1.作业头
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/CST2020-3 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/CST2020-3/homework/11768 |
| 我在这个课程的目标是 | 回顾数据类型和表达式 文件 |
| 学号 | 20209031 |
| ps: 优化写在最末尾 |
二、本周作业(总分:50分)
2.1 题目:给定一个十进制正整数N,写下从1开始,到N的所有整数,然后数一下其中出现的所有“1”的个数。
例如:
N=2,写下1,2。这样只出现了1个”1“。
N=12,我们会写下1,2,3,4,5,6,7,8,9,10,11,12。这样,1的个数是5。
问题是:
1.写出一个函数f(N),返回1到N之间出现的”1“的个数,比如f(12)=5;
2.满足条件”f(N)=N“的最大的N是多少?
要求:
1.贴出代码图片,写出解题思路,列出测试数据(5分)
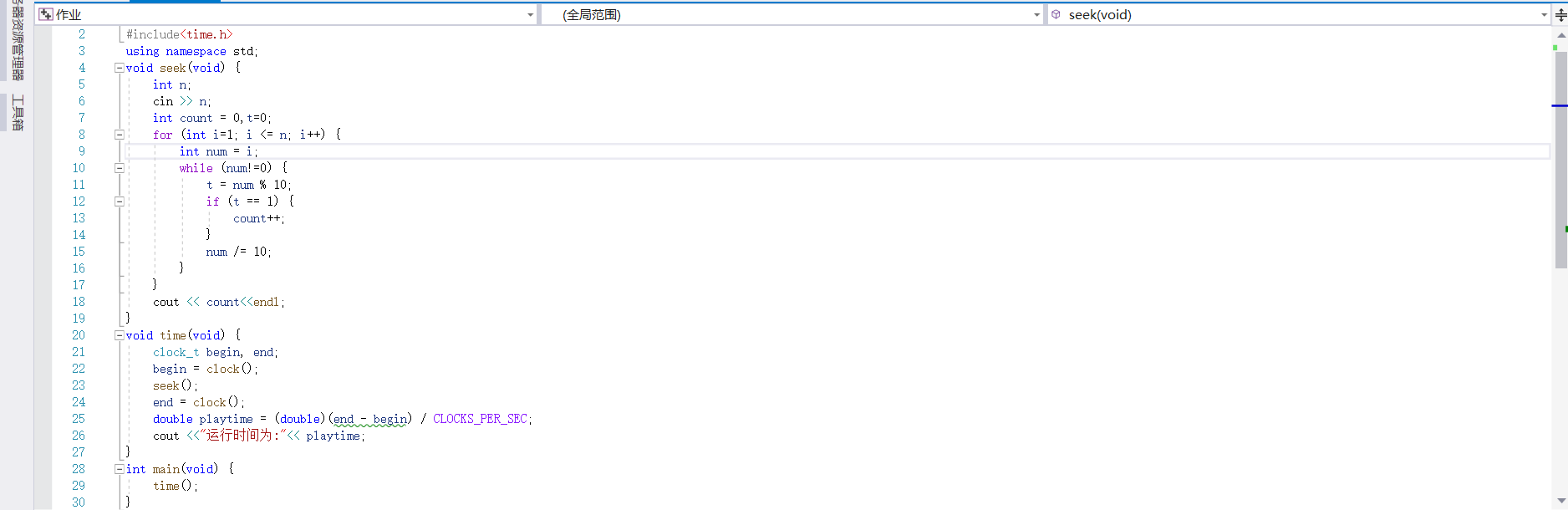
解题思路:通过1到n的循环逐次判断并累加count变量
| 测试数据 | 结果 |
|---|---|
| 12 | 5 |
| 3594 | 2120 |
| 9999 | 4000 |
| 2.给出不同测试数据的运算时间,如果你的运算时间不变,说明你的测试数据不够大(5分) | |
 |
|
 |
|
 |
|
| 2.2 将上题中多组测试数据写入文件,并给出测试程序以检测你的代码有没有问题,贴出你的代码、运行结果和文件内容。(5分) | |
 |
|
 |
2.3 用自己的语言回答两个问题,并给出所查阅资料的引用(10分)
1.什么是文件缓冲系统?工作原理如何?
1.指针对原件进行管理和访问以减少对磁盘的实际读写次数.
2.系统会自动的在内存区为每一个正在使用的文件开辟一块缓冲区。从此盘向内存读数据时,则一次将一些数据从磁盘文件送内存缓冲区(充满缓冲区),然后再从缓冲区逐个将数送给接收变量(文件描述
符);从内存写数据到磁盘文件时,现将数据塞满缓冲区,在一次性将数据从缓冲区送到磁盘文件
2.什么是文本文件和二进制文件?
1.文本文件是一种计算机文件,将键入的文档存储为一系列字母和数字字符,通常没有可视化的格式化信息。直接翻译成人类可读的文本。
2.二进制文件是由一批同一类型的数据组成的一个数据序列,就是说一个具体的二进制文件只能存放同一种类型的数据。由计算机直接解释。
2.4 请给出本周学习总结(15分)
1 学习进度条(5分)
| 周/日期 | 时间 | 代码行数 | 学习内容 | 疑惑 |
|---|---|---|---|---|
| 1/3.3 | 20 | 200 | 文件 数据结构 | 文件 数据结构 |
| 2 累积代码行和博客字数(5分) | ||||
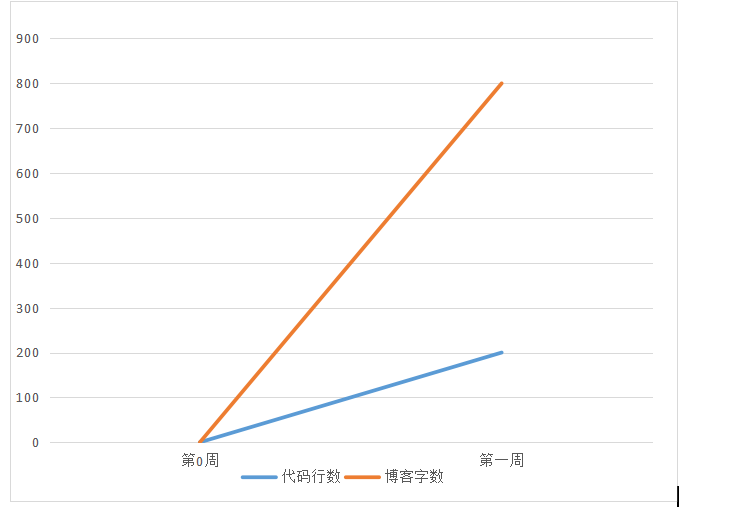 |
3 学习内容总结和感悟(5分)
数据结构的学习需要耗费大量的时间 并多次实践 在算法的学习上要更家巩固基础
思考针对足够大的数据,如何减少运算时间,并给出在原有算法基础上的改进算法和改进思路。(10分)
思路:当数据非常大的时候,利用for循环进行枚举判断的暴力解法会让时间复杂度变得非常大 所以列举多个数字欲模拟程序以找出数学规律顺序
例如将1-100当中的含有1的数字列举出来
1 10 11(11含有两个1) 12 13 14 15 16 17 18 19 21 31 41 51 61 71 81 91 100 共计21个1
按照个位十位百位划分
个位中有1的数字: 1 11 21 31 41 51 61 71 81 91
十位中有1的数字: 10 11 12 13 14 15 16 17 18 19
百位中有1的数字: 100
则猜测若列举 1-1000的数字
1-10中 个位数中 1出现1次
1-100中 十位数中 1出现10次
1-1000中 百位数中 1出现100次
如 列举1234
个位满十进十 每1-10中 个位数中 1出现1次 从1-1230包含123个10 则1出现123次 又个位上的4>1 则包含有一个个位上的1 共123+1=124次
十位满十进百 每1-100中 十位数中 1出现10次 从1-1200中出现12个100 则1出现120次 十位上3>1 则包含有一个十位上的(10-19)10个1 共130次
百位满十进前 每1-1000中 百位数中 1出现100次 从1-1000中共1一个1000 则1又出现100次 百位上2>1 则包含一个百位数上的(100-200)100个1 共200次
千位上 没有更高位数 1=1,所以1000-1234所有的千位都含有1 共出现235个(1000也包含1)
共689个1
例举 5678
个:567+1=568
十:560+10=570
百:500+100=600
千:1000
共2738


总结规律得到
以1234为例
右数第i个数字与1比较 若i>1 则以(i左边的数字)+ 10的(i-1)次方 若i=1则以(左边的的数字)+(右边的数字)+1
以此数学规律为思路 优化算法并实现代码
#include<iostream>
#include<time.h>
#include<stdio.h>
#include<math.h>
using namespace std;
int seek(int n) {
int a[100] = { 0 };
int p = n, count = 0;;
while (p != 0) {
a[count] = (p % 10);
p /= 10;
count++;
}
int i = 0;
int sum=0;
while (count != 0) {
int l = (n / pow(10, i + 1));
l = l *pow(10, i);
if (a[i] > 1) {
sum +=l+pow(10,i);
}
if (a[i] == 1) {
if (count == 1) {
sum += 0 + (n - a[i] * pow(10, 3)) + 1;
}
else {
sum += l + (n - l * 10) + 1;
}
}
i++;
count--;
}
cout << sum<<endl;
return 0;
}
int main(void) {
int n;
clock_t begin, end;
begin = clock();
cin >> n;
seek(n);
end = clock();
double time = (double)(end - begin) / CLOCKS_PER_SEC;
cout << "time =" << time << "s" << endl;
return 0;
}
然后数值过大导致pow的指数过高 超过了int类型 数值太小i和count又导致数组越界 放弃这种思路了
因为个位十位百位等等的拆分 联想到了汉诺塔的递归 可以归结为两种 1.个位和其他位置
1出现的次数为 (个位1出现次数)+(十位1出现次数)+(百位1出现次数)qishi
其实和上面的思路有大部分相同 只是把分割换成了逐位(个十百)
#include<iostream>
#include<time.h>
#include<stdio.h>
#include<math.h>
using namespace std;
void seek(int n) {
int count = 0;
int base = 1;
int round = n;
while (round > 0) {
int weight = round % 10;
round /= 10;
count += round * base;
if (weight == 1)
count += (n % base) + 1;
else if (weight > 1)
count += base;
base *= 10;
}
cout << count<<endl;
}
int main(void) {
int n;
clock_t begin, end;
begin = clock();
cin >> n;
seek(n);
end = clock();
double time = (double)(end - begin) / CLOCKS_PER_SEC;
cout << "time =" << time << "s" << endl;
return 0;
}
最大N
根据题目要求 正整数N 所以利用while控制循环条件为0-2147483647进行循环



最大N:1111111110