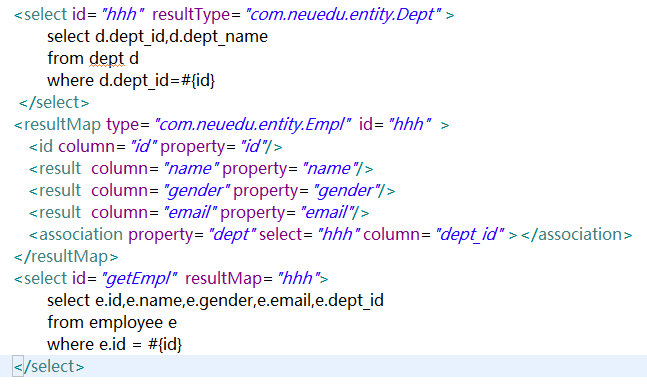
方法三[上述结果相当于使用嵌套结果集的形式]【我们这里还可以使用Association进行分步查询】:
<!-- 使用association进行分步查询 1.先按照员工id查询员工信息 2.根据查询员工信息中d_id值取部门表查出部门信息 3.部门设置到员工中: -->
<select id="getDepartById" resultType="com.neuedu.entity.Department">
SELECT id ,dept_name deptName FROM tbl_dept WHERE id = #{id}
</select>
<resultMap type="com.neuedu.entity.Employee" id="myEmpByStep">
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<!-- association定义关联对象的封装规则 select:表明当前属性是调用指定的方法查出的结果 column:指定将哪一列的值传给这个方法 流程:使用select指定的方法(传入column指定的这列参数的值)查出对象,并封装给property指定的属性。 -->
<association property="depart" select="getDepartById" column="d_id"></association>
</resultMap>
<!-- public Employee getEmpAndDept(Integer id); -->
<select id="getEmpAndDept" resultMap="myEmpByStep">
select * from tbl_employee where id =#{id}
</select>
补充:懒加载机制【按需加载,也叫懒加载】:
<!-- 在分步查询这里,我们还要讲到延迟加载: Employee === > Dept: 我们每次查询Employee对象的时候,都将关联的对象查询出来了。
而我们想能不能我在需要部门信息的时候,再去查询,不需要的时候就不用查询了。
答案:可以的 我们只需要在分步查询的基础之上加上两个配置:
1.在mybatis的全局配置文件中加入两个属性:
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- 开启懒加载机制 ,默认值为true-->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 开启的话,每个属性都会直接全部加载出来;禁用的话,只会按需加载出来 -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
测试:
@Test
public void testGetEmployee(){
EmployeeMapperPlus mapper = openSession.getMapper(EmployeeMapperPlus.class);
Employee employee = mapper.getEmpAndDept(1);
System.out.println(employee.getUserName());
}
此时:可以看到这里只发送了一条SQL语句。
注意:上面我们上面如果关联的是一个对象,我们还可以使用association标签,如果我们关联的是一个集合, 那么该使用谁呢?
===映射对多的关联关系===
场景二:查询部门的时候,将部门对应的所有员工信息也查询出来,注释在DepartmentMapper.xml中
第一种:
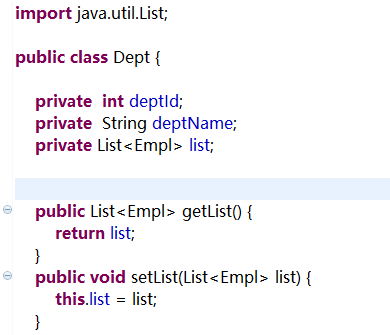
1.修改Department实体类【添加Employee集合,并为该集合提供getter/setter方法】
public class Department {
private Integer id;
private String deptName;
private List<Employee> list;
public List<Employee> getList() {
return list;
}
public void setList(List<Employee> list) {
this.list = list;
} ......
}
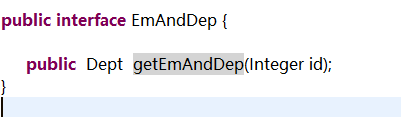
建立DepartmentMapper接口文件,并添加如下方法:
public Department getDeptByIdPlus(Integer id);
2.sql映射文件中的内容为:【collection:嵌套结果集的方式:使用collection标签定义关联的集合类型元素的封装规则】
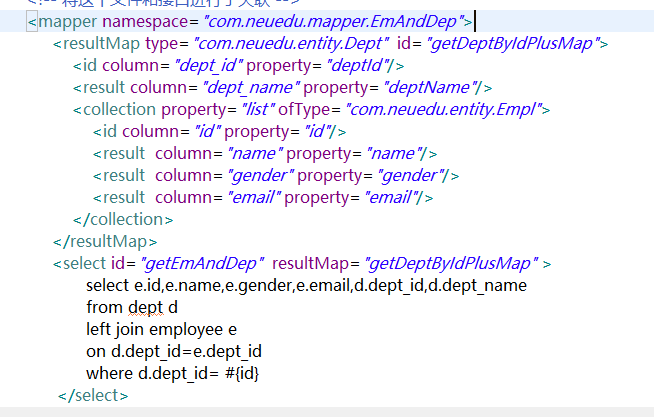
<!-- public Department getDeptByIdPlus(Integer id); -->
<resultMap type="com.neuedu.entity.Department" id="getDeptByIdPlusMap">
<id column="did" property="id"/>
<result column="dept_name" property="deptName"/>
<!-- collection:定义关联集合类型的属性的封装规则 ofType:指定集合里面元素的类型 -->
<collection property="list" ofType="com.neuedu.entity.Employee">
<!-- 定义这个集合中元素的封装规则 -->
<id column="eid" property="id"/>
<result column="user_name" property="userName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
</collection>
</resultMap>
<select id="getDeptByIdPlus" resultMap="getDeptByIdPlusMap">
SELECT d.`id` did, d.`dept_name` dept_name,e.`id` eid,e.`user_name` user_name,e.`email` email,e.`gender` gender
FROM `tbl_dept` d
LEFT JOIN tbl_employee e
ON e.`d_id` = d.`id`
WHERE d.`id` = #{id}
</select>
3.测试方法为:
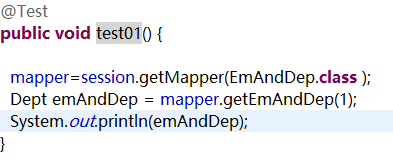
@Test
public void testGetEmployee(){
DepartmentMapper mapper = openSession.getMapper(DepartmentMapper.class);
Department department = mapper.getDeptByIdPlus(2);
System.out.println(department);
}
第二种:使用分步查询结果集的方式:
1.如果使用分步查询的话,我们的sql语句就应该为:
SELECT * FROM `tbl_dept` WHERE id = 2;
SELECT * FROM `tbl_employee` WHERE d_id = 2;
2.在DepartmentMapper接口文件中添加方法,如下所示:
public Department getDeptWithStep(Integer id);
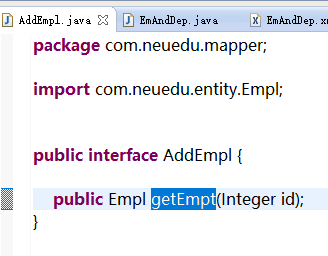
3.再从EmployeeMapper接口中添加一个方法,如下所示:
public List<Employee> getEmployeeByDeptId(Integer deptId);
并在响应的sql映射文件中添加相应的sql语句
<select id="getEmployeeByDeptId" resultType="com.neuedu.entity.Employee">
select * from tbl_employee where d_id = #{departId}
</select>
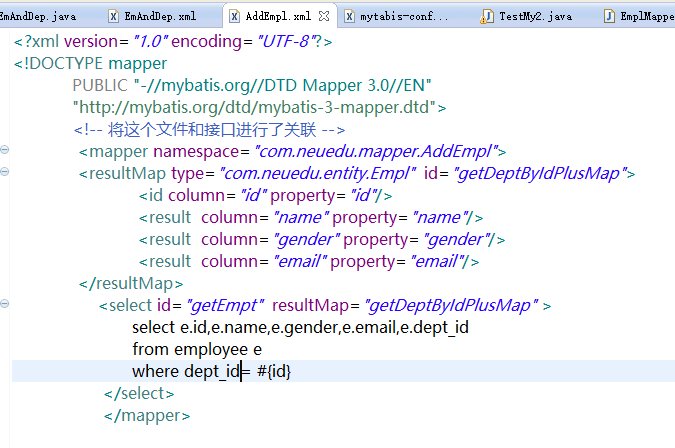
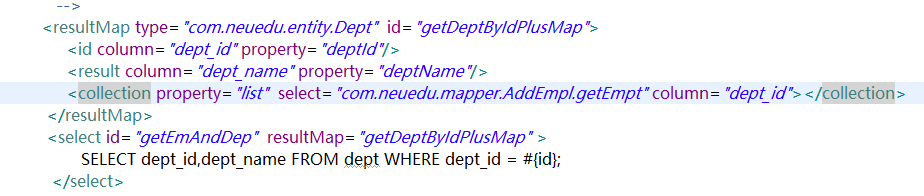
4.在DepartmentMapper映射文件中:
<resultMap type="com.neuedu.entity.Department" id="getDeptWithStepMap">
<id column="id" property="id"/>
<result column="dept_name" property="deptName"/>
<collection property="list" select="com.neuedu.mapper.EmployeeMapper.getEmployeeByDeptId" column="id">
</collection>
</resultMap>
<select id="getDeptWithStep" resultMap="getDeptWithStepMap">
SELECT id ,dept_name FROM tbl_dept WHERE id = #{id}
</select>
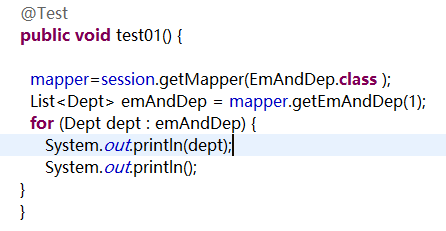
5.测试类:
@Test
public void testGetEmployee(){
DepartmentMapper mapper = openSession.getMapper(DepartmentMapper.class);
Department department = mapper.getDeptWithStep(2);
System.out.println(department);
}
总结:
1.映射(一)对多、(多)对多的关联关系=======》【映射"对多"的关联关系】
2.必须使用collection节点进行映射
3.注意ofType指定集合中的元素类型
4.<!-- collection标签 映射多的一端的关联关系,使用ofType指定集合中的元素类型 columnprefix:指定列的前缀 使用情境:若关联的数据表和之前的数据表有相同的列名,此时就需要给关联的列其"别名". 若有多个列需要起别名,可以为所有关联的数据表的列都加上相同的前缀,然后再映射时指定前缀。 -->